Cet article a été publié dans le cadre du Blogathon sur la science des données.
introduction
Salut! Aujourd'hui, je vais faire de mon mieux pour expliquer intuitivement comment fonctionnent les réseaux de neurones convolutifs récurrents (CRNN). Quand j'ai essayé pour la première fois d'en savoir plus sur le fonctionnement de CRNN, J'ai découvert que les informations étaient réparties sur plusieurs sites et que différents niveaux de “profondeur”, Je vais donc essayer de les expliquer de manière à ce qu'à la fin de cet article, je sache exactement comment ils fonctionnent et pourquoi ils fonctionnent mieux dans certaines catégories que dans d'autres.
Dans cet article, Je suppose que vous en savez déjà un peu sur le fonctionnement d'un simple réseau de neurones. Au cas où vous auriez besoin d'un petit examen de la façon dont cela fonctionne ou même si vous ne savez pas du tout comment ils fonctionnent, Je vous recommande de regarder les vidéos bien faites qui expliquent leur fonctionnement que j'ai liées à la fin de l'article. Je fournirai toutes les informations que vous jugez nécessaires pour comprendre intuitivement comment fonctionne CRNN.
Dans cet article, nous aborderons les sujets suivants, alors n'hésitez pas à sauter ceux que vous connaissez déjà:
- Que sont les réseaux de neurones convolutifs, comment ils fonctionnent et pourquoi nous en avons besoin?
- Que sont les réseaux de neurones récurrents, comment ils fonctionnent et pourquoi nous en avons besoin?
- · Quels sont-ils et pourquoi avons-nous besoin de réseaux de neurones récurrents convolutifs? + exemple de reconnaissance de texte manuscrit
- · Plus de lecture et de liens
Que sont les réseaux de neurones convolutifs, comment ils fonctionnent et pourquoi nous en avons besoin?
La réponse la plus simple est la dernière question, pourquoi avons-nous besoin d'eux? Pour ça, prenons un exemple. Disons que nous voulons savoir si nous avons un chat ou un chien dans l'image. Pour simplifier l'explication, Pensons d'abord à une image de 3 × 3. Dans cette image, nous avons une caractéristique importante dans le rectangle bleu (comme une tête de chien, une lettre ou toute autre caractéristique importante).
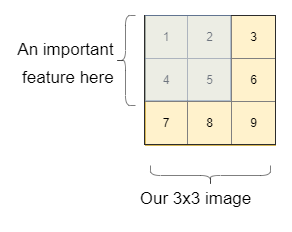
Voyons comment un simple réseau de neurones reconnaîtrait l'importance et le lien entre les pixels.
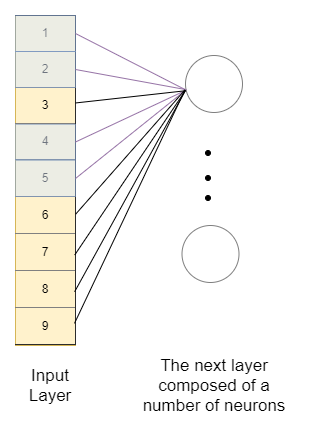
Comme nous pouvons le voir, nous aurons besoin “aplanaire” l'image pour l'alimenter dans un réseau de neurones dense. Ce faisant, nous perdons le contexte spatial dans l'image de l'élément complet avec l'arrière-plan et les éléments de l'élément les uns par rapport aux autres. Imaginez à quel point il sera difficile pour le réseau de neurones d'apprendre qu'ils sont liés. En outre, nous aurons beaucoup de poids à entraîner, nous aurons donc besoin de plus de données et, donc, plus de temps pour les former.
Ensuite, nous pouvons voir plusieurs problèmes avec cette approche:
- Le contexte spatial est perdu
- Beaucoup plus de poids pour des images plus grandes
- Plus de poids signifie plus de temps et plus de données nécessaires
Seulement s'il y avait un autre moyen... Attendez !! Il y a! C'est là que les réseaux de neurones convolutifs interviennent pour sauver la situation.. Sa fonction principale est d'extraire les caractéristiques pertinentes de l'entrée (une image, par exemple) en utilisant des filtres. Ces filtres sont d'abord choisis au hasard, puis entraînés comme le font les poids.. Ils sont modifiés par le réseau de neurones pour extraire et trouver les caractéristiques les plus pertinentes.
D'accord, nous avons jusqu'à présent établi que les réseaux de neurones convolutifs, que vais-je utiliser comme CNN, utiliser des filtres pour extraire des caractéristiques. Mais, Que sont exactement les filtres et comment fonctionnent-ils?
Les filtres sont des tableaux contenant différentes valeurs qui glissent sur l'image (par exemple) analyser les caractéristiques. Si la matrice est, par exemple, 3x3x3, l'entité extraite aura une taille de 3x3x3. Si la matrice est de taille 5 × 5, l'entité qu'il détectera aura une taille maximale de 5 × 5 sur l'image, et ainsi de suite. Lors de l'analyse d'une fenêtre de pixels, on comprend la multiplication par éléments entre le filtre et la fenêtre couverte.
Ensuite, par exemple, si nous avons une image avec une taille de 6 × 6 et un filtre 3 × 3, on peut imaginer le filtre glisser sur l'image, et chaque fois qu'il atterrit dans une nouvelle fenêtre, l'analyse, ce que nous pouvons voir représenté dans l'image ci-dessous, uniquement pour les deux premières lignes de l'image:
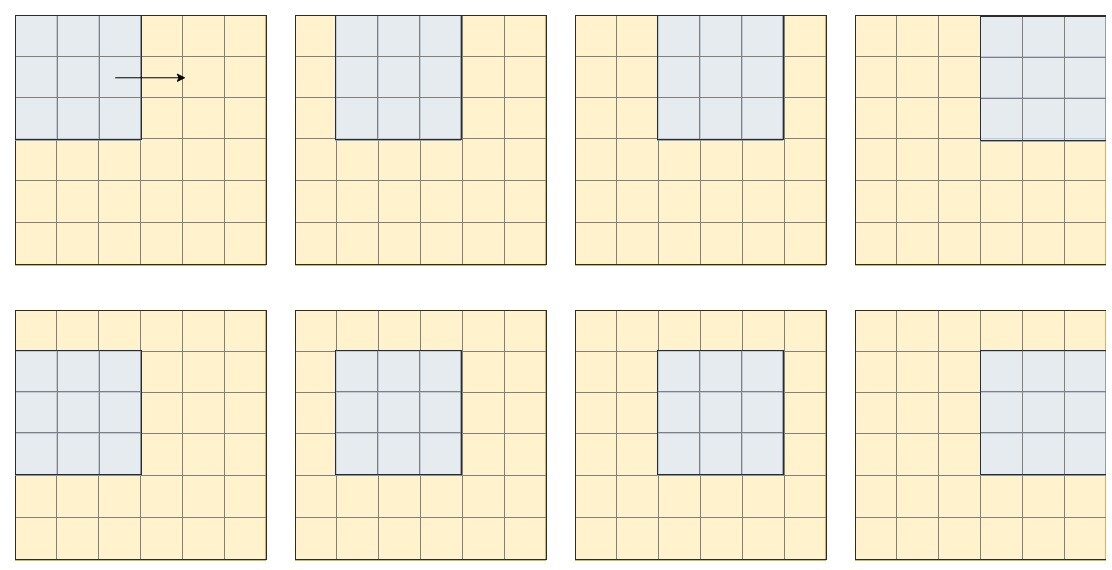
Selon ce que nous devons extraire, nous pouvons changer l'étape du filtre (à la fois verticalement et horizontalement, dans l'exemple ci-dessus, le filtre fait un pas dans les deux sens).
Après avoir fait la multiplication (par éléments), le résultat devient le nouveau pixel de l'image. Ensuite, après que “analyser” la première fenêtre, on obtient le premier pixel de notre image, et ainsi de suite. On voit que dans le cas présenté ci-dessus, l'image finale aura une taille de 5 × 5. Pour avoir l'image finale avec la même taille, nous pouvons appliquer les filtres après avoir rempli l'image de manière imaginative (ajouter une ligne et une colonne imaginaires au début et à la fin), mais les détails sont pour une autre fois à discuter.
Pour voir encore mieux comment fonctionne la convolution, nous pouvons voir des exemples de filtres et l'effet qu'ils provoquent sur l'image de sortie:

Nous pouvons voir comment différents filtres détectent et “ils extraient” caractéristiques différentes. La fonction d'entraînement d'un réseau de neurones à convolution est de trouver les meilleurs filtres pour extraire la caractéristique la plus pertinente pour notre tâche..
Ensuite, pour conclure la partie sur les réseaux de neurones à convolution, nous pouvons résumer les informations dans 3 idées simples:
- Qui sont: Les réseaux de neurones convolutifs sont un type de réseaux de neurones qui utilisent l'opération de convolution (glisser un filtre sur une image) pour extraire les caractéristiques pertinentes.
- pourquoi avons-nous besoin d'eux: mieux travailler sur les données (au lieu d'utiliser des réseaux de neurones denses normaux) où il existe une forte corrélation entre, par exemple, pixels car le contexte spatial n'est pas perdu.
- Comment travaillent-ils: utiliser des filtres pour extraire des caractéristiques. Les filtres sont des matrices qui "glissent" sur l'image. Ils sont modifiés en période de formation pour en extraire les caractéristiques les plus pertinentes.
Que sont les réseaux de neurones récurrents, comment ils fonctionnent et pourquoi nous en avons besoin?
Alors que les réseaux de neurones convolutifs nous aident à extraire les caractéristiques pertinentes de l'image, Les réseaux de neurones récurrents aident le réseau de neurones à prendre en compte les informations du passé pour faire des prédictions ou analyser.
Donc, si nous avons, par exemple, la matrice suivante: {2, 4, 6}, et nous voulons prédire ce qui viendra ensuite, nous pouvons utiliser un réseau de neurones récurrent, parce que, à chaque étape, prendra en considération ce qui était avant cela.
On peut visualiser une simple cellule récurrente, comme le montre l'image suivante:
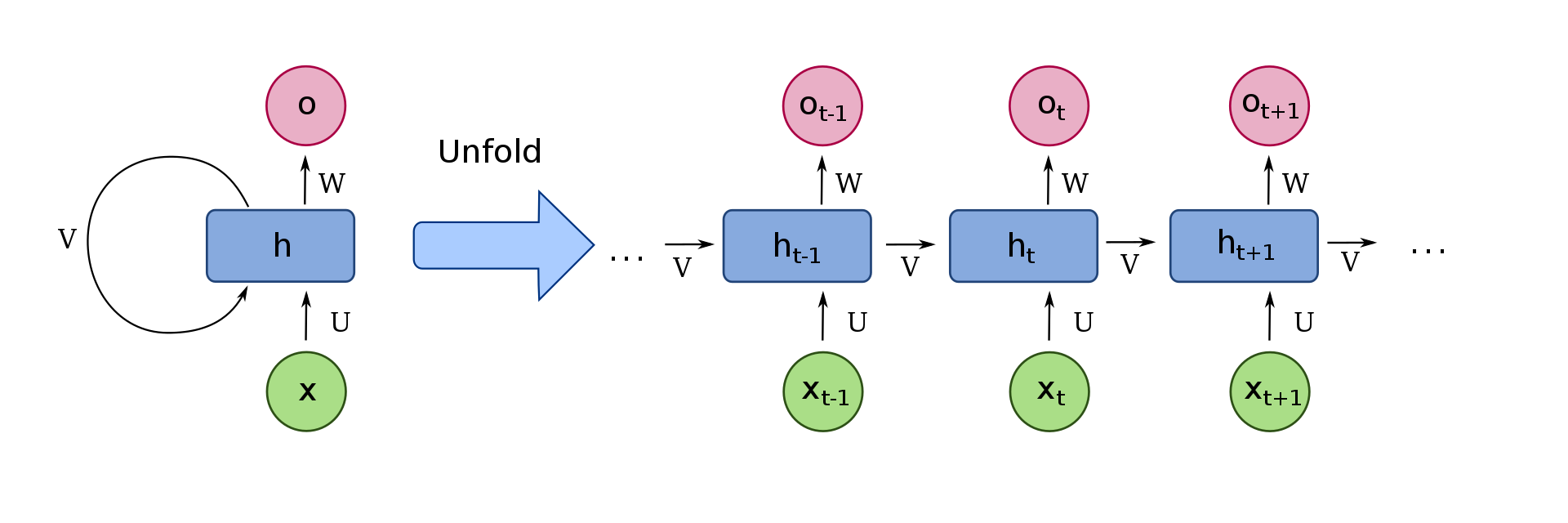
Premier, concentrons-nous simplement sur le côté droit de l'image. Ici, Xt sont les entrées reçues au pas de temps t. Pour suivre le même exemple, ceux-ci pourraient être les nombres de la matrice mentionnée ci-dessus, X0 = 2, X1 = 4, X2 = 6. Pour prendre en considération ce qui était avant le passage du temps, la propriété qui les fait partie d'un réseau de neurones récurrents, nous devons recevoir des informations du pas de temps précédent, que dans cette image nous avons représenté comme v Chaque cellule a un appel “état”, qui contient intuitivement les informations qui sont ensuite envoyées à la cellule suivante.
Ensuite, récapituler, Xt est l'entrée de la cellule. Alors, la cellule décide quelles sont les informations importantes, en tenant compte des informations des pas de temps précédents, reçu par le "v", et l'envoyer à la cellule suivante. En outre, nous avons la possibilité si nous voulons retourner cette information importante que la cellule a considérée, par “O” sur l'image, sortie de cellule.
Représenter le processus susmentionné de manière plus compacte, pouvons “replier” les cellules, représenté sur le côté gauche de l'image.
Nous n'entrerons pas dans les détails sur le type exact de cellules récurrentes, car il y a beaucoup d'options, et expliquer en détail leur fonctionnement prendrait trop de temps. Si tu es intéressé, J'ai laissé quelques liens que j'ai trouvés très utiles à la fin de l'article.
Quels sont-ils et pourquoi avons-nous besoin de réseaux de neurones récurrents convolutifs?
+ exemple de reconnaissance de texte manuscrit
Nous avons maintenant toutes les informations importantes pour comprendre comment fonctionne un réseau récurrent convolutif.
La plupart du temps, le réseau de neurones convolutifs analyse l'image et l'envoie à la partie récurrente des caractéristiques importantes détectées. L'appelant analyse ces caractéristiques afin de, en tenant compte des informations précédentes pour déterminer quels sont les liens importants entre ces caractéristiques qui influencent la sortie.
Pour comprendre un peu plus le fonctionnement d'un CRNN dans certaines tâches, Prenons l'exemple de la reconnaissance de texte manuscrit.
Imaginons que nous ayons des images qui contiennent des mots et que nous voulions entraîner le NNet à nous donner quel mot est initialement dans l'image..
En premier lieu, nous aimerions que notre réseau de neurones puisse extraire des caractéristiques importantes pour différentes lettres, comme des boucles de “g” O “je”, ou même des cercles de “une” vous “O”. Pour cela, nous pouvons utiliser un réseau de neurones convolutifs. Comme expliqué ci-dessus, CNN utilise des filtres pour extraire les fonctionnalités importantes (nous avons vu comment différents filtres ont des effets différents sur l'image initiale). Bien sûr, ces filtres détecteront en pratique des caractéristiques plus abstraites que nous ne pouvons pas vraiment comprendre, mais intuitivement, nous pouvons penser à des fonctionnalités plus simples, comme mentionné ci-dessus.
Ensuite, nous aimerions analyser ces caractéristiques. Voyons pourquoi nous ne pouvons pas décider quelle lettre est basée uniquement sur ses propres caractéristiques.. Dans l'image ci-dessous, on voit que la lettre est "a" (de “aux”) tu "o" (de pour).
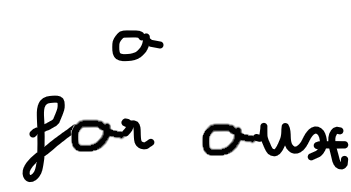
La différence réside dans la façon dont la lettre est liée aux autres lettres. Ensuite, nous aurions besoin de connaître les informations des endroits précédents dans l'image pour pouvoir déterminer la lettre. Sonne familier? C'est là qu'intervient la partie RNN. Analyser récursivement les informations extraites par CNN, où l'entrée pour chaque cellule pourrait être les caractéristiques détectées dans un segment spécifique de l'image, comme illustré ci-dessous, avec solo 10 segments (moins que ce que nous utiliserions dans de vrais modèles):
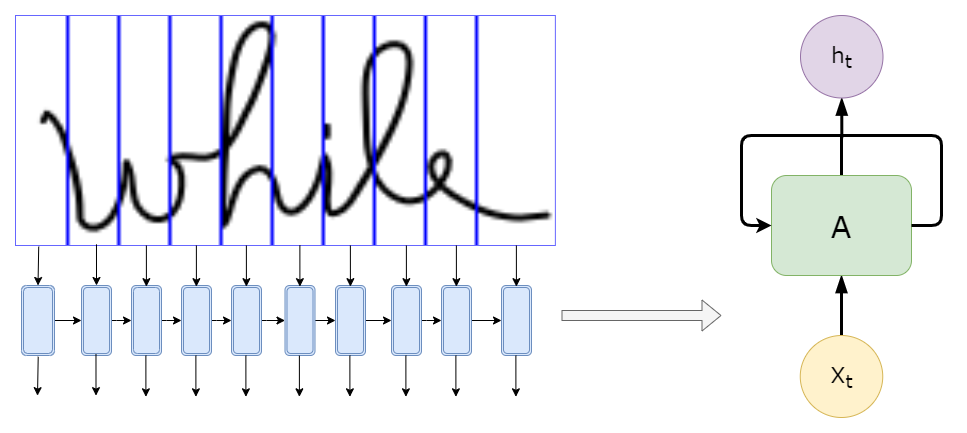
Nous n'alimentons pas le RNN avec l'image elle-même, comme le montre l'image ci-dessus, mais avec les caractéristiques qui en sont extraites “segment”.
Nous avons également pu voir que le traitement de l'image vers l'avant est tout aussi important que le traitement de l'image vers l'arrière., nous pouvons donc ajouter une couche de cellules qui traitent les fonctionnalités dans l'autre sens, en tenant compte des deux lors du calcul de la sortie. Ou même verticalement, en fonction de la tâche à effectuer.
Hourra! Enfin nous avons l'image analysée: les caractéristiques extraites et analysées les unes par rapport aux autres. Il ne nous reste plus qu'à ajouter une couche qui calcule la perte et un algorithme qui décode la sortie, pour ca, nous pouvons vouloir utiliser un CTC (Classification temporelle connexionniste) pour la reconnaissance de texte manuscrit, mais c'est un sujet intéressant en soi. et je pense qu'il mérite un autre article.
Conclusion
Dans cet article, nous discutons brièvement du fonctionnement des réseaux de neurones récurrents convolutifs, comment ils analysent et extraient les caractéristiques et un exemple de la façon dont ils pourraient être utilisés.
Le réseau de neurones convolutifs extrait les caractéristiques en appliquant des filtres pertinents et le réseau de neurones récurrent analyse ces caractéristiques, en tenant compte des informations reçues des pas de temps précédents.





