Cet article a été publié dans le cadre du Blogathon sur la science des données.
introduction

Le Web Scraping est une méthode ou un art pour obtenir ou supprimer des données d'Internet ou de sites Web et les stocker localement sur votre système. Le Web Scripting est une stratégie programmée pour acquérir beaucoup d'informations à partir de sites.
La grande majorité de ces informations sont des informations non structurées dans une mise en page HTML qui sont ensuite converties en informations organisées dans une page de comptabilité ou un ensemble de données., il a donc tendance à être utilisé dans différentes applications. Il existe un large éventail d'approches de grattage Web pour obtenir des informations à partir de sites. Il s'agit notamment de l'utilisation d'applications Web, API spécifique o, dans tous les cas, créez votre code pour le web scraping sans aucune préparation.
De nombreux sites énormes comme Google, Twitter, Facebook, Débordement de pile, etc. avoir des API qui vous permettent d'accéder à vos informations dans une organisation organisée. C'est l'option la plus idéale, mais différents paramètres régionaux ne permettent pas aux clients d'accéder à beaucoup d'informations dans une structure organisée ou, en substance, ils ne progressent pas si mécaniquement. Par là, il est idéal d'utiliser le Web Scraping pour trouver des informations sur le site.

Les grattoirs Web peuvent extraire toutes les informations sur des destinations spécifiques ou les informations particulières dont un client a besoin. De préférence, il est idéal si vous indiquez les informations dont vous avez besoin afin que le grattoir Web concentre simplement ces informations rapidement. Par exemple, vous devriez gratter une page Amazon pour les types de presse-agrumes disponibles, cependant, Vous n'aurez peut-être besoin que des informations sur les modèles de divers presse-agrumes et non des audits des clients..
Ensuite, lorsqu'un débogueur Web a besoin de rayer un site Web, vous recevez d'abord les URL des paramètres régionaux requis. À ce moment, empiler tout le code HTML pour ces destinations et un grattoir plus développé peut même concentrer tous les composants CSS et Javascript.. À ce moment, le grattoir acquiert les informations nécessaires à partir de ce code HTML et transfère ces informations à l'organisme indiqué par le client.
Généralement, c'est comme une page de comptabilité excel ou un enregistrement csv, cependant, les informations peuvent également être stockées dans différentes organisations, par exemple, un document JSON.

Bibliothèques Python populaires pour le web scraping
- Pétitions
- Belle soupe 4
- lxml
- Sélénium
- grattant
Grattoir automatique
Il s'agit d'une bibliothèque de grattage Web Python pour rendre le grattage Web intelligent, automatique, rapide et facile. il est aussi léger, ce qui signifie que cela n'affectera pas beaucoup votre PC. Un utilisateur peut facilement utiliser cet outil de grattage de données grâce à son interface conviviale.. Pour commencer, il vous suffit d'écrire quelques lignes de code et vous verrez la magie.
Il vous suffit de fournir l'URL ou le contenu HTML de la page Web dont vous souhaitez supprimer les données., en outre, un résumé des informations de test que nous devrions supprimer de cette page. Ces informations peuvent être du texte, URL ou toute balise HTML sur cette page. Apprendre les règles à gratter par lui-même et retourner des articles similaires.
Dans cet article, nous allons enquêter sur Autoscraper et voir comment nous pouvons l'utiliser pour nous supprimer des informations.

Installation
Il y a 3 façons d'installer cette bibliothèque sur votre système.
- Installer à partir du référentiel git à l'aide de pip:
pip installer git+https://github.com/alirezamika/autoscraper.git
pip installer le grattoir automatique
python setup.py installer
Importation de la bibliothèque
Nous importerons uniquement un grattoir automatique, car il ne convient que pour gratter le web. Ci-dessous le code à importer:
à partir de l'autoscraper importer AutoScraper
Définition de la fonction de grattage Web
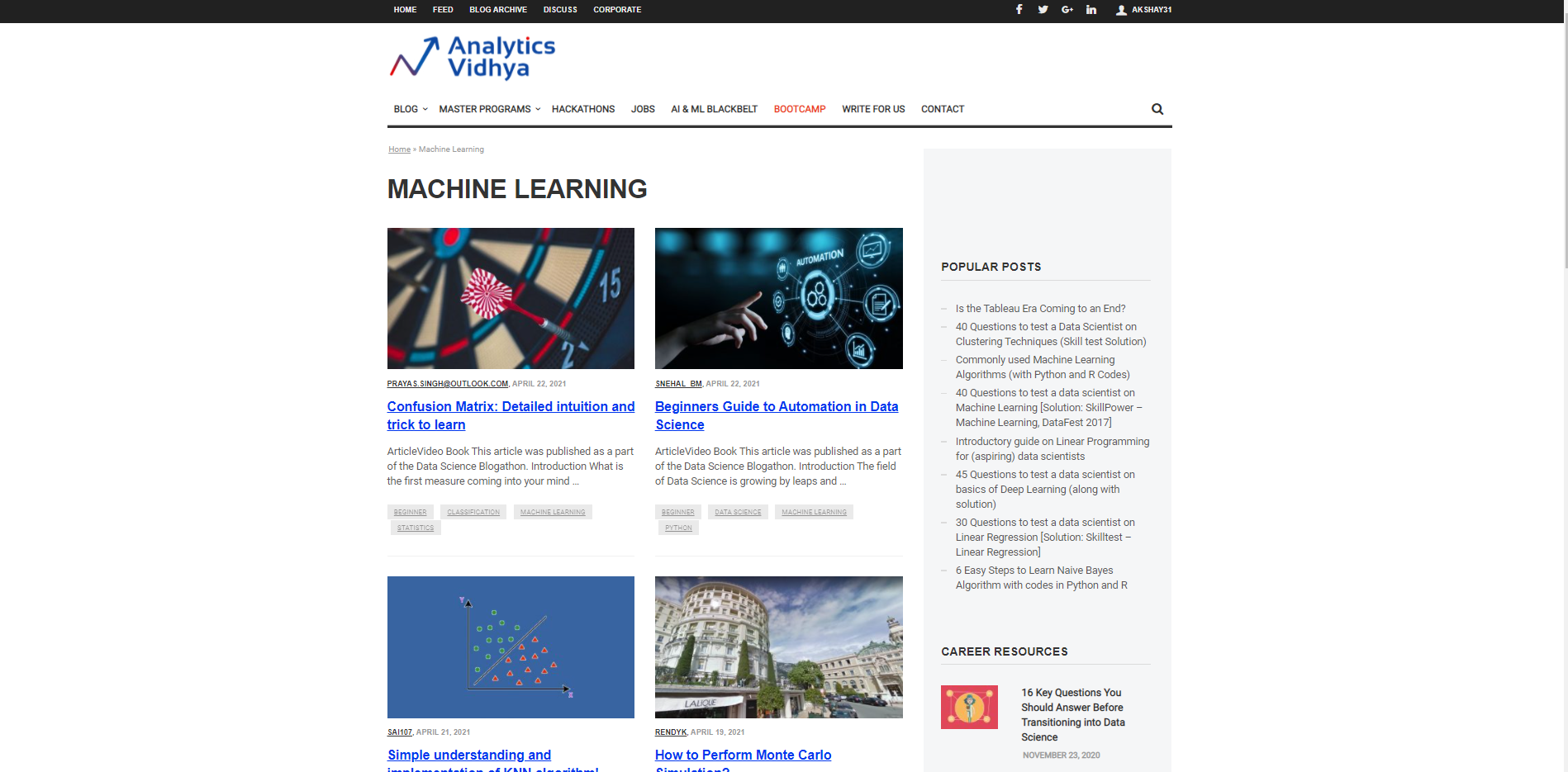
Commençons par caractériser une URL à partir de laquelle elle sera utilisée pour rentrer les informations et la preuve des informations nécessaires à apporter. Supposons que nous voulions rechercher le Titres pour différents articles sur le Machine Learning sur le site DataPeaker. Donc, nous devons passer l'URL de la section du blog d'apprentissage automatique DataPeaker et la deuxième liste de recherche. La liste des personnes recherchées est une liste qui est Exemples de données que nous voulons extraire de cette page. Par exemple, ici, la liste des personnes recherchées est le titre de n'importe quel blog de la section de blogs d'apprentissage automatique de DataPeaker.
URL="https://www.analyticsvidhya.com/blog/category/machine-learning/" liste_voulue = ['Matrice de confusion: Intuition détaillée et astuce pour apprendre']
Nous pouvons ajouter un ou plusieurs candidats à la liste recherchée. Vous pouvez également mettre des URL dans la liste recherchée pour récupérer les URL.
Démarrer l'AutoScraper
L'étape suivante après le démarrage de l'URL et de la liste recherchée consiste à appeler la fonction AutoScraper. Notre objectif est d'utiliser cette fonctionnalité pour créer le modèle de grattoir et effectuer un grattage Web sur cette page particulière..
Cela peut être démarré en utilisant le code suivant:
grattoir = AutoScraper()
Construire l'objet
Il s'agit de la dernière étape du grattage Web avec cette bibliothèque particulière. Ici, créer l'objet et afficher le résultat du grattage Web.
grattoir = AutoScraper() résultat = grattoir.build(URL, liste_voulue) imprimer(résultat)

Ici, dans l'image ci-dessus, tu peux voir qu'il revient. le titre des blogs sur le site DataPeaker dans la section machine learning, de la même manière, nous pouvons obtenir les URL des blogs en passant simplement l'exemple d'URL dans la liste de recherche que nous avons définie précédemment.
URL="https://www.analyticsvidhya.com/blog/category/machine-learning/" liste_voulue = ['https://www.analyticsvidhya.com/blog/2021/04/confusion-matrix-detailed-intuition-and-trick-to-learn/'] grattoir = AutoScraper() résultat = grattoir.build(URL, liste_voulue) imprimer(résultat)
Voici la sortie du code ci-dessus. Vous pouvez voir que j'ai passé l'url dans la liste des personnes recherchées cette fois, par conséquent, vous pouvez voir le résultat comme URL de blog

Enregistrer le modèle
Il nous permet de sauvegarder le modèle que nous devons construire pour pouvoir le recharger en cas de besoin.
Pour enregistrer le modèle, utilisez le code suivant
grattoir.sauvegarder('blogs') #Donnez-lui un chemin d’accès au fichier
Pour charger le modèle, utilisez le code suivant:
grattoir.charge('blogs')
Noter: En dehors de chacune de ces fonctionnalités, le grattoir automatique permet également de caractériser les adresses IP proxy afin de pouvoir les utiliser pour obtenir des informations. Nous devons simplement caractériser les proxys et les passer en argument à la fonction de construction comme indiqué ci-dessous:
mandataires = {
"http": 'http://127.0.0.1:8001',
"https": 'https://127.0.0.1:8001',
}
résultat = grattoir.build(URL, liste_voulue, request_args=dict(proxys = proxys))
Pour plus d'informations, voir le lien ci-dessous: Grattoir automatique
conclusion
Dans cet article, nous percevons comment nous pouvons utiliser Autoscraper pour le web scraping en créant un modèle basique et simple à utiliser. Nous avons vu plusieurs formats dans lesquels les informations peuvent être récupérées à l'aide d'Autoscraper. Nous pouvons également enregistrer et charger le modèle pour l'utiliser plus tard, ce qui économise du temps et des efforts. Le grattoir automatique est incroyable, simple d'utilisation et efficace.
Merci d'avoir lu cet article et de votre patience.. Laissez-moi dans la section commentaire sur les commentaires. Partagez cet article, cela me donnera la motivation d'écrire plus de blogs pour la communauté de la science des données.
Identification de l'e-mail: gakshay1210@ gmail.com
Suivez-moi sur LinkedIn: LinkedIn
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





