Cet article a été publié dans le cadre du Blogathon sur la science des données
La création de la reconnaissance faciale est considérée comme une tâche très facile dans le domaine de la vision par ordinateur., mais il est extrêmement difficile d'avoir un pipeline capable de prédire des visages avec des arrière-plans complexes lorsque vous avez plusieurs visages, différentes conditions d'éclairage et différentes échelles d'image. Ce blog décrira comment nous créons un modèle qui peut surpasser les humains dans certains cas. Notre jeu de données se compose de 3 cours (Je ne peux pas partager les données en raison de problèmes de confidentialité, mais je vais te montrer à quoi ça ressemble). Classe 1 c'est Jesse Eisenberg (acteur), classe 2 est Mila Kunis (pop star) et la classe 0, Toute personne. Voici à quoi ressemblait notre train (80 images) et tester les données (plus de 1800 images).
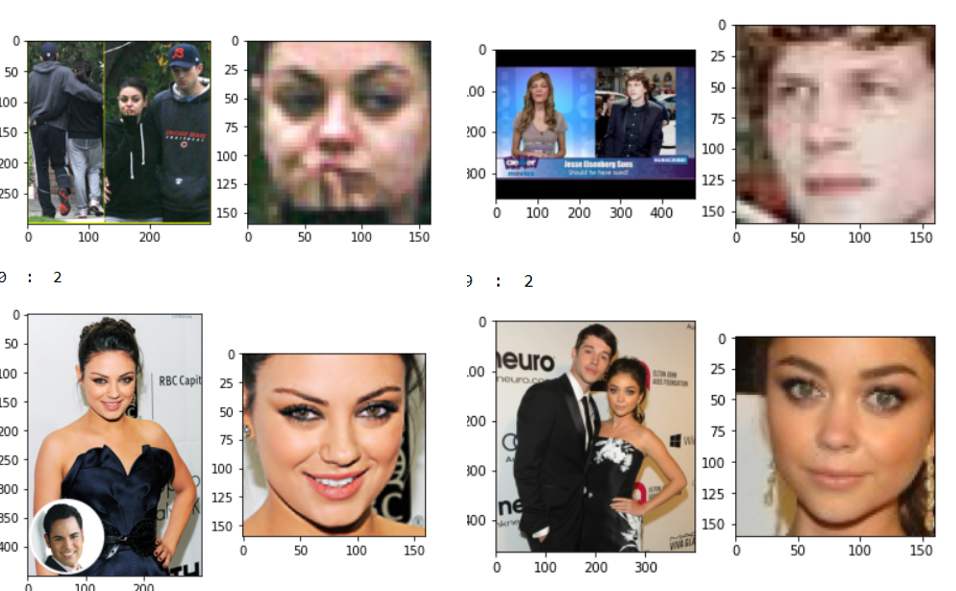
Ce sont nos données de test et les visages extraits de ces images, ces données sont extrêmement complexes en raison de multiples visages, arrière-plans complexes et beaucoup d'images pixelisées. D'un autre côté, nos données de train sont extrêmement propres, comme le montre l'image ci-dessous. Nous avons de nombreuses différences dans la distribution des données de test et d'entraînement. Nous avons besoin d'une technique qui puisse bien se généraliser quel que soit le nombre d'échantillons dont vous avez besoin et la différence entre les données d'apprentissage et de test..

La technique que nous allons utiliser pour cette tâche est, en premier lieu, générer la clé faciale à partir d'un modèle d'apprentissage en profondeur, puis appliquer un simple classificateur.
Utiliser FACENET
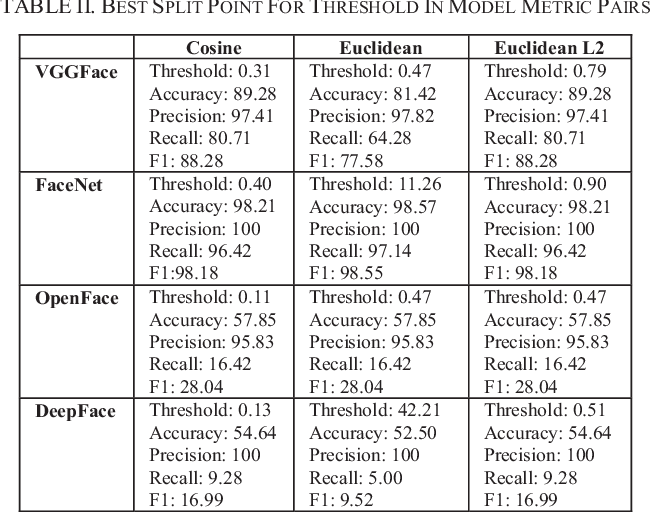
Pour vraiment repousser les limites de la détection des visages, nous verrons des méthodes de pointe. Les techniques modernes d'extraction de visage ont utilisé les réseaux de convolution profonde. Comme nous le savons tous, les fonctionnalités créées par les frameworks d'apprentissage en profondeur modernes sont en fait meilleures que la plupart des fonctionnalités créées à la main. Nous vérifions 4 modèles d'apprentissage en profondeur, a savoir, FaceNet (Google), Visage profond (Facebook), VGGface (Oxford) et OpenFace (UMC). De ceux-ci 4 Des modèles FaceNet cela nous donnait le meilleur résultat. En général, FaceNet offre de meilleurs résultats que les autres 3 Des modèles.
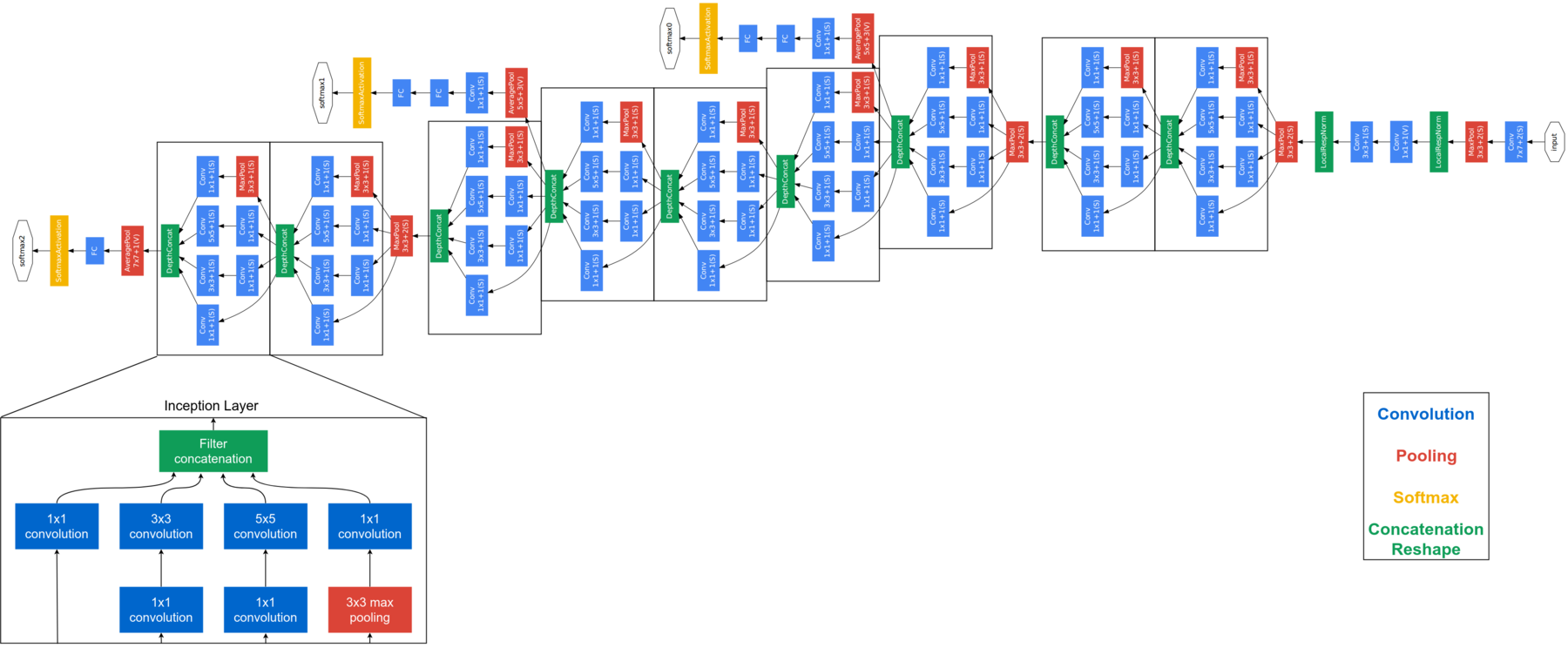
FaceNet est considéré comme un modèle de nouvelle génération développé par Google. Il est basé sur la couche initiale, expliquer l'architecture complète de FaceNet dépasse le cadre de ce blog. Ci-dessous l'architecture FaceNet. FaceNet utilise des modules de démarrage de bloc pour réduire le nombre de paramètres pouvant être entraînés. Ce modèle prend des images RVB de 160 × 160 et génère une intégration de taille 128 pour une photo. Pour cette implémentation, nous aurons besoin de quelques fonctions supplémentaires. Mais avant d'envoyer l'image du visage à FaceNet, nous devons extraire les visages des images.
détecteur = dlib.cnn_face_detection_model_v1("../input/pretrained-models-faces/mmod_human_face_detector.dat")
def rect_à_bb(rectifier):
# prendre une limite prédite par dlib et la convertir
# au format (X, Oui, w, h) comme nous le ferions normalement
# avec OpenCV
x = rect.rect.gauche()
y = rect.rect.top()
w = rect.rect.droit() - X
h = rect.rect.bas() - Oui
# retourner un tuple de (X, Oui, w, h)
revenir (X, Oui, w, h)
def dlib_corrected(Les données, type_données="former"):
#Nous définissons la taille de l'image
faible = (160, 160)
data_images=[]
#Si nous traitons des données d'entraînement, nous devons garder une trace des étiquettes
if data_type=='train':
étiquettes_données=[]
#Boucle sur toutes les images
pour cnt dans la gamme(0,longueur(Les données)):
image = données['img'][cnt]
#Les grandes images sont redimensionnées
si image.forme[0] > 1000 et image.shape[1] > 1000:
image = cv2.redimensionner(image, (1000,1000), interpolation = cv2.INTER_AREA)
#L'image est convertie en niveaux de gris
gris = cv2.cvtCouleur(image, cv2.COLOR_BGR2GRAY)
#Détecter les visages
rects = détecteur(gris, 1)
sub_images_data = []
#Boucle sur tous les visages de l'image
pour (je, rectifier) en énumérer(rectifier):
#Convertir le cadre de délimitation en arêtes
(X, Oui, w, h) = rect_to_bb(rectifier)
#Ici, nous copions et recadrons le visage de l'image
clone = image.copy()
si(X>=0 et y>=0 et w>=0 et h>=0):
crop_img = cloner[Oui:y+h, X:x+w]
autre:
crop_img = clone.copy()
#Nous redimensionnons le visage à la bonne taille
rgbImg = cv2.redimensionner(crop_img, faible, interpolation = cv2.INTER_AREA)
#Dans l'ensemble de test, nous gardons une trace de tous les visages dans une image
if data_type == 'train':
sub_images_data = rgbImg.copy()
autre:
sous_images_data.append(rgbImg)
#Si aucun visage n'est détecté dans l'image, nous ajouterons un NaN
si(longueur(rectifier)==0):
if data_type == 'train':
sub_images_data = np.empty(faible + (3,))
sous_images_data[:] = np.nan
si data_type=='test':
nan_images_data = np.empty(faible + (3,))
nan_images_data[:] = np.nan
sous_images_data.append(nan_images_data)
#Ici, nous ajoutons l'image(s) à la liste nous reviendrons
data_images.append(sous_images_data)
#Et ajoutez l'étiquette à la liste
if data_type=='train':
data_labels.append(Les données['classer'][cnt])
#Enfin, nous devons retourner le nombre correct de tableaux
if data_type=='train':
retourner np.array(data_images), np.array(étiquettes_données)
autre:
retourner np.array(data_images)
USANDO DLIB
DLIB est un modèle largement utilisé pour détecter les visages. Dans nos expériences, nous avons constaté que dlib produit de meilleurs résultats que HAAR, même si nous notons que certaines améliorations peuvent encore être apportées:
- Si les limites de la face rectangulaire sont déplacées hors de l'image, nous prenons l'image entière au lieu de la découpe du visage. Il est mis en œuvre comme suit:
- et (X> = 0 et et> = 0 oui> = 0 oui> = 0):
- crop_img = clon[Oui:y+h, X:x+w]
- le reste:
- et (X> = 0 et et> = 0 oui> = 0 oui> = 0):
- Pour les images de test, au lieu d'enregistrer un visage par image, nous gardons tous les visages pour la prédiction.
- Au lieu d'un détecteur basé sur HOG, nous pouvons utiliser un détecteur basé sur CNN. Comment ces améliorations sont conçues pour optimiser votre utilisation de FaceNet, nous allons définir une nouvelle détection de visage corrigée.
Le bloc de code ci-dessus extrait les visages de l'image, pour beaucoup d'images nous avons plusieurs visages, donc nous devons mettre tous ces visages dans une liste. Pour extraire les visages que nous utilisons dlib.cnn_face_detection_model_v1, notez que vous ne devez pas fournir d'images de très grande dimension à ce, sinon vous obtiendrez une erreur de mémoire dlib. Si une image n'a pas de visage, stocke NaN dans ces endroits. Faisons face à ces images de données maintenant. Le prétraitement ci-dessus n'est requis que pour les données de test, les données du train sont déjà propres, ce que l'on peut voir sur les photos ci-dessus. Une fois que nous avons terminé d'obtenir les incrustations du visage à partir des données du train, obtenir des incrustations faciales pour les données de test, mais vous devez d'abord utiliser le prétraitement fourni dans le bloc de code ci-dessus pour extraire les visages des données de test.
def get_embedding(maquette, face_pixels):
# mettre à l'échelle les valeurs des pixels
face_pixels = face_pixels.astype('float32')
# standardiser les valeurs de pixels sur tous les canaux (global)
moyenne, std = face_pixels.mean(), face_pixels.std()
face_pixels = (face_pixels - moyenne) / std
# transformer le visage en un seul échantillon
échantillons = expand_dims(face_pixels, axe=0)
# faire une prédiction pour obtenir l'intégration
yhat = model.predict(échantillons)
retour yhat[0]
modèle = load_model('../input/pretrained-models-faces/facenet_keras.h5')
svmtrainX = []
pour index, face_pixels dans énumérer(nouveauTrainX):
incorporation = get_embedding(maquette, face_pixels)
svmtrainX.append(encastrement)
Après avoir généré les inlays pour la formation et les tests, nous utiliserons SVM pour la classification. Pourquoi SVM, Vous pouvez demander? Avec beaucoup d'expérience, J'ai appris que les fonctions basées sur SVM + DL peut surpasser toute autre méthode, même aux méthodes d'apprentissage en profondeur, lorsque la quantité de données est faible.
de sklearn.svm importer SVC depuis sklearn.pipeline importer make_pipeline de sklearn.naive_bayes importer GaussianNB de sklearn.neural_network importer MLPClassifier de sklearn.preprocessing importer StandardScaler, MinMaxScaler, Normalisateur linear_model = make_pipeline(Échelle standard(), SVC(noyau="rbf", C=1.0, gamma=0,01, probabilité = vrai)) modèle_linéaire.fit(svmtrainX, svmtrainY)
Une fois le SVM formé, il est temps de faire des tests, mais nos données de test ont plusieurs visages dans une liste. Ensuite, tant qu'on a Jesse ou Mila sur une photo, nous allons ignorer la classe 0 et quand Jesse et Mila sont tous deux présents sur une photo, alors nous choisirons celui qui nous donne la plus grande précision.
prédictions =[]
pour i dans corrigé_test_X:
indicateur=0
si(longueur(je)==1):
incorporation = get_embedding(maquette, je[0])
tmp_output = linear_model.predict([encastrement])
predictions.append(sortie_tmp[0])
autre:
tmp_sub_pred = []
tmp_sub_prob = []
pour j en i:
j= j.astype(entier)
incorporation = get_embedding(maquette, j)
tmp_output = linear_model.predict([encastrement])
tmp_sub_pred.append(sortie_tmp[0])
tmp_output_prob = linear_model.predict_log_proba([encastrement])
tmp_sub_prob.append(np.max(tmp_output_prob[0]))
si 1 dans tmp_sub_pred et 2 dans tmp_sub_pred:
index_1 = np.où(np.array(tmp_sub_pred)==1)[0][0]
index_2 = np.où(np.array(tmp_sub_pred)==2)[0][0]
si(tmp_sub_prob[index_1] > tmp_sub_prob[index_2] ):
predictions.append(1)
autre:
predictions.append(2)
elif 1 pas dans tmp_sub_pred et 2 pas dans tmp_sub_pred:
predictions.append(0)
elif 1 dans tmp_sub_pred et 2 pas dans tmp_sub_pred:
predictions.append(1)
elif 1 pas dans tmp_sub_pred et 2 dans tmp_sub_pred:
predictions.append(2)
DISCUSSION
Remarques finales, il s'agit d'un très petit ensemble de données, les résultats peuvent donc changer énormément même lors de l'ajout ou de la suppression de certaines images. Dans notre test, nous avons découvert qu'il nous a trompé plusieurs fois, il y avait autour 20 images dans le test qui ont été incorrectement prédites par nous mais correctement par notre modèle. Nous confirmons le résultat attendu en recherchant ces images sur Google.
Les réseaux de neurones profonds peuvent extraire des fonctionnalités plus significatives que les modèles d'apprentissage automatique. Cependant, la chute de ces grands réseaux est le besoin d'une grande quantité de données. Nous avons réussi à résoudre ce problème en utilisant un modèle préalablement formé, un modèle qui a été formé sur un ensemble de données beaucoup plus vaste pour conserver les connaissances sur la façon de coder les images faciales, que nous utilisons ensuite à nos fins dans ce défi. En outre, Le réglage fin de SVM nous a vraiment aidés à aller au-delà de la précision du 95%.





