introduction
De nombreux analystes comprennent mal le terme « impulsion » utilisé en science des données. Permettez-moi de vous donner une explication intéressante de ce terme.. Momentum permet aux modèles d'apprentissage automatique d'améliorer la précision de leurs prédictions.
Les algorithmes Boost sont l'un des algorithmes les plus utilisés dans les compétitions de science des données. Les gagnants de notre derniers hackathons conviennent qu'ils essaient de pousser l'algorithme pour améliorer la précision de leurs modèles.
Dans cet article, Je vais vous expliquer comment fonctionne l'algorithme de boost de manière très simple. J'ai également partagé les codes python ci-dessous. J'ai ignoré les dérivations mathématiques intimidantes utilisées dans Boosting. Car cela ne m'aurait pas permis d'expliquer ce concept en termes simples.
Commençons.

Qu'est-ce que le boost?
Définition: Le terme « Impulsion » fait référence à une famille d'algorithmes qui transforme un élève faible en un élève fort.
Comprenons cette définition en détail en résolvant un problème d'identification de spam:
Comment classeriez-vous un e-mail comme SPAM ou non? Comme tout le monde, notre approche initiale serait d'identifier les e-mails « pourriel » Oui « Pas de spam » en utilisant les critères suivants. Et:
- L'e-mail n'a qu'un seul fichier image (image promotionnelle), es un SPAM
- L'e-mail n'a qu'un lien (s), es un SPAM
- Le corps de l'e-mail se compose d'une phrase comme « Vous avez gagné un prix en espèces de $ xxxxxx », es un SPAM
- Courriel de notre domaine officiel « Analyticsvidhya.com« , Ce n'est pas un SPAM
- Courriel de source connue, Pas de spam
Précédemment, hemos definido varias reglas para clasificar un correo electrónico en ‘pourriel’ O ‘Pas de spam’. Mais, Pensez-vous que ces règles individuellement sont suffisamment strictes pour classer avec succès un e-mail? Non.
Individuellement, estas reglas no son lo suficientemente poderosas como para clasificar un correo electrónico en ‘pourriel’ O ‘Pas de spam’. Donc, ces règles s'appellent apprenant faible.
Transformer un élève faible en un élève fort, nous combinerons la prédiction de chaque élève faible en utilisant des méthodes telles que:
• Utilisation de la moyenne / moyenne pondérée
• Considérant que la prédiction a un vote plus élevé
Par exemple: en haut, nous avons défini 5 élèves faibles. De ceux-ci 5, 3 se votan como ‘SPAM’ Oui 2 se votan como ‘No es SPAM’. Dans ce cas, par défaut, nous considérerons un e-mail comme SPAM car nous avons un vote plus élevé (3) à ‘SPAM’.
Comment fonctionnent les algorithmes d'impulsion?
Nous savons maintenant que le momentum combine un élève faible, également connu sous le nom d'étudiant de base, pour former une règle solide. Une question immédiate qui devrait se poser dans votre esprit est: ‘Comment booster l'identification des règles faibles?‘
Pour trouver une règle faible, nous appliquons des algorithmes d'apprentissage de base (ML) avec une répartition différente. Chaque fois que l'algorithme d'apprentissage de base est appliqué, génère une nouvelle règle de prédiction faible. Il s'agit d'un processus itératif. Après plusieurs itérations, l'algorithme de quantité de mouvement combine ces règles faibles en une seule règle de prédiction forte.
Voici une autre question qui pourrait vous hanter ».Comment choisissons-nous une distribution différente pour chaque tour? ‘
Pour choisir la bonne mise en page, ce sont les prochaines étapes:
Paso 1: L'étudiant de base prend toutes les distributions et attribue un poids ou une attention égal à chaque observation.
Paso 2: S'il y a des erreurs de prédiction causées par le premier algorithme d'apprentissage de base, alors nous prêtons plus d'attention aux observations qui ont une erreur de prédiction. Alors, nous appliquons l'algorithme d'apprentissage de base suivant.
Paso 3: Répéter l'étape 2 jusqu'à ce que la limite de l'algorithme d'apprentissage de base soit atteinte ou qu'une précision plus élevée soit atteinte.
Finalement, combine les résultats de l'élève faible et crée un élève fort qui améliore finalement le pouvoir prédictif du modèle. L'élan est accordé plus d'attention aux exemples qui sont mal classés ou ont des erreurs plus élevées en raison des règles faibles ci-dessus.
Types d'algorithmes d'impulsion
Le moteur sous-jacent utilisé pour piloter les algorithmes peut être n'importe quoi. Cela peut être un sceau de décision, un algorithme de tri qui maximise les marges, etc. Il existe de nombreux algorithmes de boost que d'autres types de moteurs utilisent, Quoi:
- AdaBoost (Il y aptif AugmenterEffrayant)
- Montée des arbres en dégradé
- XGBoost
Dans cet article, nous nous concentrerons sur AdaBoost et Gradient Boosting suivis de leurs codes Python respectifs et nous nous concentrerons sur XGboost dans le prochain article.
Augmentation d'algorithme: AdaBoost
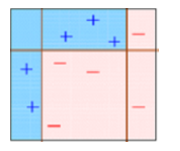
Ce diagramme explique bien Ada-boost. Comprenons de près:
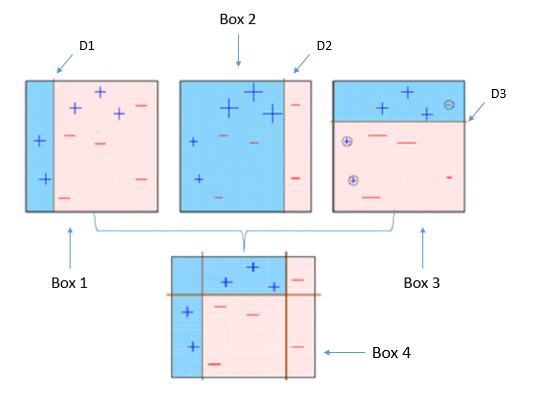
Boîte 1: Vous pouvez voir que nous avons attribué des poids égaux à chaque point de données et appliqué une souche de décision pour les classer comme + (plus) O – (moins). Le moignon de décision (D1) a généré une ligne verticale sur le côté gauche pour classer les points de données. On voit ça, cette ligne verticale a prédit à tort trois + (plus) Quoi – (moins). Dans ce cas, nous attribuerons des poids plus élevés à ces trois + (plus) et nous appliquerons une autre souche de décision.
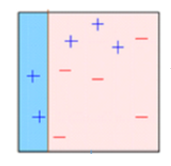
Boîte 2: Ici, vous pouvez voir que la taille de trois + (plus) incorrectement prédit est plus élevé par rapport au reste des points de données. Dans ce cas, le deuxième moignon de décision (D2) va essayer de les prédire correctement. À présent, une ligne verticale (D2) sur le côté droit de ce tableau, vous avez correctement classé trois + (plus) mal classé. Mais, a causé des erreurs de classification. Cette fois avec trois – (moins). Encore, nous attribuerons un poids plus important à trois – (moins) et nous appliquerons une autre souche de décision.
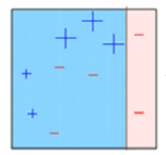
Boîte 3: Ici, trois – (moins) recevoir des poids plus élevés. Un moignon de décision est appliqué (D3) pour prédire correctement ces observations mal classées. Cette fois, une ligne horizontale est générée pour classer + (plus) Oui – (moins) basé sur un poids plus élevé d'observations mal classées.
Boîte 4: Ici, nous avons combiné D1, D2 et D3 pour former une prédiction forte qui a une règle complexe par rapport à un élève faible individuel. Vous pouvez voir que cet algorithme a assez bien classé ces observations par rapport à n'importe lequel des élèves faibles..
AdaBoost (Il y aptif Augmenterment): Il fonctionne avec une méthode similaire à celle décrite ci-dessus. Se ajusta a una secuencia de estudiantes débiles en diferentes datos de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... ponderados. Commencez par prédire l'ensemble de données d'origine et attribuez à chaque observation un poids égal. Si la prédiction est fausse en utilisant le premier élève, alors les observations incorrectement prédites reçoivent un poids plus important. Être un processus itératif, continue d'ajouter des apprenants jusqu'à ce qu'une limite sur le nombre de modèles ou la précision soit atteinte.
Principalement, nous utilisons des tampons de décision avec AdaBoost. Mais nous pouvons utiliser n'importe quel algorithme d'apprentissage automatique comme apprenant de base s'il accepte le poids dans l'ensemble de données d'entraînement. Nous pouvons utiliser les algorithmes AdaBoost pour les problèmes de classification et de régression.
Vous pouvez vous référer à l'article « Comment être intelligent avec l'apprentissage automatique: AdaBoost » pour comprendre plus en détail les algorithmes AdaBoost.
Code Python
Voici une fenêtre d'encodage en direct pour vous aider à démarrer. Vous pouvez exécuter les codes et obtenir le résultat dans cette fenêtre:
Puede ajustar los paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... para optimizar el rendimiento de los algoritmos, J'ai mentionné ci-dessous les paramètres clés pour le réglage:
- n_estimateurs: Contrôler le nombre d'élèves faibles.
- taux d'apprentissage:CContrôler la contribution des élèves faibles dans la combinaison finale. Il y a un compromis entre taux d'apprentissage Oui n_estimateurs.
- base_estimateurs: Aide à spécifier différents algorithmes d'apprentissage automatique.
Vous pouvez également ajuster les paramètres de base des élèves pour optimiser leurs performances.
Algorithme d'impulsion: augmentation de la pente
En el aumento de penteLe gradient est un terme utilisé dans divers domaines, comme les mathématiques et l’informatique, pour décrire une variation continue de valeurs. En mathématiques, fait référence au taux de variation d’une fonction, pendant la conception graphique, S’applique à la transition de couleur. Ce concept est essentiel pour comprendre des phénomènes tels que l’optimisation dans les algorithmes et la représentation visuelle des données, permettant une meilleure interprétation et analyse dans..., entraîner plusieurs modèles séquentiellement. Cada nuevo modelo minimiza gradualmente la Fonction de perteLa fonction de perte est un outil fondamental de l’apprentissage automatique qui quantifie l’écart entre les prédictions du modèle et les valeurs réelles. Son but est de guider le processus de formation en minimisant cette différence, permettant ainsi au modèle d’apprendre plus efficacement. Il existe différents types de fonctions de perte, tels que l’erreur quadratique moyenne et l’entropie croisée, chacun adapté à différentes tâches et... (y = hache + b + e, e nécessite une attention particulière car il s'agit d'un terme d'erreur) de l'ensemble du système en utilisant Descente graduelle méthode. El procedimiento de aprendizaje se ajustó consecutivamente a nuevos modelos para proporcionar una estimación más precisa de la variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... de respuesta.
L'idée principale derrière cet algorithme est de construire de nouveaux étudiants de base qui peuvent être corrélés au maximum avec le gradient négatif de la fonction de perte, associé à l'ensemble. Vous pouvez vous référer à l'article « Apprendre l'algorithme d'augmentation du gradient » comprendre ce concept avec un exemple.
Dans la bibliothèque Python Sklearn, Usamos Gradient Tree Boosting o GBRT. C'est une généralisation de l'impulsion à des fonctions de perte dérivables arbitraires. Peut être utilisé pour les problèmes de régression et de classification.
Code Python
à partir de l'importation de sklearn.ensemble DégradéBoostingClassifier #Pour le classement à partir de l'importation de sklearn.ensemble DégradéBoostingRégresseur #Pour la régression
clf = DégradéBoostingClassifier(n_estimateurs=100, taux d'apprentissage=1.0, profondeur max=1) clf.ajuster(X_train, y_train)
- n_estimateurs: Contrôler le nombre d'élèves faibles.
- taux d'apprentissage:CContrôler la contribution des élèves faibles dans la combinaison finale. Il y a un compromis entre taux d'apprentissage Oui n_estimateurs.
- Profondeur maximale: profondeur maximale des estimateurs de régression individuels. La profondeur maximale limite le nombre de nœuds dans l'arbre. Ajustez ce paramètre pour les meilleures performances; la meilleure valeur dépend de l'interaction des variables d'entrée.
Vous pouvez ajuster la fonction de perte pour de meilleures performances.
Note finale
Dans cet article, nous analysons l'élan, l'une des méthodes de modélisation d'ensemble pour améliorer le pouvoir prédictif. Ici, Nous avons discuté de la science derrière l'impulsion et de ses deux types: AdaBoost et Gradient Boost. Nous étudions également leurs codes Python respectifs.
Dans mon prochain article, Je vais discuter d'un autre type d'algorithmes de boost qui est maintenant un secret pour gagner les concours de science des données "XGBoost".
Trouvez-vous utile cet article? Partagez vos opinions / pensées dans la section des commentaires ci-dessous.





