Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
Chaque fois que nous créons un modèle d'apprentissage automatique, nous l'alimentons avec des données initiales pour entraîner le modèle. Et puis nous introduisons des données inconnues (données de test) pour comprendre les performances du modèle et généraliser sur des données invisibles. Si le modèle fonctionne bien sur des données invisibles, est cohérent et peut prédire avec une bonne précision sur un large éventail de données d'entrée; donc ce modèle est stable.
Mais ce n'est pas toujours le cas !! Les modèles d'apprentissage automatique ne sont pas toujours stables et nous devons évaluer la stabilité du modèle d'apprentissage automatique. C'est là qu'intervient la validation croisée..
« En termes simples, la validation croisée est une technique utilisée pour évaluer les performances de nos modèles d'apprentissage automatique sur des données invisibles »
D'après Wikipédia, la validation croisée est le processus d'évaluation de la façon dont les résultats d'une analyse statistique se généraliseront à un ensemble de données indépendant.
Il existe de nombreuses façons de faire une validation croisée et nous allons en apprendre davantage sur 4 méthodes dans cet article.
Comprenons d'abord la nécessité d'une validation croisée !!
Pourquoi avons-nous besoin d'une validation croisée?

Supposons que vous créiez un modèle d'apprentissage automatique pour résoudre un problème et que vous ayez entraîné le modèle sur un ensemble de données donné. Cuando verifica la precisión del modelo en los datos de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines...., c'est près de 95%. Cela signifie-t-il que votre modèle a été très bien entraîné et qu'il est le meilleur modèle en raison de la haute précision?
Non, ce n'est pas! Parce que votre modèle est entraîné avec les données fournies, connaît bien les données, capture même les plus petites variations (bruit) et il a été très bien généralisé sur les données fournies. Si vous exposez le modèle à des données complètement nouvelles et invisibles, peut ne pas prédire aussi précisément et peut ne pas généraliser à de nouvelles données. Ce problème est appelé surapprentissage..
Parfois, le modèle ne s'entraîne pas bien dans l'ensemble d'entraînement car il ne peut pas trouver de modèles. Dans ce cas, cela ne fonctionnerait pas bien sur le banc d'essai non plus. Ce problème est appelé ajustement insuffisant.
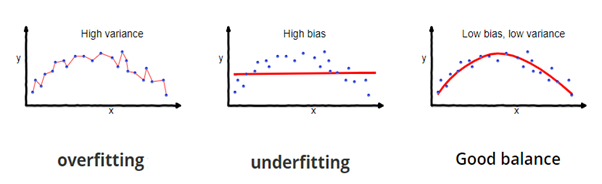
Source de l'image: fireblazeaischool.in
Pour surmonter les problèmes de surapprentissage, nous utilisons une technique appelée validation croisée.
Validation croisée est une technique de rééchantillonnage avec l'idée fondamentale de diviser l'ensemble de données en 2 les pièces: données d'entraînement et données de test. Les données d'entraînement sont utilisées pour entraîner le modèle et les données de test invisibles sont utilisées pour la prédiction. Si le modèle fonctionne bien sur les données de test et offre une bonne précision, signifie que le modèle n'a pas surajusté les données d'entraînement et peut être utilisé pour la prédiction.
Plongeons-nous et découvrons certaines des techniques d'évaluation de modèle.
1. Méthode d'attente
C'est la méthode d'évaluation la plus simple et elle est largement utilisée dans les projets d'apprentissage automatique.. Ici, l'ensemble de données complet (Ville) se divise en 2 ensembles: ensemble de train et ensemble d'essai. Les données peuvent être divisées en 70-30 O 60-40, 75-25 O 80-20, ou 50-50 selon le cas d'utilisation. En règle générale, la proportion de données d'entraînement doit être supérieure aux données de test.
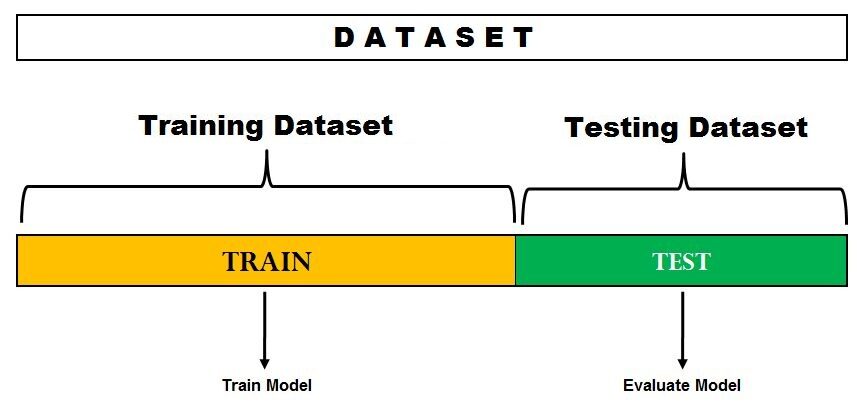
Source de l'image: DonnéesVedas
La division des données se produit de manière aléatoire et nous ne pouvons pas être sûrs des données qui se retrouvent dans le train et dans l'entrepôt de test pendant la division, sauf si nous spécifions random_state. Cela peut conduire à une variance extrêmement élevée et chaque fois que la division change, la précision changera aussi.
Cette méthode a quelques inconvénients:
- Dans la méthode Hold out, les taux d'erreur de test sont très variables (écart élevé) et cela dépend totalement des observations qui se retrouvent dans l'ensemble d'apprentissage et l'ensemble de test.
- Seule une partie des données est utilisée pour entraîner le modèle (biais élevé) ce qui n'est pas une très bonne idée lorsque les données ne sont pas volumineuses et cela conduira à une surestimation de l'erreur de test.
L'un des principaux avantages de cette méthode est qu'elle est peu coûteuse en termes de calcul par rapport à d'autres techniques de validation croisée..
Implémentation rapide de la méthode Hold Out en Python
de sklearn.model_selection importer train_test_split
X = [10,20,30,40,50,60,70,80,90,100]
former, test = train_test_split (X, taille_test = 0.3, état_aléatoire = 1)
imprimer (« Former: », X_train, « Test: », X_test)
Sortir
Former: [50, 10, 40, 20, 80, 90, 60] Test: [30, 100, 70]
Ici, état_aléatoire est la graine utilisée pour la reproductibilité.
2. Laisser un hors validation croisée
Dans cette méthode, nous divisons les données en ensembles de test et d'apprentissage, mais avec une torsion. Au lieu de diviser les données en 2 sous-ensembles, nous sélectionnons une seule observation comme données de test, et tout le reste est étiqueté en tant que données d'entraînement et le modèle est entraîné. Maintenant, la deuxième observation est sélectionnée comme données de test et le modèle est entraîné avec les données restantes.
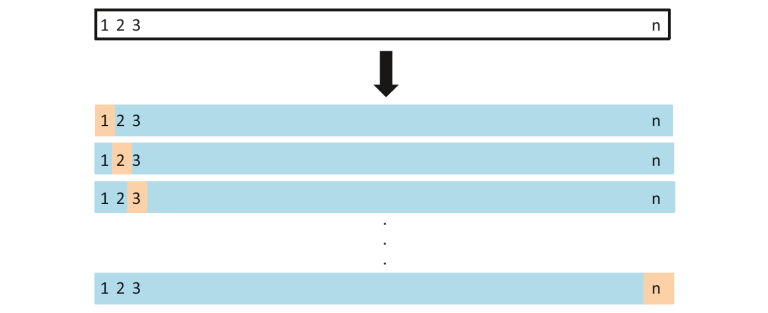
Source de l'image: ISLR
Este proceso continúa ‘m’ fois et la moyenne de toutes ces itérations est calculée et estimée comme l'erreur de l'ensemble de test.
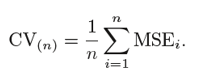
En ce qui concerne les estimations des erreurs de test, LOOCV fournit des estimations impartiales (faible biais). Mais le biais n'est pas la seule préoccupation dans les problèmes d'estimation. Il faut aussi considérer la variance.
LOOCV a un écart élevé parce que nous faisons la moyenne de la sortie de n-modèles qui correspondent à un ensemble d'observations presque identique, et leurs sorties sont très positivement corrélées les unes aux autres.
Y puede ver claramente que esto es computacionalmente costoso ya que el modelo se ejecuta ‘m’ fois pour tester chaque observation sur les données. Notre prochaine méthode abordera ce problème et nous donnera un bon équilibre entre biais et variance..
Implémentation rapide de la validation croisée Leave One Out en Python
à partir de sklearn.model_selection importer LeaveOneOut
X = [10,20,30,40,50,60,70,80,90,100]
l = LeaveOneOut()
pour le train, test en l.split(X):
imprimer("%%s"% (former,test))
Sortir
[1 2 3 4 5 6 7 8 9] [0] [0 2 3 4 5 6 7 8 9] [1] [0 1 3 4 5 6 7 8 9] [2] [0 1 2 4 5 6 7 8 9] [3] [0 1 2 3 5 6 7 8 9] [4] [0 1 2 3 4 6 7 8 9] [5] [0 1 2 3 4 5 7 8 9] [6] [0 1 2 3 4 5 6 8 9] [7] [0 1 2 3 4 5 6 7 9] [8] [0 1 2 3 4 5 6 7 8] [9]
Cette sortie montre clairement comment LOOCV garde une observation de côté car les données de test et toutes les autres observations vont aux données du train.
3. Validation croisée du K-Fold
Dans cette technique de rééchantillonnage, toutes les données sont divisées en k ensembles de tailles presque égales. Le premier ensemble est sélectionné comme ensemble de test et le modèle est entraîné sur les ensembles k-1 restants. Le taux d'erreur de test est calculé après ajustement du modèle aux données de test.
Dans la deuxième itération, le deuxième ensemble est sélectionné comme ensemble de test et les k-1 ensembles restants sont utilisés pour entraîner les données et l'erreur est calculée. Ce processus se poursuit pour tous les ensembles k.
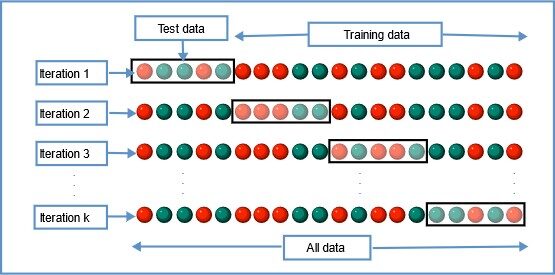
Source de l'image: Wikipédia
La moyenne des erreurs de toutes les itérations est calculée comme l'estimation de l'erreur de test CV.
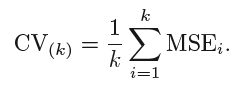
Un CV K-Fold, le nombre de plis k est inférieur au nombre d'observations dans les données (k <m) et nous faisons la moyenne des sorties de k modèles ajustés qui sont un peu moins corrélés les uns aux autres car le chevauchement entre les ensembles d'apprentissage dans chaque modèle est plus petit. Cela mène à faible écart puis LOOCV.
La meilleure partie de cette méthode est que chaque point de données est dans l'ensemble de test exactement une fois et fait partie de l'ensemble d'apprentissage k-1 fois.. UNE mesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... que aumenta el número de pliegues k, l'écart diminue également (faible écart). Cette méthode conduit à biais intermédiaire parce que chaque ensemble d'apprentissage contient moins d'observations (k-1) m / k que la méthode Leave One Out mais plus que la méthode Hold Out.
Comme d'habitude, La validation croisée K fois est effectuée en utilisant k = 5 o k = 10, car il a été démontré empiriquement que ces valeurs produisent des estimations des erreurs de test qui ne sont ni biaisées ni variances élevées.
Le principal inconvénient de cette méthode est que le modèle doit être exécuté à partir de zéro k fois et qu'il est coûteux en calculs que la méthode Hold Out., mais mieux que la méthode Leave One Out.
Implémentation simple de la validation croisée K-Fold en Python
à partir de sklearn.model_selection importer KFold
X = ["une",'b','c','ré','e','F']
kf = KFold(n_splits=3, shuffle=Faux, random_state=Aucun)
pour le train, tester dans kf.split(X):
imprimer("Données de train",former,"Données de test",test)
Sortir
Former: [2 3 4 5] Test: [0 1] Former: [0 1 4 5] Test: [2 3] Former: [0 1 2 3] Test: [4 5]
4. Validation croisée stratifiée du K-Fold
Ceci est une légère variation de la validation croisée K-Fold, Qu'est ce que tu utilises ‘muestreo estratificado’ au lieu de « échantillonnage aléatoire ».
Comprenons rapidement ce qu'est l'échantillonnage stratifié et en quoi il diffère de l'échantillonnage aléatoire.
Supposons que vos données contiennent des critiques d'un produit cosmétique utilisé par la population masculine et féminine. Lorsque nous effectuons un échantillonnage aléatoire pour diviser les données en ensembles de tests et en trains, il est possible que la plupart des données représentant les hommes ne soient pas représentées dans les données d'entraînement, mais ils pourraient se retrouver dans les données de test. Lorsque nous entraînons le modèle avec des exemples de données d'entraînement qui ne sont pas une représentation correcte de la population réelle, le modèle ne prédit pas les données de test avec une bonne précision.
C'est là que l'échantillonnage stratifié vient à la rescousse.. Ici, les données sont divisées de manière à représenter toutes les classes de la population..
Prenons l'exemple ci-dessus, qui a un avis sur les produits cosmétiques de 1000 les clients, dont le 60% ce sont des femmes et il 40% ce sont des hommes. Je veux diviser les données en données de test et d'entraînement proportionnellement (80:20). Le 80% des 1000 les clients seront 800 qui sera choisi de telle sorte qu'il y ait 480 critiques associées à la population féminine et 320 représentant la population masculine. de la même manière, les 20% de 1000 les clients seront choisis pour les données de test (avec la même représentation féminine et masculine).
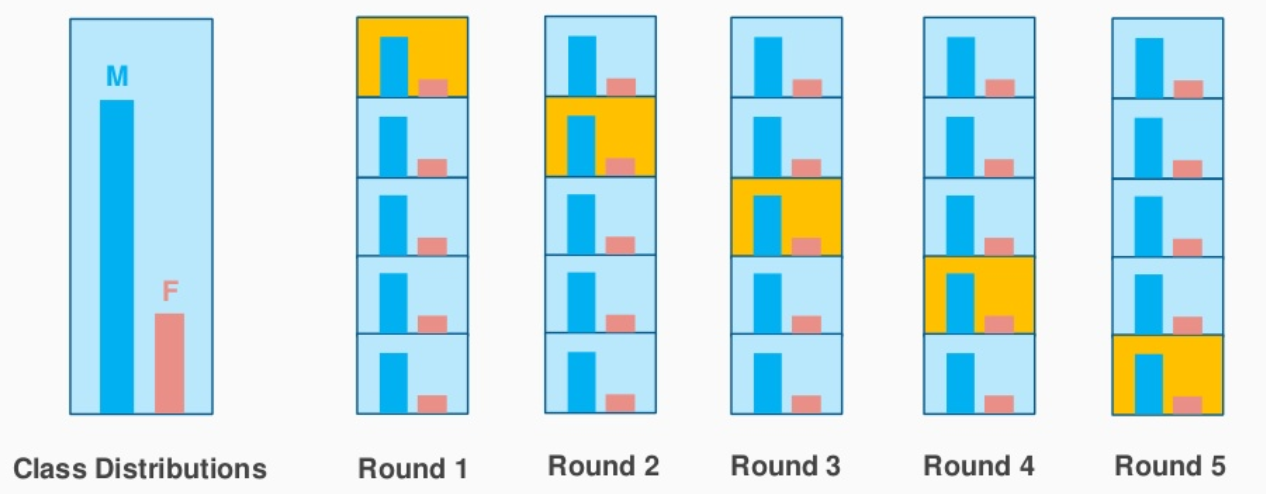
Source de l'image: pileexchange.com
C'est exactement ce que fait le CV stratifié K-Fold et créera des K-Folds en préservant le pourcentage d'échantillon pour chaque classe. Cela résout le problème d'échantillonnage aléatoire associé aux méthodes Hold out et K-Fold..
Implémentation rapide de la validation croisée stratifiée K-Fold en Python
à partir de sklearn.model_selection importer StratifiedKFold
X = np.tableau([[1,2],[3,4],[5,6],[7,8],[9,10],[11,12]])
y = np.tableau([0,0,1,0,1,1])
skf = StratifiéKFold(n_splits=3,random_state=Aucun,shuffle=Faux)
pour train_index,test_index dans skf.split(X,Oui):
imprimer("Former:",index_train,'Test:',index_test)
X_train,X_test = X[index_train], X[index_test]
y_train,y_test = y[index_train], Oui[index_test]
Sortir
Former: [1 3 4 5] Test: [0 2] Former: [0 2 3 5] Test: [1 4] Former: [0 1 2 4] Test: [3 5]
Le résultat montre clairement la division stratifiée faite selon les classes ‘0’ Oui ‘1’ dans ‘Oui’.
Biais – Compensation des écarts
Lorsque l'on considère les estimations du taux d'erreur du test, La validation croisée K-Fold fournit des estimations plus précises que de laisser une validation croisée de côté. Alors que la méthode Hold One Out CV conduit généralement à des surestimations du taux d'erreur de test, car dans cette approche, seule une partie des données est utilisée pour entraîner le modèle d'apprentissage automatique.
Quand il s'agit de biais, la méthode Leave One Out fournit des estimations non biaisées car chaque ensemble d'apprentissage contient n-1 observations (qui est pratiquement toutes les données). Le K-Fold CV conduit à un niveau de biais intermédiaire en fonction du nombre de k-folds par rapport au LOOCV, mais c'est beaucoup moins par rapport à la méthode Hold Out.
Compléter, la technique de validation croisée que nous choisissons dépend fortement du cas d'utilisation et de l'équilibre entre biais et variance.
Si vous avez lu cet article jusqu'à présent, voici un bonus rapide pour vous. ??
sklearn.model_selection a une méthode cross_val_score qui simplifie le processus de validation croisée. En lugar de iterar a través de los datos completos usando la función ‘partager’, on peut utiliser cross_val_score et vérifier le score de précision de la méthode de validation croisée choisie
Vous pouvez vérifier mon Github pour implémentation python de différentes méthodes de validation croisée dans le Kaggle ICU Cancer du sein Faits.
Voici quelques-uns de mes articles sur l'apprentissage automatique.
Inteligencia artificial Vs Aprendizaje automático Vs L'apprentissage en profondeurL'apprentissage en profondeur, Une sous-discipline de l’intelligence artificielle, s’appuie sur des réseaux de neurones artificiels pour analyser et traiter de grands volumes de données. Cette technique permet aux machines d’apprendre des motifs et d’effectuer des tâches complexes, comme la reconnaissance vocale et la vision par ordinateur. Sa capacité à s’améliorer continuellement au fur et à mesure que de nouvelles données lui sont fournies en fait un outil clé dans diverses industries, de la santé...: Quelle est exactement la différence entre ces mots à la mode?
Un guide complet sur l'analyse des données à l'aide de Pandas
Si vous voulez partager vos pensées, vous pouvez me joindre à LinkedIn.
Bon apprentissage!
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





