Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
Réseau de neurones récurrentsRéseaux de neurones récurrents (RNN) sont un type d’architecture de réseau neuronal conçu pour traiter des flux de données. Contrairement aux réseaux de neurones traditionnels, Les RNN utilisent des connexions internes qui permettent de mémoriser les informations des entrées précédentes. Cela les rend particulièrement utiles dans des tâches telles que le traitement du langage naturel, Traduction automatique et analyse de séries chronologiques, où le contexte et la séquence sont au cœur de la... (RNN) était l’un des meilleurs concepts introduits qui pouvaient utiliser des éléments de mémoire dans notre neuronal rougeLes réseaux de neurones sont des modèles computationnels inspirés du fonctionnement du cerveau humain. Ils utilisent des structures appelées neurones artificiels pour traiter et apprendre des données. Ces réseaux sont fondamentaux dans le domaine de l’intelligence artificielle, permettant des avancées significatives dans des tâches telles que la reconnaissance d’images, Traitement du langage naturel et prédiction de séries temporelles, entre autres. Leur capacité à apprendre des motifs complexes en fait des outils puissants... Avant que, nous avions un réseau de neurones qui pouvait se propager dans les deux sens pour mettre à jour les poids et réduire les erreurs dans le réseau. Mais, comme nous savons, de nombreux problèmes dans le monde réel sont de nature temporaire et dépendent fortement du temps.
De nombreuses applications linguistiques sont toujours séquentielles et le mot suivant dans une phrase dépend du précédent. Ces problèmes ont été résolus par un simple RNN. Mais si nous comprenons RNN, nous apprécions le fait que même RNN ne peut pas nous aider lorsque nous voulons garder une trace des mots qui ont déjà été utilisés dans notre phrase. Dans cet article, Je vais discuter de certains des principaux inconvénients de RNN et pourquoi nous utilisons un meilleur modèle pour la plupart des applications basées sur le langage.
Comprendre la rétropropagation dans le temps (BPTT)
RNN utilise une technique appelée RétropropagationLa rétropropagation est un algorithme fondamental dans l’entraînement des réseaux de neurones artificiels. Il est basé sur le principe de la descente de gradient, vous permettant d’ajuster les poids du réseau pour minimiser les erreurs de prédiction. Par la propagation de l’erreur de la couche de sortie vers les couches précédentes, Cette méthode optimise l’apprentissage en réseau, améliorer votre capacité à généraliser à des données inédites.... au fil du temps pour rétropropager à travers le réseau afin d’ajuster ses poids afin que nous puissions réduire l’erreur dans le réseau. A obtenu son nom « à travers le temps », puisque dans RNN, nous traitons des données séquentielles et chaque fois que nous revenons en arrière, c'est comme remonter le temps dans le passé. Voici comment fonctionne BPTT:
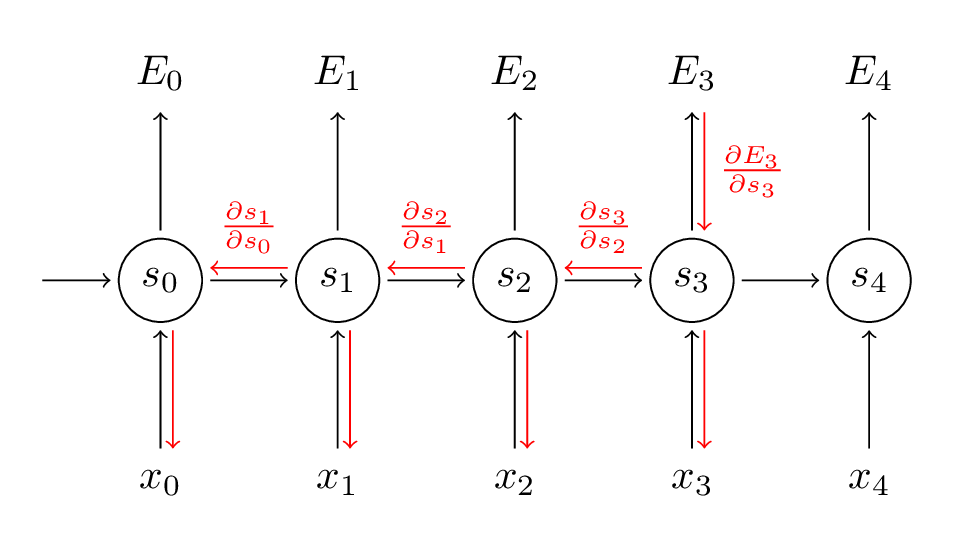
La source: (http://www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/)
A l'étape BPTT, on calcule la dérivée partielle à chaque poids du réseau. Ensuite, si on est dans le temps t = 3, alors on considère la dérivée de E3 par rapport à celle de S3. À présent, x3 est également connecté à s3. Ensuite, sa dérivée est également considérée. À présent, si on voit que s3 est connecté à s2, alors s3 dépend de la valeur de s2 et ici la dérivée de s3 par rapport à s2 est également considérée. Cela agit comme une règle de chaîne et nous accumulons toute la dépendance avec ses dérivés et l'utilisons pour calculer l'erreur.
À l’E3, nous avons un penteLe gradient est un terme utilisé dans divers domaines, comme les mathématiques et l’informatique, pour décrire une variation continue de valeurs. En mathématiques, fait référence au taux de variation d’une fonction, pendant la conception graphique, S’applique à la transition de couleur. Ce concept est essentiel pour comprendre des phénomènes tels que l’optimisation dans les algorithmes et la représentation visuelle des données, permettant une meilleure interprétation et analyse dans... qui est de S3 et son équation à ce moment est:
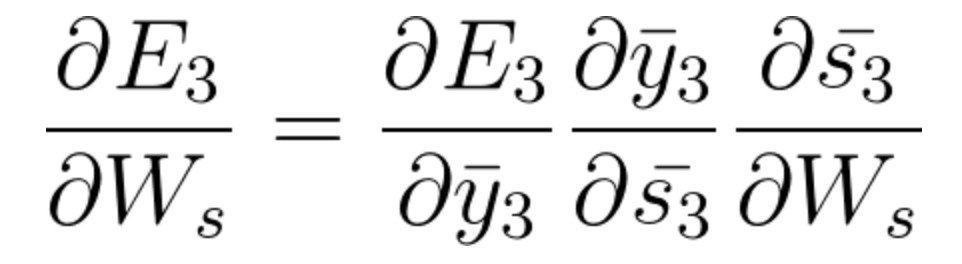
Maintenant, nous avons également s2 associé à s3 donc,
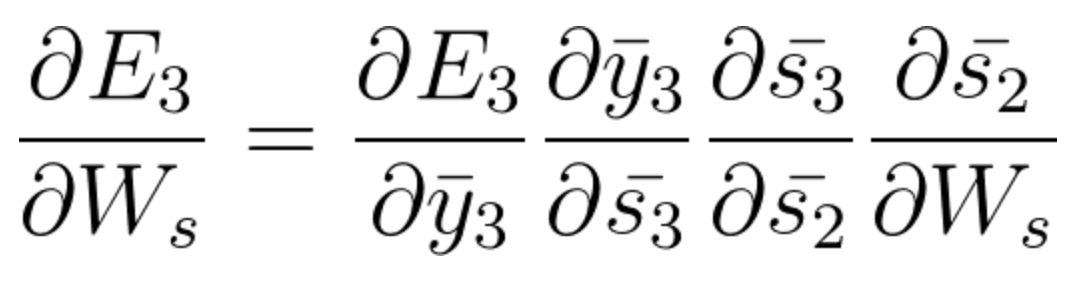
Et s1 est également associé à s2 et, donc, maintenant tout s1, s2, s3 et a un effet sur E3,
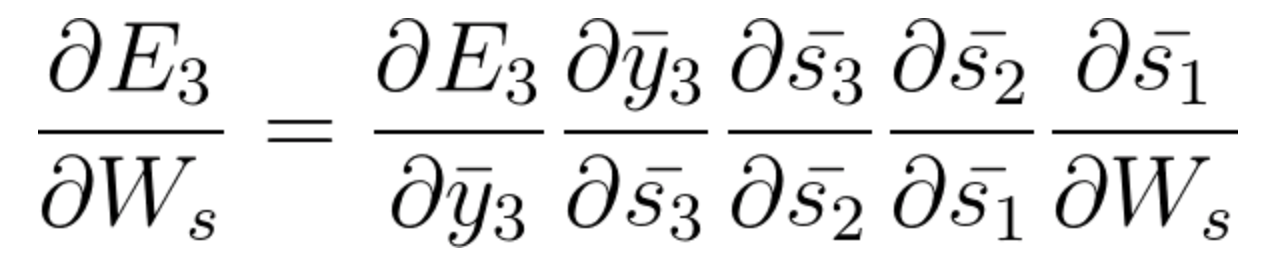
En accumulant tout, on obtient l'équation suivante que Ws a contribué à ce réseau au temps t = 3,
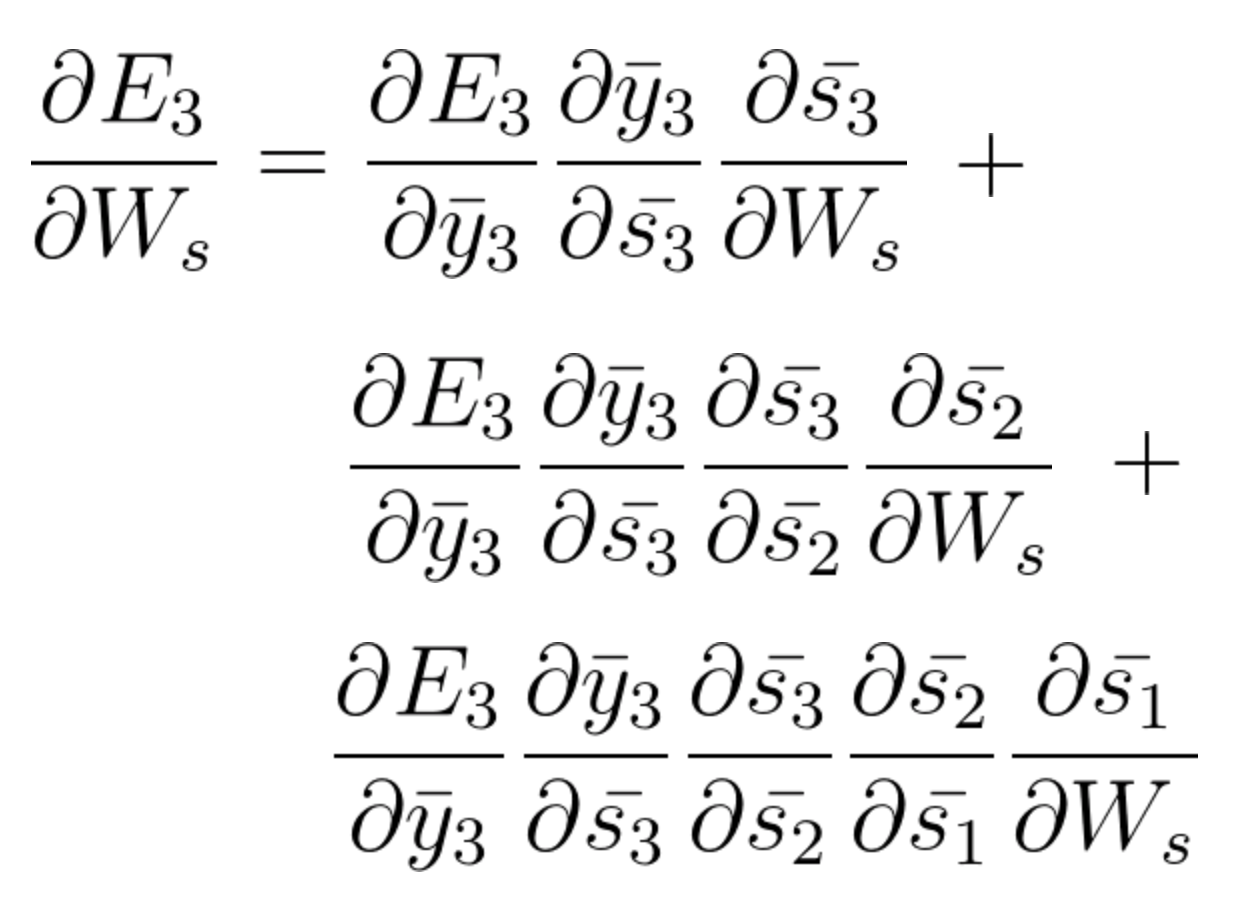
L'équation générale pour laquelle nous adaptons Ws dans notre réseau BPTT peut s'écrire sous la forme,
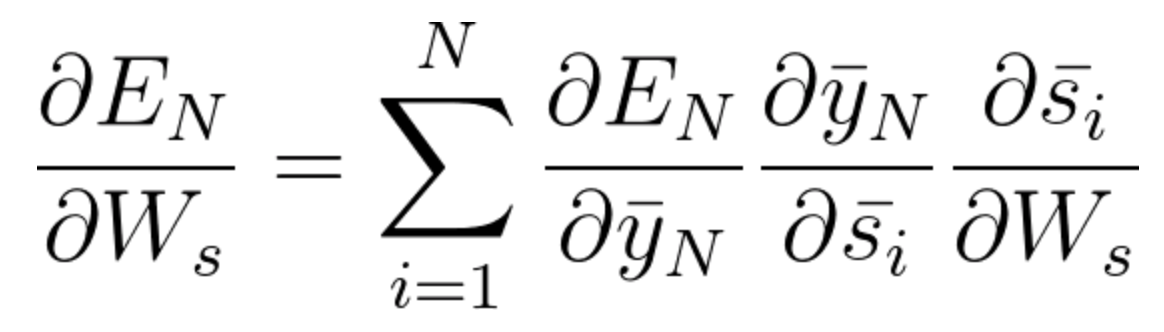
À présent, comme nous l'avons remarqué, Wx est également associé au réseau. Ensuite, en faisant de même, on peut généralement écrire,
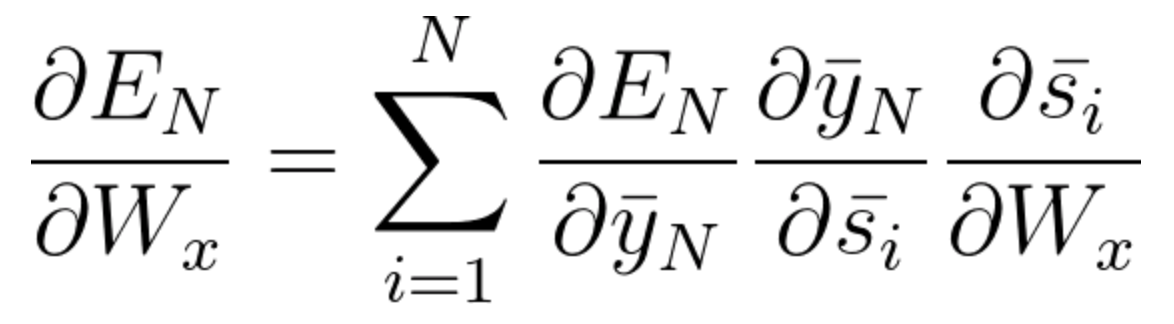
Maintenant que vous avez compris comment fonctionne BPTT, il s'agit essentiellement de la façon dont RNN ajuste ses poids et réduit l'erreur. À présent, le principal défaut ici est que ce n'est fondamentalement que pour un petit réseau avec 4 couvre. Mais imaginez si nous avions des centaines de couches et, à la fois, disons t = 100, on finirait par calculer toutes les dérivées partielles associées au réseau et c'est une énorme multiplication et cela peut réduire la valeur globale à une très petite valeur ou une valeur infime telle qu'il peut être inutile de corriger l'erreur. Ce problème s'appelle Problème de dégradé en train de disparaître.
Problème de dégradé en train de disparaître
Comme nous le savons tous, dans RNN pour prédire une sortie, nous utiliserons un fonction de réveilLa fonction d’activation est un composant clé des réseaux de neurones, puisqu’il détermine la sortie d’un neurone en fonction de son entrée. Son objectif principal est d’introduire des non-linéarités dans le modèle, vous permettant d’apprendre des modèles complexes dans les données. Il existe différentes fonctions d’activation, comme le sigmoïde, ReLU et tanh, chacun avec des caractéristiques particulières qui affectent les performances du modèle dans différentes applications.... sigmoidea afin que nous puissions obtenir la sortie de probabilité pour une classe particulière. Comme nous l'avons vu dans la section précédente quand il s'agit de dire E3, il y a une dépendance à long terme. Le problème survient quand on prend la dérivée et que la dérivée du sigmoïde est toujours en dessous 0.25 Oui, donc, quand on multiplie plusieurs dérivées ensemble selon la règle de la chaîne, on se retrouve avec une valeur de fuite telle qu'on ne peut pas les utiliser pour le calcul de l'erreur. .
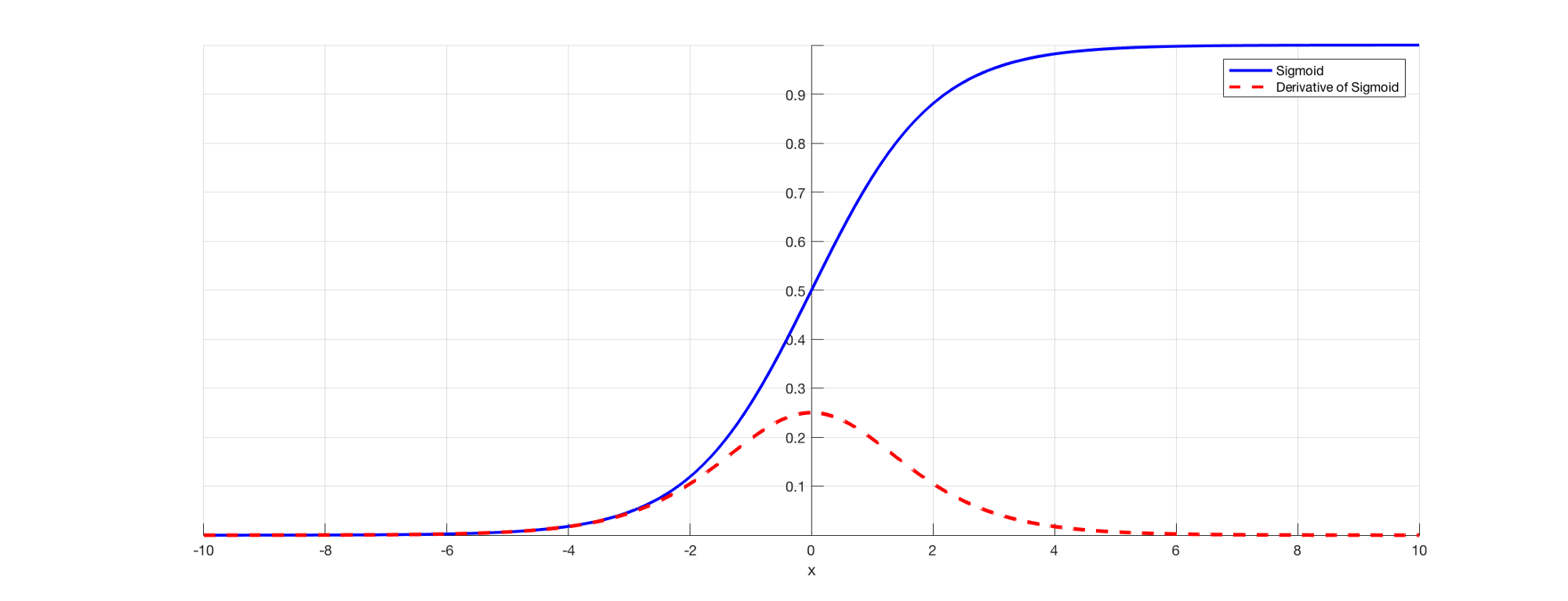
La source: (https://versdatascience.com/the-vanishing-gradient-problem-69bf08b15484)
Donc, les poids et les biais ne seront pas mis à jour correctement et, une mesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... que les couches continuent d’augmenter, nous sommes tombés plus loin et notre modèle ne fonctionne pas correctement et génère des imprécisions sur tout le réseau.
Certaines façons de résoudre ce problème sont d’initialiser correctement le tableau de poids ou d’opter pour quelque chose comme un reprendreLa fonction d’activation ReLU (Unité linéaire rectifiée) Il est largement utilisé dans les réseaux neuronaux en raison de sa simplicité et de son efficacité. Défini comme suit : ( F(X) = max(0, X) ), ReLU permet aux neurones de se déclencher uniquement lorsque l’entrée est positive, ce qui permet d’atténuer le problème de l’évanouissement en pente. Il a été démontré que son utilisation améliore les performances dans diverses tâches d’apprentissage profond, faire de ReLU une option.. au lieu des fonctions sigmoïdes ou tanh.
Problème de gradient explosif
L'explosion de gradient est un problème où la valeur du gradient devient très grande et cela se produit souvent lorsque nous initialisons des poids plus importants et que nous pourrions nous retrouver avec NaN. Si notre modèle souffrait de ce problème, nous ne pouvons pas du tout mettre à jour les poids. Mais heureusement, le recadrage en dégradé est un processus que nous pouvons utiliser pour cela. A une valeur seuil prédéfinie, on coupe le dégradé. Cela empêchera la valeur du gradient de dépasser le seuil et nous ne nous retrouverons jamais avec de grands nombres ou NaN.
Dépendance à long terme aux mots
À présent, considérons une phrase comme, "Les nuages sont dans le ____". Notre modèle RNN peut facilement prédire ‘paradis’ ici et cela est dû au contexte des nuages et très bientôt cela vient en entrée de votre couche précédente. Mais ce n'est peut-être pas toujours le cas.
Imaginez si nous avions une phrase comme: « Jane est née au Kerala. Jane avait l'habitude de jouer pour l'équipe de football féminine et a également remporté les examens de niveau de l'État. Jane parle ____ couramment « .
C'est une très longue phrase et le problème ici est que, en tant qu'humain, je peux dire que, depuis que Jane est née au Kerala et a réussi son examen d'État, il est évident que vous devez maîtriser le « malayalam » très couramment. Mais, Comment notre machine le sait-elle? Au point où le modèle veut prédire les mots, vous avez peut-être oublié le contexte du Kerala et plus d'autre chose. C'est le problème de la dépendance à long terme sur RNN.
Unidirectionnel dans RNN
Comme nous l'avons déjà commenté, RNN prend les données de manière séquentielle et mot par mot ou lettre par lettre. À présent, quand nous essayons de prédire un mot particulier, nous ne pensons pas dans son contexte futur. C'est-à-dire, disons que nous avons quelque chose comme: "La souris est vraiment bien. La souris sert à ____ pour faciliter l'utilisation des ordinateurs « . À présent, si nous pouvons voyager dans les deux sens et que nous pouvons également voir le contexte futur, on peut dire ça ‘Déplacement’ est le mot approprié ici. Mais, s'il est unidirectionnel, notre modèle n'a jamais vu d'ordinateurs, ensuite, Comment savez-vous si nous parlons de la souris animale ou de la souris d'ordinateur?
Ces problèmes sont résolus plus tard en utilisant des modèles de langage comme BERT, où nous pouvons entrer des phrases complètes et utiliser le mécanisme d'auto-attention pour comprendre le contexte du texte.
Utiliser la mémoire à court terme à long terme (LSTM)
Une façon de résoudre le problème du gradient de fuite et de la dépendance à long terme au RNN est d'opter pour les réseaux LSTM. LSTM a une introduction à trois portes appelées portes d'entrée, sortie et oubli. Dans lequel les portes de l'oubli s'occupent des informations qui doivent être autorisées à traverser le réseau. De cette façon, nous pouvons avoir une mémoire à court et à long terme. Nous pouvons transmettre les informations à travers le réseau et les récupérer même à un stade beaucoup plus tardif pour identifier le contexte de prédiction. Le schéma suivant montre le réseau LSTM.
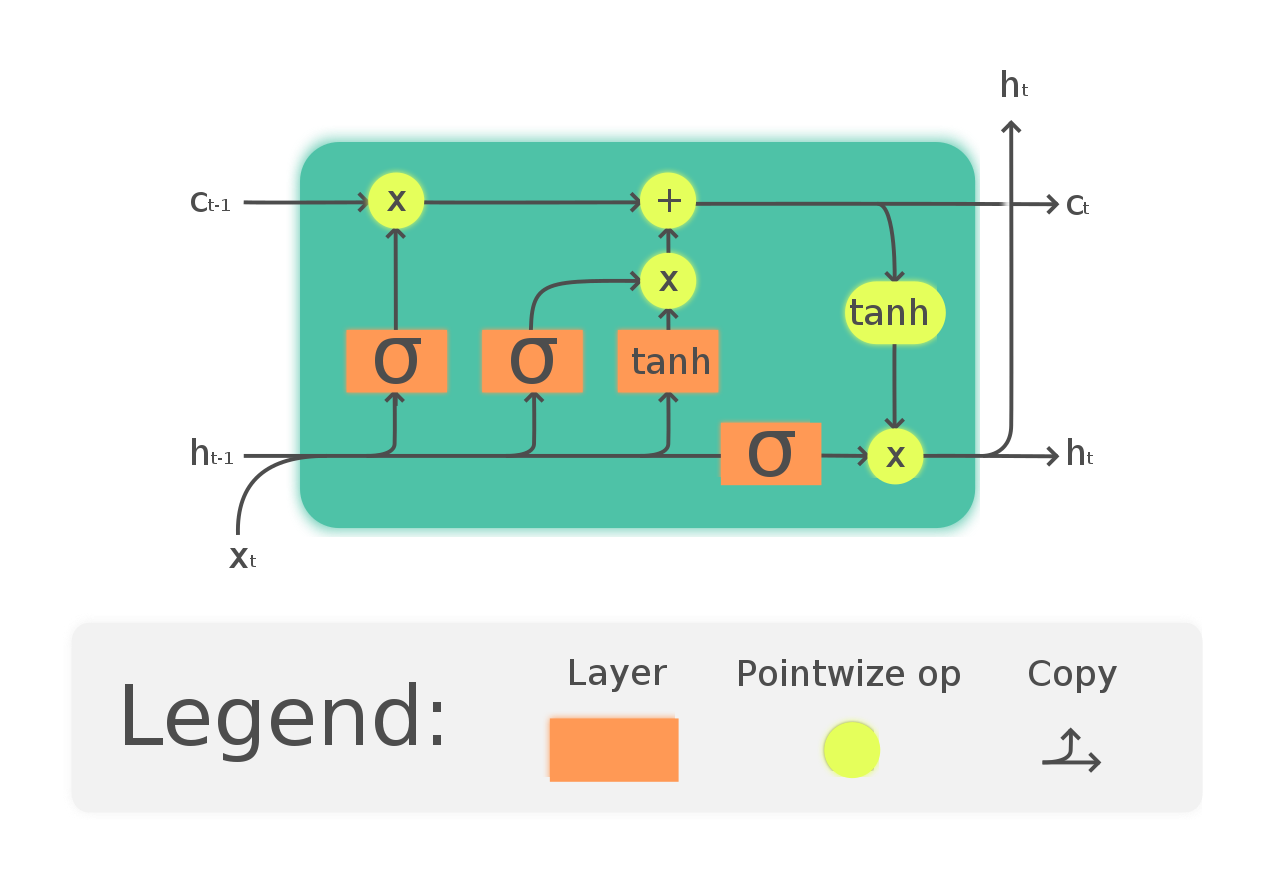
(https://en.wikipedia.org/wiki/Long_short-term_memory#/media/File:La_LSTM_Cell.svg)
Suivez ce tutoriel pour une meilleure compréhension et un exemple intuitif de LSTM: https://versdatascience.com/illustrated-guide-to-lstms-and-gru-sa-step-by-step-explanation-44e9eb85bf21
Avec chance, maintenant vous avez compris les problèmes d'utilisation d'un RNN et pourquoi nous avons opté pour des réseaux plus complexes comme LSTM.
Les références
1.http: //www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/
2. https://analyticsindiamag.com/what-are-the-challenges-of-training-recurrent-neural-networks/
3. https://versdatascience.com/the-vanishing-gradient-problem-69bf08b15484
4. https://fr.wikipedia.org/wiki/Long_short-term_memory
5. https://www.udacity.com/course/deep-learning-nanodegree–nd101
6. Aperçu de l'image: https://unsplash.com/photos/Sot0f3hQQ4Y
conclusion
N'hésitez pas à me contacter sur:
1. https://www.linkedin.com/in/siddharth-m-426a9614a/
2. https://github.com/Siddharth1698
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





