Sujet à couvrir
- Qu'est-ce que l'analyse de données exploratoire?
- Quel est le besoin d'automatiser l'analyse exploratoire des données?
- Bibliothèques Python pour automatiser l'analyse exploratoire des données
L'analyse exploratoire des données
est une technique d'exploration de données pour comprendre divers aspects des données. Il est une sorte de résumé des données. C'est l'une des étapes les plus importantes avant d'effectuer toute tâche d'apprentissage automatique ou d'apprentissage en profondeur..
Les scientifiques des données effectuent des procédures d'analyse exploratoire des données pour explorer, disséquer et résumer les qualités fondamentales des ensembles de données, en utilisant régulièrement des approches de représentation de l'information. Les procédures EDA prennent en compte le contrôle convaincant des sources d'information, permettre aux scientifiques des données de découvrir les bonnes réponses dont ils ont besoin pour trouver des conceptions d'information, détecter les incohérences, vérifier les hypothèses ou tester les spéculations.
Les data scientists utilisent l'analyse exploratoire des données pour voir quels ensembles de données ils peuvent découvrir au-delà de l'affichage conventionnel des informations ou des devoirs de test de spéculation. Cela leur permet d'acquérir des informations de haut en bas sur les facteurs des ensembles de données et leurs connexions.. L'analyse exploratoire des données peut aider à reconnaître des erreurs claires, distinguer les exceptions dans les ensembles de données, obtenir des connexions, découvrir des éléments significatifs, découvrir les designs d'initiés et fournir de nouvelles idées.
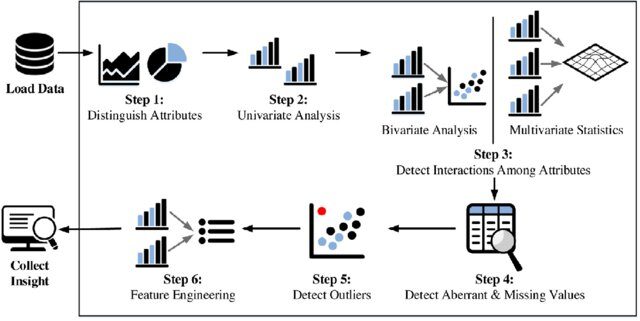
Étapes de l'analyse exploratoire des données
Besoin d'automatiser l'analyse exploratoire des données
Le mouvement élargi des clients sur le web, les outils raffinés pour contrôler le trafic Web, la multiplication des téléphones portables, les appareils connectés au Web et les capteurs IoT sont les éléments essentiels qui accélèrent le rythme de l'ère de l'information d'aujourd'hui. A l'ère de l'informatique, les associations de toutes tailles comprennent que l'information peut jouer un rôle crucial dans l'amélioration de leurs compétences, rentabilité et dynamisme des compétences, qui génère de plus grands accords, revenus et avantages.
Aujourd'hui, la plupart des organisations abordent d'énormes ensembles de données, cependant, le simple fait d'avoir de grandes quantités d'informations n'améliore pas les affaires, sauf si les entreprises recherchent des données accessibles et poussent pour un développement autorisé.

Dans le cycle de vie d'un projet de science des données ou de tout projet de machine learning, plus que 60% de ton temps entrer dans des choses comme l'analyse de données, sélection de fonctionnalité, ingénierie des fonctionnalités, etc. Parce que c'est la partie la plus importante ou l'épine dorsale d'un projet de science des données, c'est cette partie particulière où vous devez faire beaucoup d'activités comme nettoyer les données, gérer les valeurs manquantes , gérer les valeurs aberrantes, gérer des ensembles de données déséquilibrés, comment gérer les caractéristiques catégorielles et bien plus encore. Alors si tu veux économisez votre temps dans l'analyse exploratoire des données, nous pouvons utiliser des bibliothèques Python comme date, profil de pandas, sweetviz et autoviz automatiser nos tâches.

Les bibliothèques automatisent l'analyse exploratoire des données
Dans ce blog, nous avons discuté de quatre bibliothèques Python importantes. Ceux-ci sont énumérés ci-dessous:
- histoire
- profil de pandas
- sweetviz
- autoviz
D-conte
C'est une bibliothèque qui a été lancée en février 2020 ce qui nous permet de visualiser facilement la trame de données des pandas. Il possède de nombreuses fonctionnalités très utiles pour l'analyse exploratoire des données. Il est fabriqué à l'aide du backend du flacon et réagit au frontend. Prend en charge les graphiques interactifs, Graphiques 3D, cartes thermiques, la corrélation entre les caractéristiques, créer des colonnes personnalisées et bien d'autres. Il est le plus célèbre et le préféré de tous.
Installation
dtale peut être installé en utilisant le code suivant:
pip install dtale
Analyse exploratoire des données avec D-tale
Approfondissons l'analyse exploratoire des données à l'aide de cette bibliothèque. Premier, nous devons écrire un code pour lancer l'application interactive d-tale localement:
importer des données
importer des pandas au format pd
df = pd.read_csv('données.csv')
d = dtale.show(df)
d.open_browser()
Ici, nous importons des pandas et lui donnons. Nous lisons l'ensemble de données à l'aide de la fonction read_csv () et enfin nous affichons les données dans le navigateur localement en utilisant la fonction show et ouvrons le navigateur.
Afficher les données de la même manière que les pandas, mais il a une fonctionnalité supplémentaire, il a un menu dans le coin supérieur gauche qui nous permet de faire beaucoup de choses et affiche un nombre de colonnes et de lignes dans notre ensemble de données.
La sortie du code ci-dessus est affichée ci-dessous:
Si vous cliquez sur un en-tête de colonne, le menu déroulant apparaîtra. Cela vous donnera de nombreuses options, comment trier les données, décrire l'ensemble de données, analyse de colonne et bien d'autres. Vous pouvez également vérifier cette fonction par vous-même
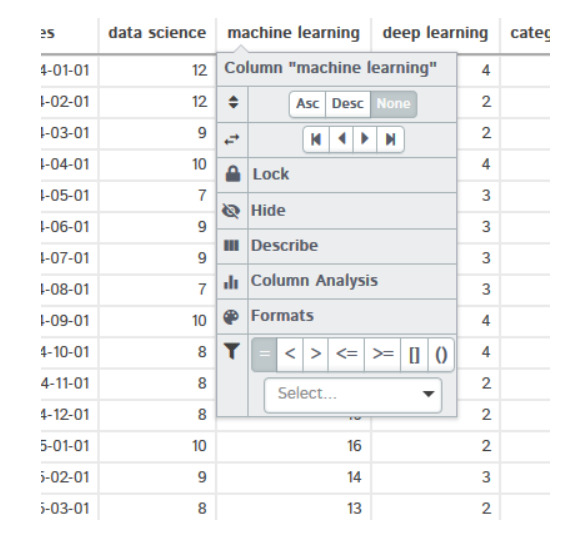
Si vous cliquez sur Décrire, montre l'analyse statistique de la colonne sélectionnée comme moyenne, médian, maximum, écart minimal, écart-type, quartiles et bien d'autres.
De la même manière, vous pouvez essayer d'autres fonctions par vous-même, comme analyse de colonne, formats, filtres.
Magie du conte: cliquez sur le bouton menu et vous trouverez toutes les options disponibles
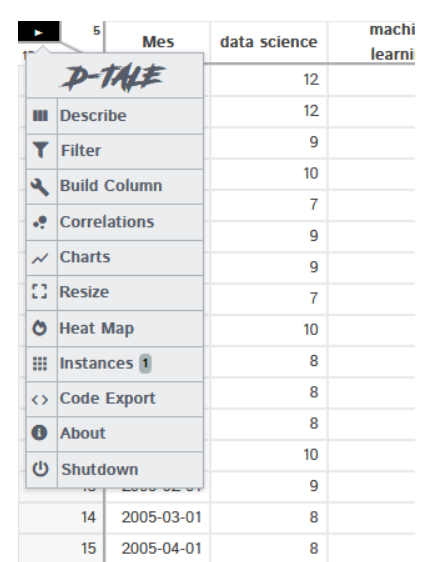
Toutes les fonctionnalités ne peuvent pas être couvertes, mais je couvre le plus intéressant.
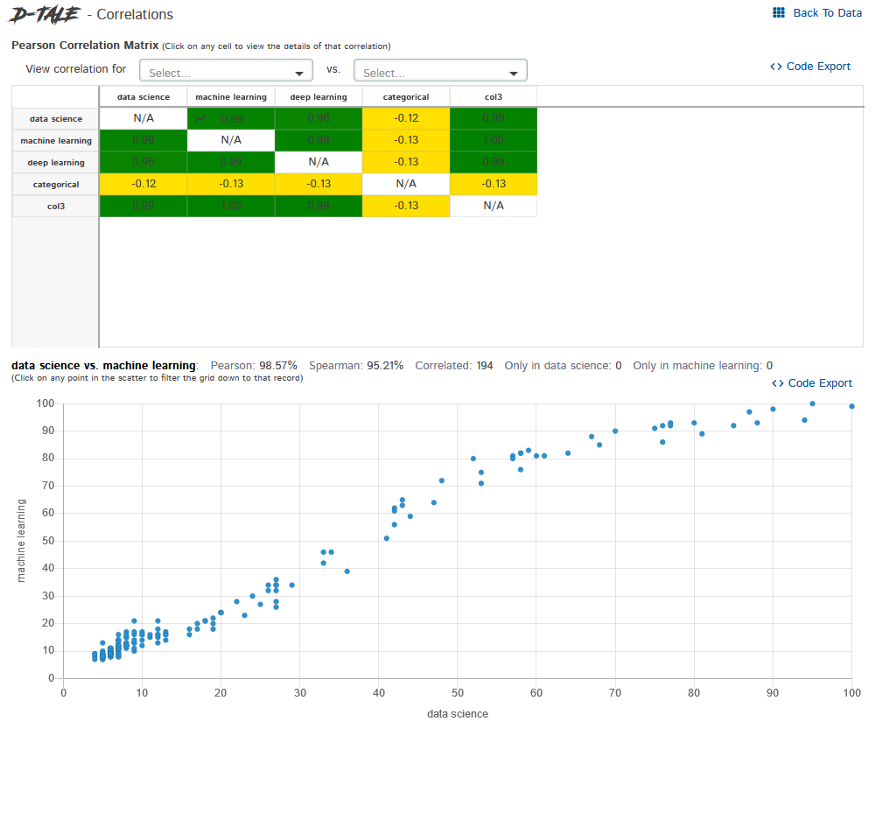
Corrélations – Il nous montre comment les colonnes sont corrélées les unes aux autres.
Graphique– Créer des graphiques personnalisés sous forme de graphiques linéaires, graphiques à barres, camemberts, graphiques empilés, diagrammes de dispersion, cartes géologiques, etc.
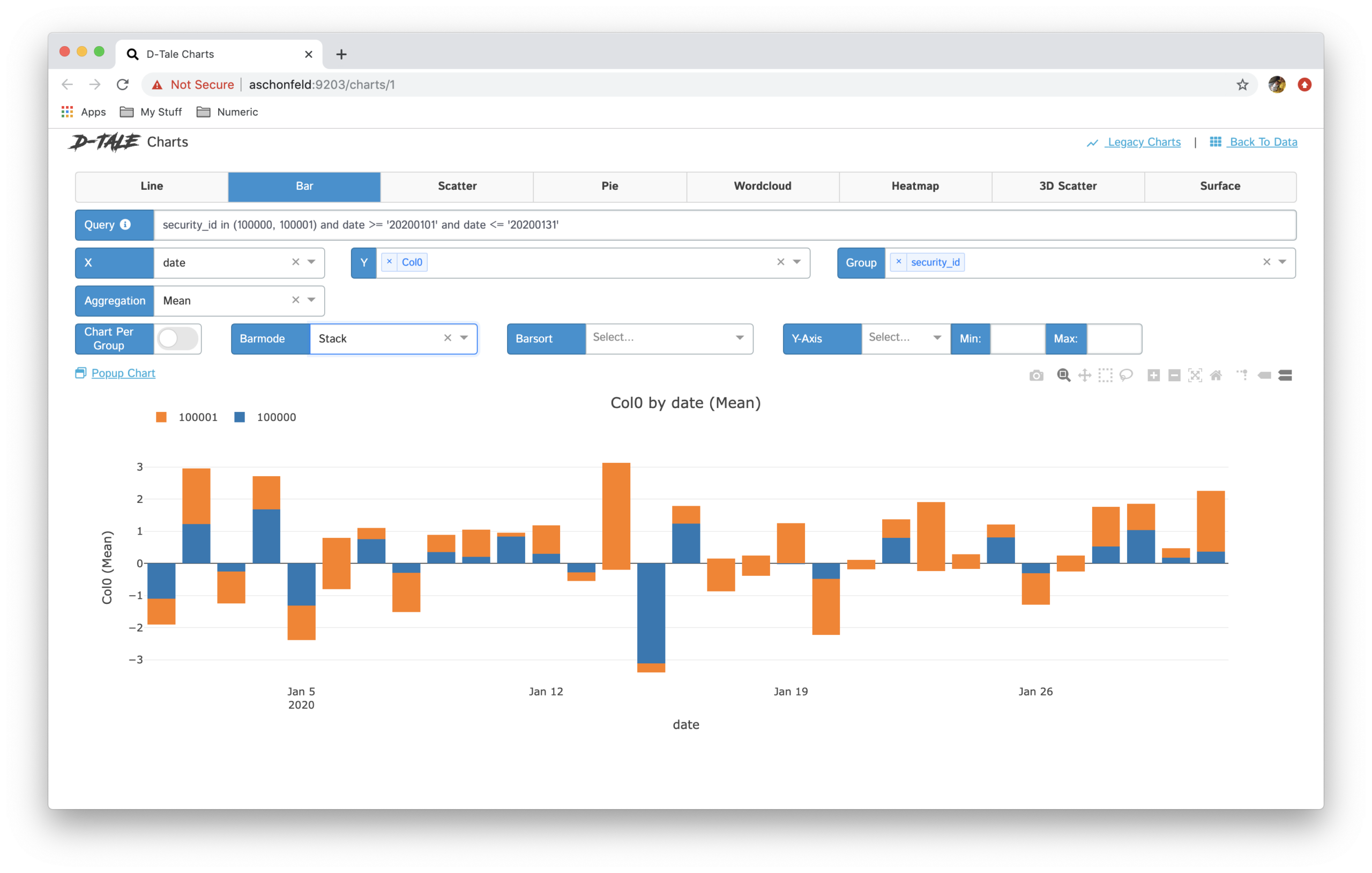
Il existe de nombreuses options disponibles dans cette bibliothèque pour l'analyse des données. Cet outil est très utile et rend l'analyse de données exploratoire beaucoup plus rapide par rapport à l'utilisation de bibliothèques d'apprentissage automatique traditionnelles comme les pandas, matplotlib, etc.
Pour obtenir des documents officiels, regarde ce lien:
Profilage des pandas

Il s'agit d'une bibliothèque open source écrite en Python et générée des rapports HTML interactifs et décrit divers aspects de l'ensemble de données. Les fonctionnalités clés incluent la gestion des valeurs manquantes, statistiques d'ensemble de données en tant que moyenne, mode, médian, asymétrie, écart-type, etc., des graphiques tels que des histogrammes et des corrélations ainsi.
Installation
Le profilage Pandas peut être installé à l'aide du code suivant:
pip installer pandas-profilage
Analyse exploratoire des données à l'aide du profilage Pandas
Approfondissons l'analyse exploratoire des données à l'aide de cette bibliothèque. J'utilise un exemple d'ensemble de données pour commencer avec le profilage des pandas, vérifier le code suivant:
#importation des packages requis
importer des pandas au format pd
importer pandas_profiling
importer numpy en tant que np
#importation des données
df = pd.read_csv('exemple.csv')
#statistiques descriptives
pandas_profiling.ProfileReport(df)
Ci-dessous se trouve la sortie magique du code ci-dessus
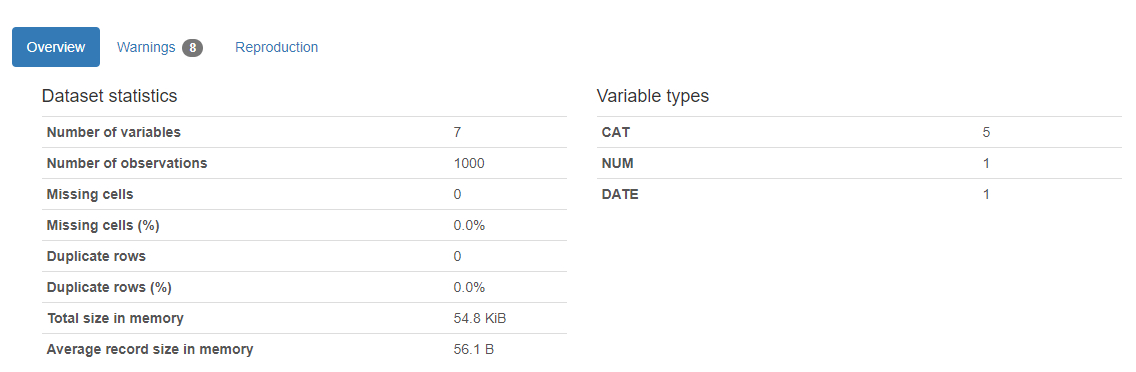
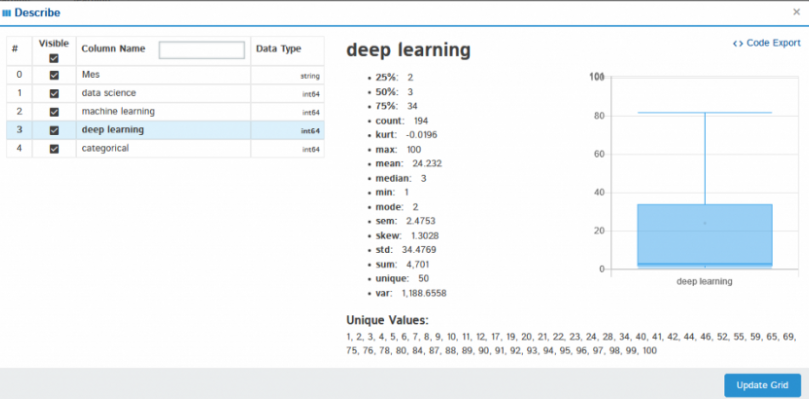
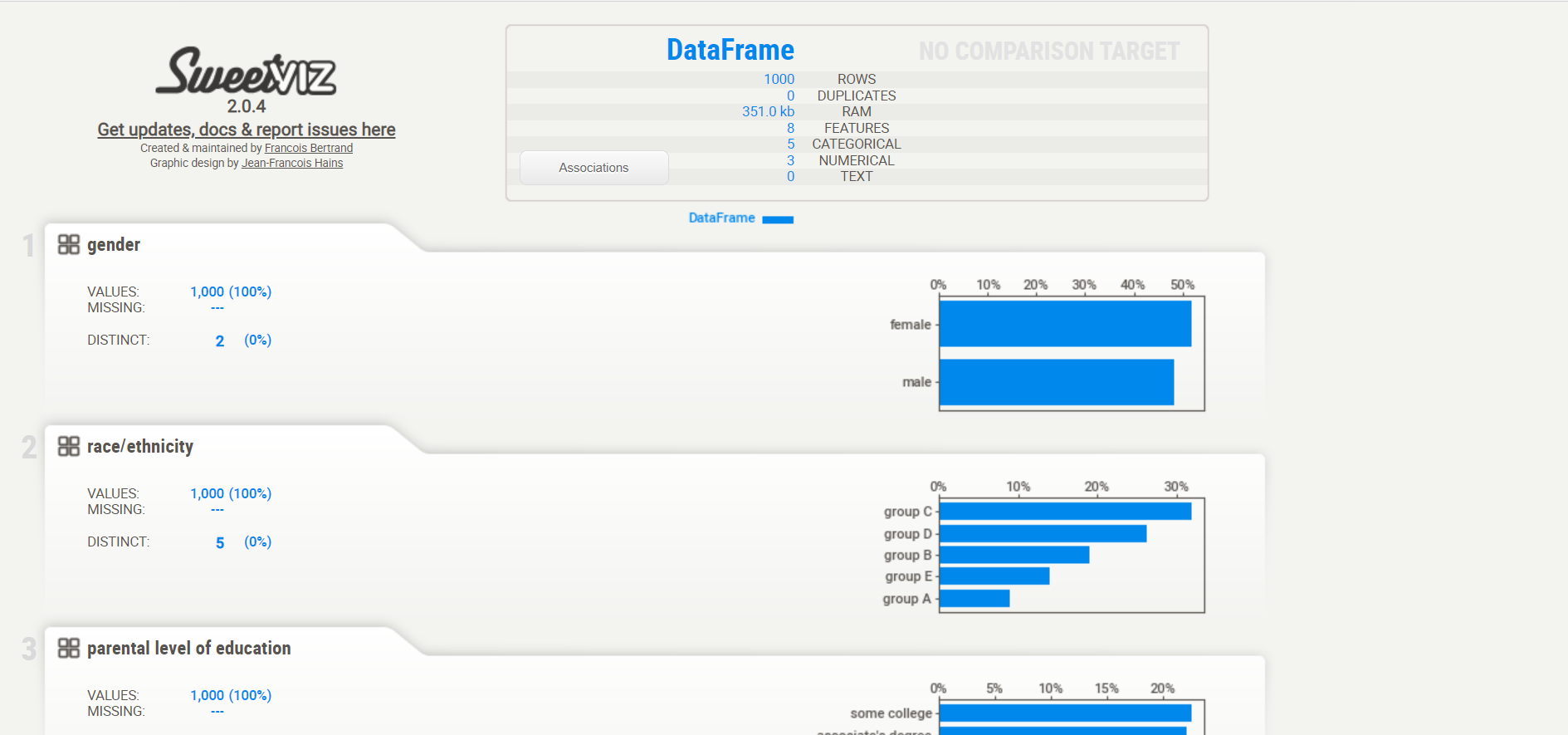
Voici le résultat. Un rapport apparaîtra et retournera le nombre de variables dans notre ensemble de données, le nombre de lignes, les cellules manquantes dans l'ensemble de données, le pourcentage de cellules manquantes, le nombre et le pourcentage de lignes en double. Les données de cellules manquantes et en double sont très importantes pour notre analyse, car ils décrivent l'image plus large de l'ensemble de données. Le rapport indique également la taille totale de la mémoire. Il montre également les types de variables sur le côté droit de la sortie.
La section des variables montre l'analyse d'une colonne particulière. Par exemple pour le variable catégorielle, la sortie suivante apparaîtra.
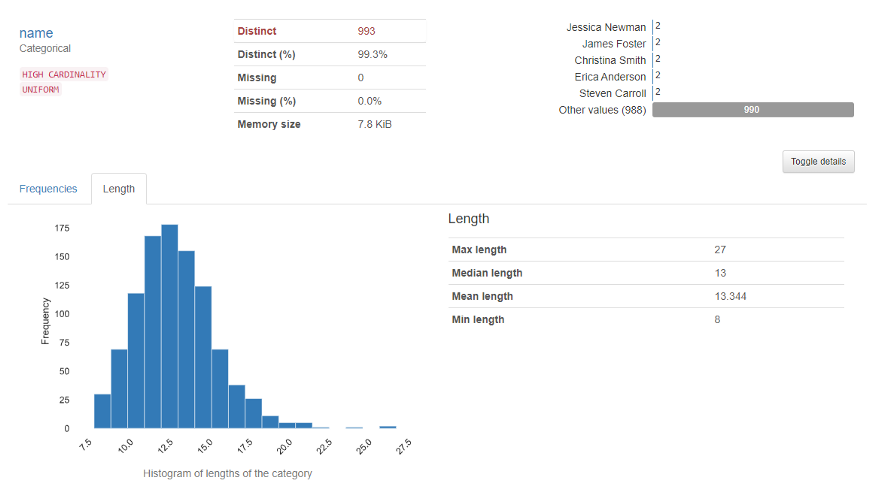
Pour lui variable numérique, la sortie suivante apparaîtra
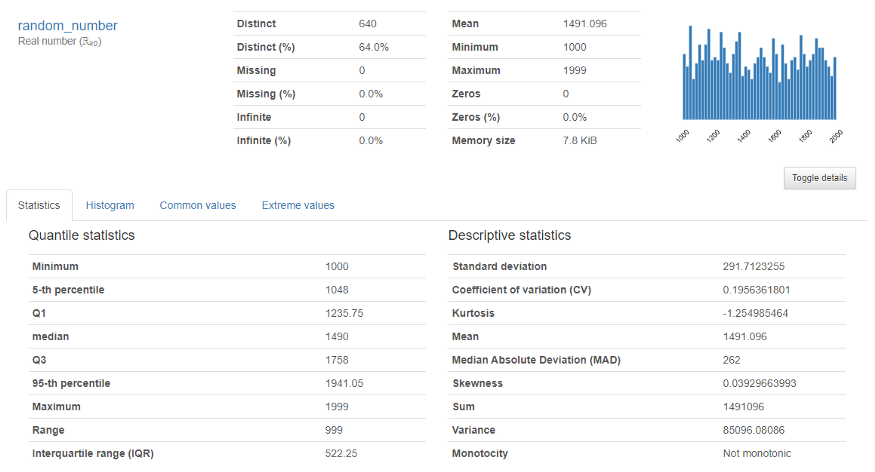
Fournit une analyse approfondie des variables numériques sous forme de quantile, médias, somme médiane, variance, monotonie, rang, curtose, intervalle interquartile et bien d'autres.
Corrélations et interactions: Décrire comment les variables sont corrélées entre elles en utilisant. Ces données sont indispensables aux data scientists.
Pour plus d'informations, consulter la documentation officielle:
Sweetviz
C'est une bibliothèque Python open source qui permet d'obtenir des visualisations, ce qui est utile dans l'analyse exploratoire des données avec seulement quelques lignes de code. La bibliothèque peut être utilisée pour visualiser les variables et comparer l'ensemble de données.
Installation
Cette bibliothèque peut être installée en utilisant le code suivant:
pip installer sweetviz
Analyse exploratoire des données avec SweetViz
Approfondissons l'analyse exploratoire des données à l'aide de cette bibliothèque. J'utilise un exemple de jeu de données pour commencer, vérifier le code suivant
importer sweetviz
importer des pandas au format pd
df = pd.read_csv('exemple.csv')
mon_rapport = sweetviz.analyze([df,'Former'], target_feat="Prix de vente")
mon_rapport.show_html('FinalReport.html')
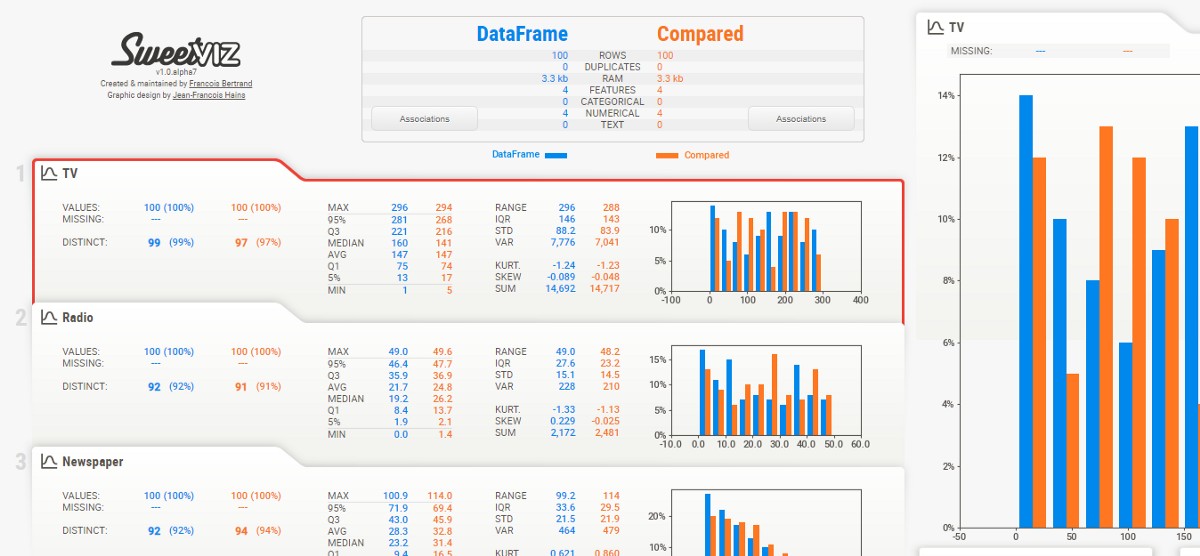
Rapport final:
Pour plus d'informations, consulter la documentation officielle:
Autoviz
Signifie afficher automatiquement. La visualisation est possible avec n'importe quelle taille de l'ensemble de données avec quelques lignes de code.

Installation
pip installer autoviz
Afficher
Exemple de code:
depuis autoviz.AutoViz_Class importer AutoViz_Class
AV = Classe_AutoViz()
df = AV.AutoViz('exemple.csv')
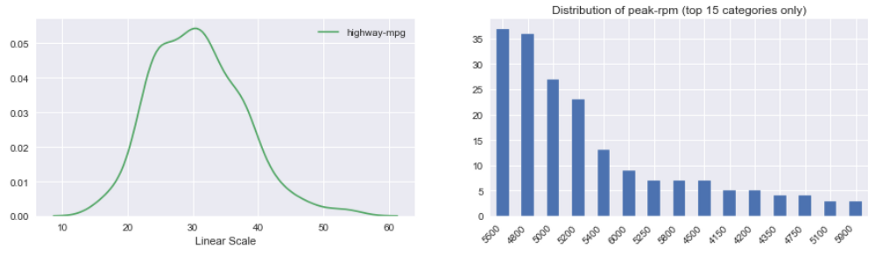
Histogramme de variable continue:
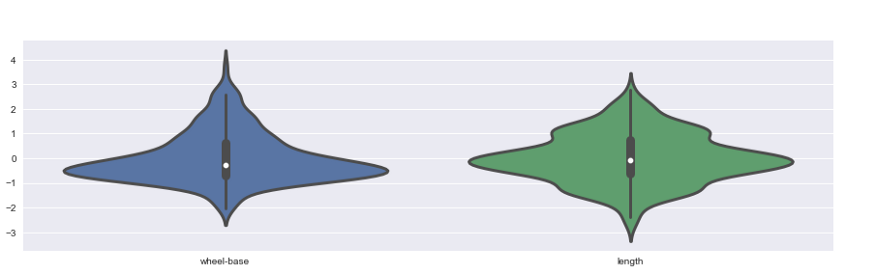
Cadres de violon:
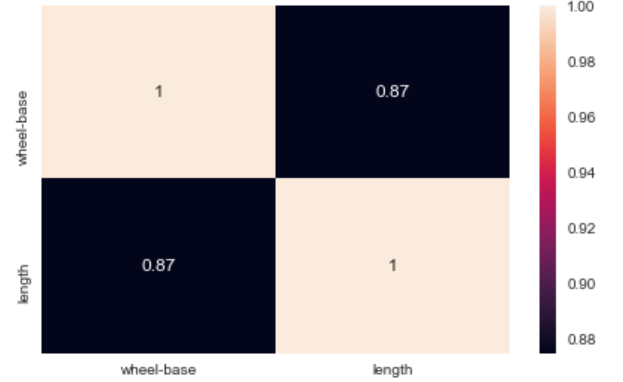
Carte de chaleur:
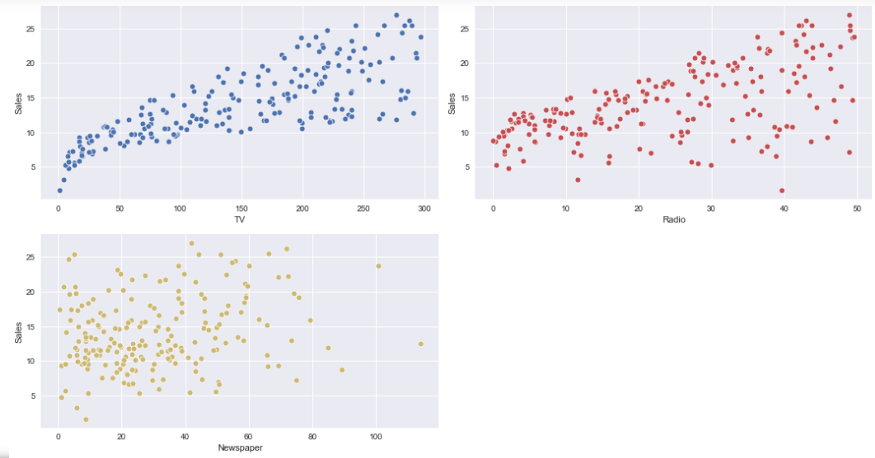
Nuage de points:
Pour plus d'informations, consulter la documentation officielle:
Merci d'avoir lu ceci. Si vous aimez cet article, Partage-le avec tes amis. En cas de suggestion / doute, commentaires ci-dessous.
Identification de l'e-mail: [email protégé]
Suivez-moi sur LinkedIn: LinkedIn
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





