
Avec une puissance de calcul croissante, maintenant nous pouvons sélectionner des algorithmes qui effectuent des calculs très intensifs. L'un de ces algorithmes est le “Forêt aléatoire”, dont nous parlerons dans ce post. Bien que l'algorithme soit très populaire dans diverses compétitions (par exemple, ceux qui courent à Kaggle), le résultat final du modèle est comme une boîte noire et, pour cela, doit être utilisé à bon escient.
avant de continuer, voici un exemple sur la pertinence de sélectionner le meilleur algorithme.
Pertinence de la sélection du bon algorithme
Hier, j'ai vu un film intitulé ” L'ère d'El Mañana". J'ai adoré le concept et le processus de réflexion qui se cachent derrière l'intrigue de ce film. Permettez-moi de résumer l'intrigue (sans commenter le point culminant, Sûr). Contrairement aux autres films de science-fiction, ce film tourne autour d'un seul pouvoir qui est conféré des deux côtés (héros et méchant). La puissance est la capacité de redémarrer la journée.
La race humaine est en guerre contre une espèce exotique appelée “Imite”. Mimic est décrit comme une civilisation beaucoup plus évoluée qu'une espèce exotique. Toute la civilisation Mimic est comme un seul organisme complet. Il a un cerveau central appelé “Oméga” qui contrôle tous les autres organismes de la civilisation. Restez en contact avec toutes les autres espèces de civilisation chaque seconde. "Alpha" est la principale espèce guerrière (comme le système nerveux) de cette civilisation et prend les commandes de "Omega". “Oméga” a le pouvoir de recommencer la journée à tout moment.
À présent, portons une casquette d'analyste prédictif pour analyser ce complot. Si un système a la capacité de redémarrer la journée à tout moment, il utilisera ce pouvoir à chaque fois qu'un de ses guerriers mourra. Oui, pour cela, il n'y aura pas une seule guerre, quand l'une des espèces guerrières (alfa) va vraiment mourir, et le cerveau “Oméga” testera à plusieurs reprises le meilleur scénario pour maximiser la mort de la race humaine et limiter le nombre de victimes alpha (espèce guerrière) à zéro tous les jours. Vous pouvez imaginer cela comme “LE MEILLEUR” algorithme prédictif jamais créé. Il est littéralement impossible de vaincre un tel algorithme.
Revenons maintenant à “Forêts aléatoires” à l'aide d'une étude de cas.
Cas d'étude
Vous trouverez ci-dessous une répartition des revenus annuels Gini Coefficients dans différents pays:
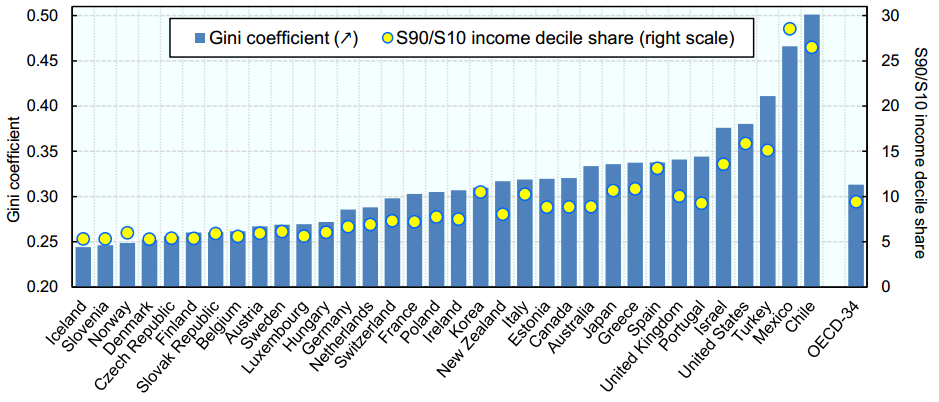
Le Mexique a le deuxième coefficient de Gini le plus élevé et, pour cela, a une très forte ségrégation dans le revenu annuel des riches et des pauvres. Notre tâche est de créer un algorithme prédictif précis pour estimer le niveau de revenu annuel de chaque individu au Mexique. Les tranches de revenus sont les suivantes:
1. Moins de $ 40,000
2. $ 40 000 – 150 000
3. Plus de $ 150 000
Voici les informations disponibles pour chaque individu:
1. Âge, 2. Genre, 3. Diplôme d'études le plus élevé, 4. Travailler dans l'industrie, 5. Résidence dans le métro / Pas de compteur
Nous devons concevoir un algorithme pour donner une prédiction précise pour un individu qui a les traits suivants:
1. Âge: 35 ans, 2, Genre: Masculin, 3. Diplôme d'études le plus élevé: diplomate, 4. Industrie: Fabrication, 5. Accueil: Métro
Nous ne parlerons que de forêt aléatoire pour faire cette prédiction dans ce post.
L'algorithme de la forêt aléatoire
La forêt aléatoire est comme un algorithme de bootstrap avec le modèle d'arbre de décision (CHARIOT). Disons que nous avons 1000 observations dans l'ensemble de la population avec 10 variables. La forêt aléatoire essaie de construire plusieurs modèles CART avec différents échantillons et différentes variables initiales. Par exemple, un échantillon aléatoire de 100 observations et 5 Variables initiales choisies au hasard pour construire un modèle CART. va répéter la procédure (Disons) 10 fois, puis faire une prédiction finale sur chaque observation. La prévision finale est fonction de chaque prévision. Cette prédiction finale peut simplement être la moyenne de chaque prédiction.
Retour à l'étude de cas
Avertissement: les chiffres dans ce post sont illustratifs
Le Mexique a une population de 118 MM. Disons que l'algorithme Random Forest collecte 10 000 observations avec une seule variable (simplifier) pour construire chaque modèle CART. En tout, nous regardons le modèle de 5 CART en cours de construction avec différentes variables. Dans un obstacle de la vie réelle, vous aurez plus d'échantillons de population et différentes combinaisons de variables d'entrée.
Échelles salariales:
Bande 1: Moins de $ 40,000
Bande 2: $ 40 000 – 150 000
Bande 3: plus de $ 150,000
Ci-dessous les résultats de la 5 différents modèles de CART.
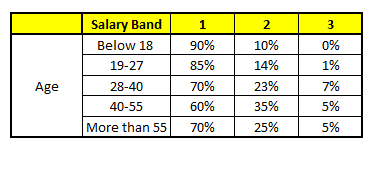
CHARIOT 1: Âge variable
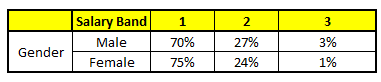
CHARIOT 2: Genre variable
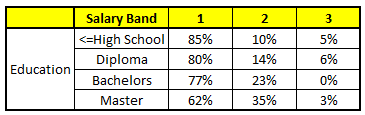
CHARIOT 3: Éducation variable
CHARIOT 4: Résidence variable

CHARIOT 5: Industrie variable
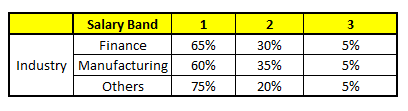
En utilisant ces 5 PANIER, nous devons arriver à un seul ensemble de probabilités pour appartenir à chacune des classes de salaire. Pour simplifier, nous ne prendrons qu'une moyenne de probabilités dans cette étude de cas. En dehors du simple moyen, nous considérons également la méthode de vote pour arriver à la prévision finale. Pour atteindre la prévision finale, localisons le profil suivant dans chaque modèle CART:
1. Âge: 35 ans, 2, Genre: Masculin, 3. Diplôme d'études le plus élevé: diplomate, 4. Industrie: Fabrication, 5. Accueil: Métro
Pour chacun de ces modèles CART, La répartition entre les tranches salariales est indiquée ci-dessous.:
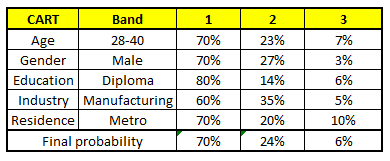
La probabilité finale est simplement la moyenne de la probabilité dans les mêmes tranches de salaire dans différents modèles CART. Comme vous pouvez le voir dans cette analyse, il y a un 70% chances que cet individu tombe dans la classe 1 (moins de $ 40,000) et autour du 24% chances que l'individu tombe dans la classe 2.
Remarques finales
La forêt aléatoire fournit des prédictions beaucoup plus précises par rapport aux modèles CART simples / CHAID ou régression dans de nombreux scénarios. Ces cas ont généralement un grand nombre de variables prédictives et une taille d'échantillon énorme. En effet, il capture la variance de plusieurs variables d'entrée en même temps et permet à un grand nombre d'observations de participer à la prévision.. Dans certains des prochains articles, nous parlerons plus en détail de l'algorithme et de la façon de construire une forêt aléatoire simple dans R.





