Introduction:
données non structurées dans un format structuré? C'est là que le web scraping entre en scène..
Qu'est-ce que le grattage Web?
En termes simples, grattage Web, moisson web, O extraction de données web est un processus automatisé de collecte de mégadonnées (non structuré) de sites Web. L'utilisateur peut extraire toutes les données sur des sites particuliers ou les données spécifiques selon l'exigence. Les données collectées peuvent être stockées dans un format structuré pour une analyse ultérieure.
Usages du web scraping:
Dans le monde réel, le grattage Web a attiré beaucoup d'attention et a un large éventail d'utilisations. Certains d'entre eux sont énumérés ci-dessous:
- Analyse des sentiments des médias sociaux
- Génération de leads dans le domaine du marketing
- Analyse du marché, comparaison de prix en ligne dans le domaine du commerce électronique
- Recopile datos de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... y prueba en aplicaciones de aprendizaje automático
Étapes impliquées dans le web scraping:
- Trouvez l'URL de la page Web que vous souhaitez gratter
- Sélectionnez les éléments particuliers en inspectant
- Écrivez le code pour obtenir le contenu des éléments sélectionnés
- Stocker les données au format requis
Des gars si simples .. !!
Les bibliothèques / Les outils populaires utilisés pour le grattage Web sont:
- Sélénium: un framework pour tester des applications web
- BelleSoupe: Bibliothèque Python pour obtenir des données à partir de HTML, XML et autres langages de balisage
- Pandas: Bibliothèque Python pour la manipulation et l'analyse de données
Dans cet article, crearemos nuestro propio conjunto de datos extrayendo reseñas de Domino’s Pizza del sitio web. consumeraffairs.com/food.
Nous utiliserons demandes Oui Belle soupe pour grattage et analyse Les données.
Paso 1: trouver l'URL de la page Web que vous souhaitez gratter
ouvrir l'url « consumeraffairs.com/food”Y busque Domino’s Pizza en la barra de búsqueda y presione Enter.
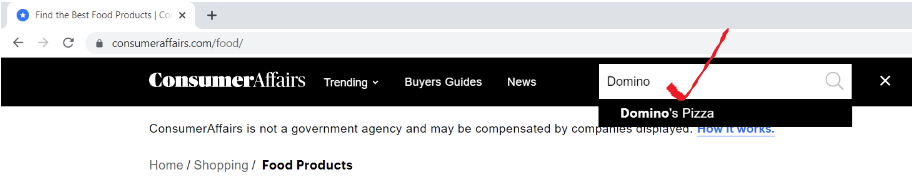
Voici à quoi ressemble notre page d'avis.
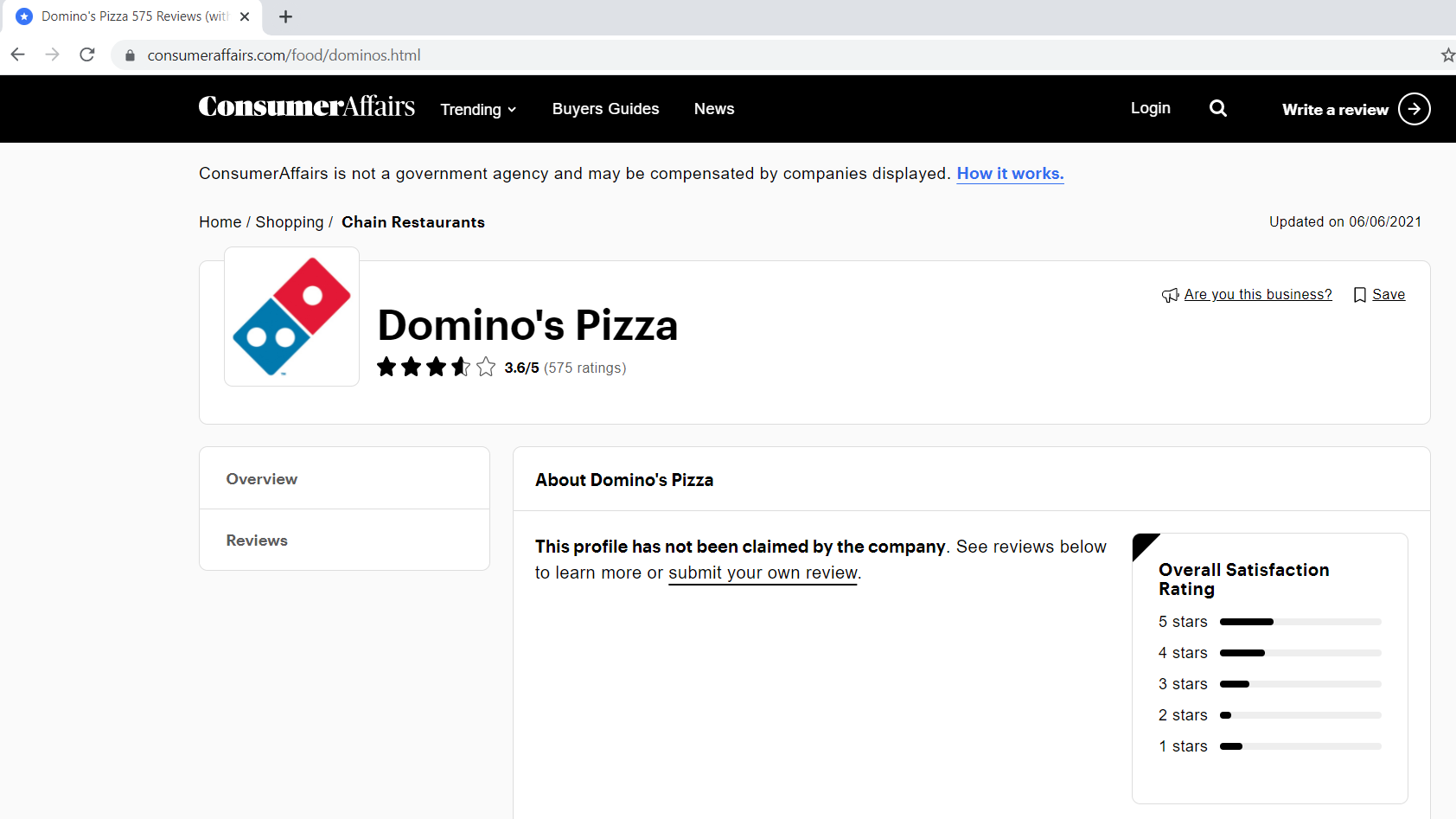
Paso 1.1: Définition de l'URL de base, paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... de consulta
L'URL de base est la partie cohérente de votre adresse Web et représente le chemin d'accès à la fonction de recherche du site Web..
base_url = "https://www.consumeraffairs.com/food/dominos.html?page="
Les paramètres de requête représentent des valeurs supplémentaires qui peuvent être déclarées sur la page.
paramètre_requête = "?page="+str(je) # je représente le numéro de page
Paso 2: sélectionner les éléments particuliers en inspectant
Ci-dessous, une image d'un exemple d'examen. Chaque avis comporte de nombreux éléments: la note donnée par l'utilisateur, l'identifiant, la date de l'avis et le texte de l'avis ainsi que des informations sur le nombre de personnes qui l'ont aimé.

Notre intérêt est d'extraire uniquement le texte de la critique. Pour ça, nous devons inspecter la page et obtenir les balises HTML, les noms des attributs de l'élément cible.
Pour inspecter une page Web, clic droit sur la page, sélectionnez Inspecter ou utilisez le raccourci clavier Ctrl + Changement + je.
Dans notre cas, le texte de l'avis est stocké dans la balise HTML
de la div avec le nom de classe "rvw-bd«
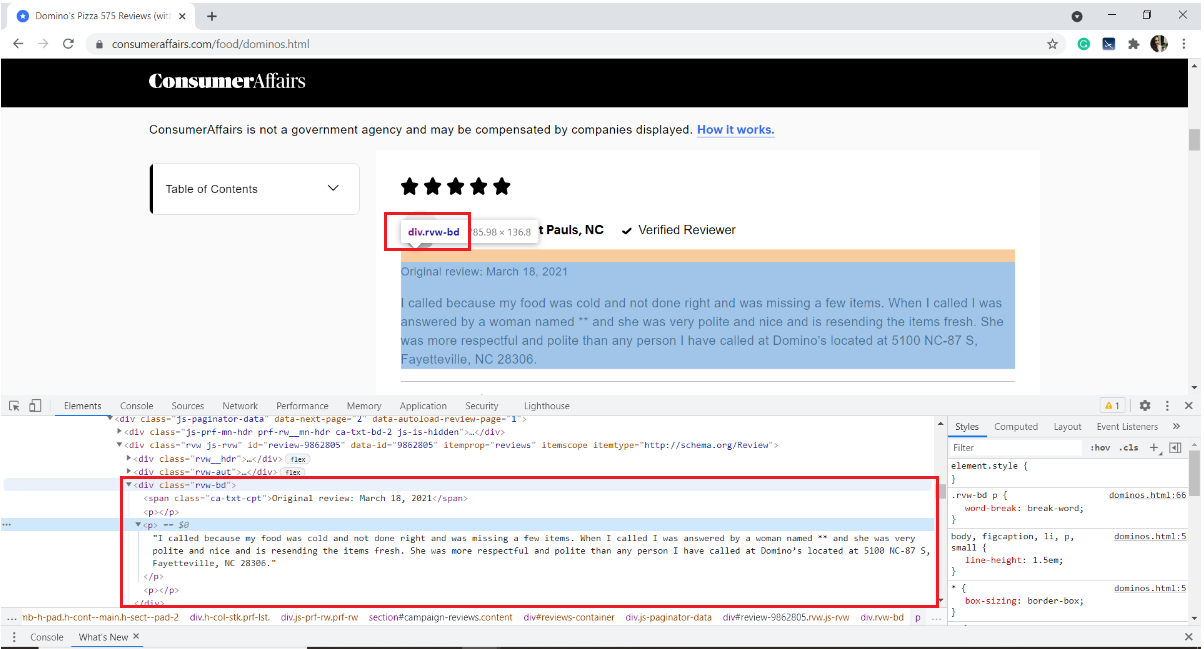
Avec ça, nous nous familiarisons avec le site Web. Passons rapidement au grattage.
Paso 3: Écrivez le code pour obtenir le contenu des éléments sélectionnés
Commencez par installer les modules / packages requis
pip installer pandas demande BeautifulSoup4
Importer les bibliothèques requises
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
pandas – pour créer un bloc de données
demandes: pour envoyer des requêtes HTTP et accéder au contenu HTML à partir de la page Web de destination
BelleSoupe: est une bibliothèque Python pour l’analyse de données HTML structurées
Créer une liste vide pour stocker tous les avis extraits
all_pages_reviews = []
définir une fonction de raclage
grattoir def():
À l’intérieur de la fonction racleur, tapez a pour que la boucle parcoure le nombre de pages que vous souhaitez gratter. J’aimerais gratter les critiques de cinq pages.
pour moi à portée(1,6):
Creando una lista vacía para almacenar las reseñas de cada página (de 1 une 5)
pagewise_reviews = []
Construye la URL
url = base_url + query_parameter
Envíe la solicitud HTTP a la URL mediante solicitudes y almacene la respuesta
réponse = requêtes.get(URL)
Cree un objeto de sopa y analice la página HTML
soup = bs(réponse.contenu, 'html.parser')
Encuentre todos los elementos div del nombre de clase « rvw-bd » y guárdelos en una variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes....
rev_div = soup.findAll("div",attrs={"classer","rvw-bd"})
Recorra todo el rev_div y agregue el texto de revisión a la lista pagewise
pour j dans la plage(longueur(rev_div)): # finding all the p tags to fetch only the review text pagewise_reviews.append(rev_div[j].trouve("p").texte)
Anexar todas las reseñas de páginas a una sola lista « all_pages about »
pour k dans la plage(longueur(pagewise_reviews)): all_pages_reviews.append(pagewise_reviews[k])
Al final de la función, devuelve la lista final de reseñas.
return all_pages_reviews
Call the function scraper() and store the output to a variable 'reviews'
# Driver code
reviews = scraper()
Paso 4: almacene los datos en el formato requerido
4.1 almacenamiento en un marco de datos de pandas
i = range(1, longueur(Commentaires)+1) reviews_df = pd.DataFrame({'revoir':Commentaires}, index=i)
Now let us take a glance of our dataset
imprimer(reviews_df)

4.2 Escribir el contenido del marco de datos en un archivo de texto
reviews_df.to_csv('avis.txt', sep = 't')
Avec ça, terminamos de extraer las reseñas y almacenarlas en un archivo de texto. mmm, es bastante simple, non?
Código Python completo:
# !pip install pandas requests BeautifulSoup4
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
base_url = "https://www.consumeraffairs.com/food/dominos.html"
all_pages_reviews =[]
-
grattoir def(): pour moi à portée(1,6): # fetching reviews from five pages pagewise_reviews = [] paramètre_requête = "?page="+str(je) url = base_url + query_parameter response = requests.get(URL) soup = bs(réponse.contenu, 'html.parser') rev_div = soup.findAll("div",attrs={"classer","rvw-bd"}) pour j dans la plage(longueur(rev_div)): # finding all the p tags to fetch only the review text pagewise_reviews.append(rev_div[j].trouve("p").texte) pour k dans la plage(longueur(pagewise_reviews)): all_pages_reviews.append(pagewise_reviews[k]) return all_pages_reviews # Driver code reviews = scraper() i = range(1, longueur(Commentaires)+1) reviews_df = pd.DataFrame({'revoir':Commentaires}, index=i) reviews_df.to_csv('avis.txt', sep = 't')
Remarques finales:
A la fin de cet article, nous avons appris le processus étape par étape d’extraction de contenu de n’importe quelle page Web et de stockage dans un fichier texte.
- inspecter l’élément cible à l’aide des outils de développement du navigateur
- utiliser des demandes pour télécharger du contenu HTML
- analyse du contenu HTML à l’aide de BeautifulSoup pour extraire les données requises
Nous pouvons développer davantage cet exemple en récupérant les noms d’utilisateur, révision du texte. Vectoriser le texte de révision propre et regrouper les utilisateurs en fonction des révisions écrites. Podemos usar Word2Vec o CounterVectorizer para convertir texto en vectores y aplicar cualquiera de los algoritmos de regroupementLe "regroupement" Il s’agit d’un concept qui fait référence à l’organisation d’éléments ou d’individus en groupes ayant des caractéristiques ou des objectifs communs. Ce procédé est utilisé dans diverses disciplines, y compris la psychologie, Éducation et biologie, faciliter l’analyse et la compréhension de comportements ou de phénomènes. Dans le domaine de l’éducation, par exemple, Le regroupement peut améliorer l’interaction et l’apprentissage entre les élèves en encourageant le travail.. de Machine Learning.
Les références:
Bibliothèque BeautifulSoup: Documentation, vidéo pas à pas
Lien vers le référentiel GitHub pour télécharger le code source
J'espère que ce blog aidera à comprendre le grattage Web en Python à l'aide de la bibliothèque BeautifulSoup. Bon apprentissage !! 😊
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





