Vue d'ensemble
- En savoir plus sur le balisage des parties vocales (PDV),
- Comprendre l'analyse de dépendance et l'analyse de district
introduction
La connaissance des langues est la porte de la sagesse.
– Roger Bacon
J'ai été étonné que Roger Bacon a donné la citation ci-dessus au XIIIe siècle, et ça tient toujours, ce n'est pas comme ça? Je suis sûr que tout le monde sera d'accord avec moi.
Aujourd'hui, la façon de comprendre les langues a beaucoup changé depuis le 13ème siècle. Nous l'appelons maintenant linguistique et traitement du langage naturel. Mais son importance n'a pas diminué; en échange, a énormément augmenté. Tu sais pourquoi? Parce que c'est Applications ont été abattus et l'un d'eux est la raison pour laquelle vous avez atterri sur cet article.

Chacune de ces applications implique des techniques de PNL complexes et, pour les comprendre, il est nécessaire d'avoir une bonne connaissance des bases de la PNL. Donc, avant de passer à des sujets complexes, il est important de garder les fondamentaux corrects.
C'est pourquoi j'ai créé cet article dans lequel je couvrirai quelques concepts de base de la PNL.: étiquetage d'une partie du discours (PDV), Analyse de dépendance et analyse de district dans le traitement du langage naturel. Nous allons comprendre ces concepts et les implémenter également en Python. Nous allons commencer!
Table des matières
- Étiqueter une partie du discours (PDV)
- Analyse de dépendance
- Analyse des circonscriptions
Étiqueter une partie du discours (PDV)
Dans nos jours d'école, nous avons tous étudié les parties du discours, qui comprend des noms, pronoms, adjectifs, verbes, etc. Les mots appartenant à différentes parties du discours forment une phrase. Connaître la partie vocale des mots d'une phrase est important pour la comprendre.
C'est la raison de la création du concept d'étiquetage POS.. Je suis sûr que maintenant vous aurez deviné ce qu'est l'étiquetage POS. Même comme ça, laissez-moi expliquer.
Étiqueter une partie du discours (PDV) est le processus d'attribution de différentes balises appelées balises POS aux mots d'une phrase qui nous renseigne sur la partie vocale du mot.
En termes générales, il existe deux types d'étiquettes POS:
1. Étiquettes de point de vente universelles: Ces balises sont utilisées dans les dépendances universelles (DEHORS) (dernière version 2), un projet qui développe des annotations de banque d'arbres cohérentes dans toutes les langues pour de nombreuses langues. Ces balises sont basées sur le type de mots. Par exemple, NOM (nom commun), ADJ (adjectif), ADV (adverbe).
Liste universelle des étiquettes de point de vente
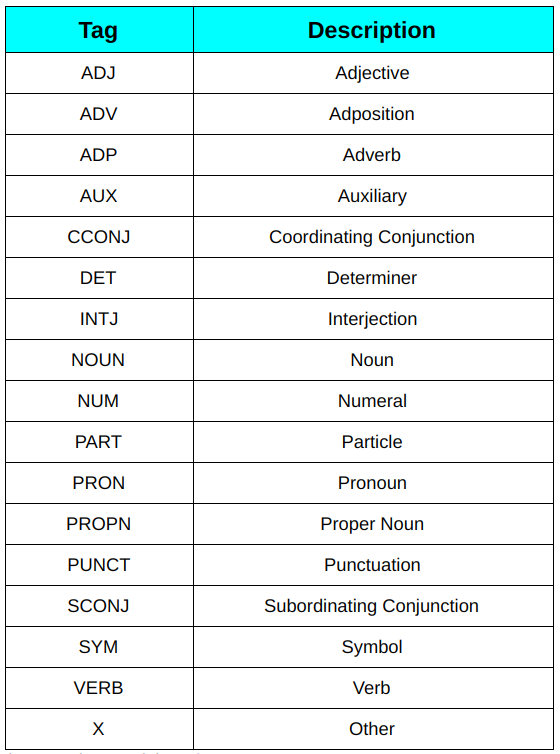
Vous pouvez en savoir plus sur chacun d'eux ici.
2. Etiquettes point de vente détaillées: Ces étiquettes sont le résultat de la division des étiquettes universelles de PLV en plusieurs étiquettes, comme NNS pour les noms communs au pluriel et NN pour le nom commun singulier comparé à NOUN pour les noms communs en anglais. Ces balises sont spécifiques à la langue. Vous pouvez consulter la liste complète ici.
Vous savez maintenant ce que sont les étiquettes de point de vente et ce qu'est l'étiquetage de point de vente. Ensuite, écrivons le code Python pour les phrases de marquage POS. Dans ce but, J'ai utilisé Spacy ici, mais il existe d'autres bibliothèques comme NLTK Oui Strophe, qui peut également être utilisé pour faire la même chose.

Dans l'exemple de code ci-dessus, j'ai chargé l'espace fr_web_core_sm modèle et l'a utilisé pour obtenir les balises POS. Vous pouvez voir que le pos_ renvoie les balises POS universelles, Oui étiqueter_ renvoie des balises POS détaillées pour les mots de la phrase.
Analyse de dépendance
L'analyse de dépendance est le processus d'analyse de la structure grammaticale d'une phrase en fonction des dépendances entre les mots d'une phrase.
En analyse de dépendance, plusieurs étiquettes représentent la relation entre deux mots dans une phrase. Ces balises sont les balises de dépendance. Par exemple, dans l'expression “temps de pluie”, mot pluvieux modifier le sens du nom climat. Donc, il y a une dépendance au climat -> pluvieux dans lequel le climat faire comme lui Tête et le pluvieux agit comme dépendant O enfant. Cette dépendance est représentée par état étiqueter, qui représente le modificateur de l'adjectif.
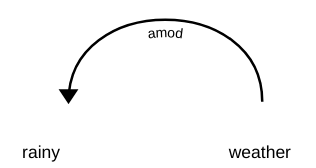
de la même manière, il y a beaucoup de dépendances entre les mots d'une phrase, mais notez qu'une dépendance n'implique que deux mots dans lesquels l'un agit en tant que chef et l'autre agit en tant qu'enfant. À partir de maintenant, il y a 37 Relations de dépendance universelle utilisées dans la dépendance universelle (version 2). Vous pouvez tous les regarder ici. En dehors de ces, il existe également de nombreuses balises spécifiques à la langue.
Utilisons maintenant Spacy et trouvons les dépendances dans une phrase.

Dans l'exemple de code ci-dessus, les dep_ renvoie la balise de dépendance d'un mot et tête de texte renvoie le respectif Tête mot. Si vous avez remarqué, dans l'image ci-dessus, mot Je prends a une balise de dépendance de RACINE. Cette balise est attribuée au mot qui sert d'en-tête à de nombreux mots dans une phrase, mais ce n'est la fille d'aucun autre mot. Généralement, est le verbe principal de la phrase similaire à « pris’ dans ce cas.
Vous savez maintenant quelles balises de dépendance et quel mot principal, secondaire et racine sont. Mais l'analyse ne signifie-t-elle pas générer un arbre d'analyse?
Oui, nous générons l'arbre ici, mais nous ne le visualisons pas. L'arbre généré par l'analyse de dépendance est appelé arbre de dépendance. Il y a plusieurs façons de le visualiser, mais par souci de simplicité, nous utiliserons DÉPLACEMENT qui est utilisé pour afficher l'analyse de dépendance.

Dans l'image ci-dessus, les flèches représentent la dépendance entre deux mots dans lesquels le mot à la pointe de la flèche est l'enfant et le mot à la fin de la flèche est la tête. Le mot racine peut servir de titre pour plusieurs mots dans une phrase, mais ce n'est la fille d'aucun autre mot. Vous pouvez voir ci-dessus que le mot 'a pris’ a plusieurs flèches sortantes mais aucune entrante. Pourtant, est la racine du mot. Une chose intéressante à propos du mot racine est que si vous commencez à tracer les dépendances dans une phrase, peut aller à la racine du mot, peu importe de quel mot il commence.
Maintenant que vous connaissez l'analyse de dépendance, Apprenons un autre type d'analyse connu sous le nom d'analyse des constituants.
Analyse des circonscriptions
L'analyse des constituants est le processus d'analyse des phrases en les divisant en sous-phrases également appelées constituants.. Ces sous-phrases appartiennent à une catégorie spécifique de grammaire comme NP (expression nominale) le vice-président (expression verbale).
Comprenons à l'aide d'un exemple. Supposons que j'ai la même phrase que j'ai utilisée dans les exemples précédents, c'est-à-dire, “Il m'a fallu plus de deux heures pour traduire certaines pages de l'anglais”. et j'ai effectué une analyse de circonscription là-dessus. Ensuite, l'arbre d'analyse constitutif de cette phrase est donné par:
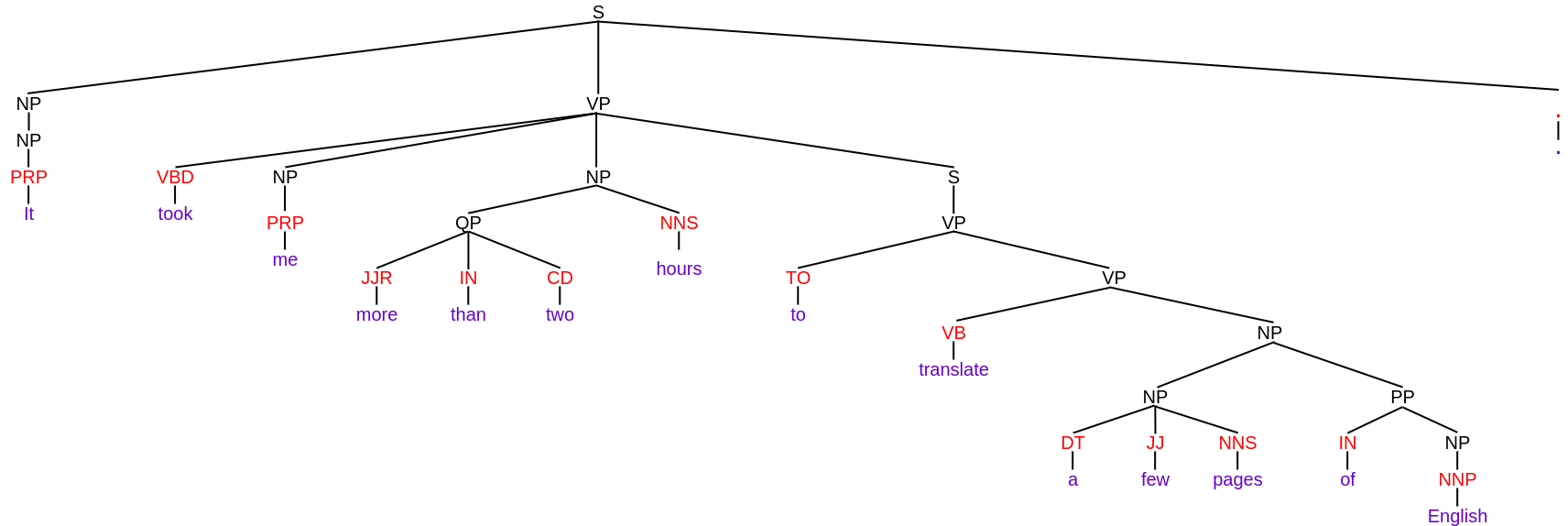
Dans l'arbre ci-dessus, les mots de la phrase sont écrits en violet et les balises POS sont écrites en rouge. Sauf pour ces, tout est écrit en noir, qui représente les composants. Vous pouvez clairement voir comment toute la phrase est divisée en sous-phrases jusqu'à ce que seuls les mots soient laissés dans les terminaux. En outre, il existe différentes étiquettes pour désigner des composants tels que
- VP pour l'expression verbale
- NP pour les phrases nominales
Ce sont les étiquettes constitutives. Vous pouvez en savoir plus sur les différentes étiquettes constitutives ici.
Vous savez maintenant ce qu'est l'analyse de circonscription, il est donc temps de coder en python. À présent, spaCy ne fournit pas d'API officielle pour l'analyse des constituants. Donc, nous utiliserons le Analyseur neuronal de Berkeley. Il s'agit d'une implémentation Python d'analyseurs basés sur Analyse de circonscription avec un codeur attentif par ACL 2018.
Vous pouvez également utiliser StanfordParser avec Stanza ou NLTK à cette fin, mais ici j'ai utilisé Berkely Neural Parser. Pour utiliser cela, nous devons d'abord l'installer. Vous pouvez le faire en exécutant la commande suivante.
!pip installer benepar
Ensuite, vous devez télécharger le benerpar_fr2 maquette.
Vous avez peut-être remarqué que j'utilise TensorFlow 1.x ici car actuellement, benepar n'est pas compatible avec TensorFlow 2.0. Il est maintenant temps d'analyser les circonscriptions.

Ici, _.parse_string génère l'arbre d'analyse sous forme de chaîne.
Remarques finales
À présent, vous savez déjà ce qu'est l'étiquetage POS, analyse de dépendance et analyse des constituants et comment ils vous aident à comprendre les données textuelles, c'est-à-dire, Les balises POS vous renseignent sur la partie grammaticale des mots dans une phrase, L'analyse de dépendance vous informe sur les dépendances entre les mots d'une phrase et l'analyse des constituants vous informe sur les sous-phrases ou les constituants d'une phrase. Vous êtes maintenant prêt à passer à des parties plus complexes de la PNL.. Comme prochaines étapes, Vous pouvez lire les articles suivants sur l'extraction d'informations.
Dans ces articles, vous apprendrez à utiliser les balises POS et les balises de dépendance pour extraire des informations du corpus. En outre, pour plus d'informations sur spaCy, vous pouvez lire cet article: Tutoriel SpaCy pour apprendre et maîtriser le traitement du langage naturel (PNL) En dehors de ces, si vous voulez apprendre le traitement du langage naturel à travers un cours, Je peux recommander ce qui suit qui comprend tout, des projets aux tutoriels individuels:
Si vous avez trouvé cet article informatif, Partage-le avec tes amis. En outre, vous pouvez commenter ci-dessous vos questions.





