Cet article a été publié dans le cadre du Blogathon sur la science des données.
introduction
Le Big Data se caractérise souvent par: –
une) Le volume: – Le volume signifie une énorme quantité de données qui doivent être traitées.
B) La vitesse: – La vitesse à laquelle les données arrivent en tant que traitement en temps réel.
C) Véracité: – La véracité signifie la qualité des données (qui doit en fait être excellent pour générer des rapports d’analyse, etc.)
ré) Variété: – Il s’agit des différents types de données telles que
* Données structurées: – Données sous forme de tableau.
* Données non structurées: – Données non présentées sous forme de tableau
* Données semi-structurées: – Mélange de données structurées et non structurées.
Pour travailler avec de gros octets de données, Tout d’abord, nous devons stocker ou vider les données quelque part. Pourtant, La solution à ce problème est HDFSHDFS, o Système de fichiers distribués Hadoop, Il s’agit d’une infrastructure clé pour stocker de gros volumes de données. Conçu pour fonctionner sur du matériel commun, HDFS permet la distribution des données sur plusieurs nœuds, Garantir une disponibilité élevée et une tolérance aux pannes. Son architecture est basée sur un modèle maître-esclave, où un nœud maître gère le système et les nœuds esclaves stockent les données, faciliter le traitement efficace de l’information.. (sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestión de grandes volúmenes de información. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. En outre, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... Hadoop).
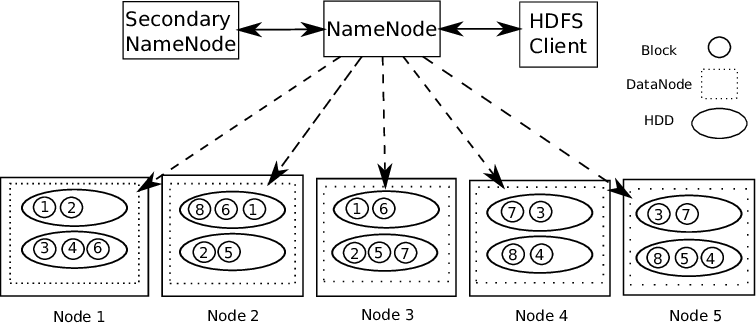
Prise en charge Hadoop Architecture maître-esclave. Il s’agit d’un type de système distribué où le traitement parallèle des données est effectué. Hadoop se compose de 1 Maître et plusieurs esclaves.
NœudNodo est une plateforme digitale qui facilite la mise en relation entre les professionnels et les entreprises à la recherche de talents. Grâce à un système intuitif, Permet aux utilisateurs de créer des profils, Partager des expériences et accéder à des opportunités d’emploi. L’accent mis sur la collaboration et le réseautage fait de Nodo un outil précieux pour ceux qui souhaitent élargir leur réseau professionnel et trouver des projets qui correspondent à leurs compétences et à leurs objectifs.... de regla de nombre: – Pour chaque bloc de données stocké, il y a 2 Exemplaires présents. Une sur différents nœuds de données et une seconde copie sur un autre nœud de données. De cette façon, Dépannage de la tolérance aux pannes.
Le nœud name contient les informations suivantes: –
1) Informations de métadonnées pour les fichiers stockés sur les nœuds de données. Les métadonnées se composent de 2 enregistrements: FsImage et EditLogs. FsImage se compose de l’état complet du système de fichiers depuis le début du nœud de nom. EditLogs contient les modifications récentes apportées au système de fichiers.
2) Emplacement du bloc de fichiers stocké dans le nœud de données.
3) Taille du fichier.
Le nœud de données contient les données réelles.
Donc, Prise en charge HDFS intégrité des données. L’exactitude ou non des données stockées est vérifiée en comparant les données à votre somme de contrôle. Si des défauts sont détectés, Le nom node est signalé. Donc, crée des copies supplémentaires des mêmes données et supprime les copies corrompues.
HDFS se compose de donc le journal d'édition a peut-être augmenté en taille qui fonctionne en même temps que le nœud de nom principal en tant que démon auxiliaire. Pas un nœud de nom de sauvegarde. Lit en permanence tous les systèmes de fichiers et les métadonnées de la RAM du nœud de nom sur le disque dur. Il est responsable de la combinaison d’EditLogs avec le FSImage du nœud de nom.
Donc, HDFS est comme un entrepôt de données où nous pouvons vider n’importe quel type de données. El procesamiento de estos datos requiere herramientas de Hadoop como RucheHive es una plataforma de redes sociales descentralizada que permite a sus usuarios compartir contenido y conectar con otros sin la intervención de una autoridad central. Utiliza tecnología blockchain para garantizar la seguridad y la propiedad de los datos. A diferencia de otras redes sociales, Hive permite a los usuarios monetizar su contenido a través de recompensas en criptomonedas, lo que fomenta la creación y el intercambio activo de información.... (pour la gestion de données structurées), HBaseHBase es una base de datos NoSQL diseñada para manejar grandes volúmenes de datos distribuidos en clústeres. Basada en el modelo de columnas, permite un acceso rápido y escalable a la información. HBase se integra fácilmente con Hadoop, lo que la convierte en una opción popular para aplicaciones que requieren almacenamiento y procesamiento de datos masivos. Su flexibilidad y capacidad de crecimiento la hacen ideal para proyectos de big data.... (pour le traitement de données non structurées), etc. Hadoop soutient le concept « Écrire une fois, Prêt pour de nombreux ».
Ensuite, Prenons un exemple et comprenons comment nous pouvons traiter une énorme quantité de données et effectuer de nombreuses transformations à l’aide du langage Scala.
UNE) Configuration de l’IDE Eclipse avec la configuration Scala.
Lien pour télécharger eclipse IDE – https://www.eclipse.org/downloads/
Vous devez télécharger l’IDE Eclipse en gardant à l’esprit les exigences de votre ordinateur. Au démarrage de l’IDE Eclipse, Vous verrez ce type d’écran.

Aller à Aider -> Marché Eclipse -> Chercher -> Scala-Ide -> Installer sur pc
Après cela dans l’IDE Eclipse – sélectionner Perspective ouverte -> Scala, Vous obtiendrez tous les composants SCALA dans l’IDE à utiliser.
Créez un nouveau projet dans Eclipse et mettez à jour le fichier pom en procédant comme suit:https://medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883
Changez la version de la bibliothèque scala en faisant un clic droit sur Projet -> Chemin de construction -> Configurer le chemin de build.
Mettez à jour le projet en faisant un clic droit sur Projet -> Maven -> Mettre à jour le projet Maven -> Forcer l’actualisation de l’instantané / versions. Donc, Le fichier POM est enregistré et toutes les dépendances requises sont téléchargées pour le projet.
Après cela, télécharger la version Spark avec les winutils Hadoop placés sur le chemin d’accès à la corbeille. Suivez ce chemin pour terminer la configuration: https://stackoverflow.com/questions/25481325/how-to-set-up-spark-on-windows
B) Création de sessions Spark – 2 les types.
Spark Session es el punto de entrada o el comienzo para crear RDD’S, Trame de données, Datasets. Pour créer une application Spark, primero necesitamos una sessionLa "Session" C’est un concept clé dans le domaine de la psychologie et de la thérapie. Fait référence à une rencontre programmée entre un thérapeute et un client, où les pensées sont explorées, Émotions et comportements. La durée et la fréquence de ces séances peuvent varier, et son objectif principal est de faciliter la croissance personnelle et la résolution de problèmes. L’efficacité des séances dépend de la relation entre le thérapeute et le thérapeute.. de chispa.
Spark Session peut être 2 les types: –
une) Séance Spark normale: –
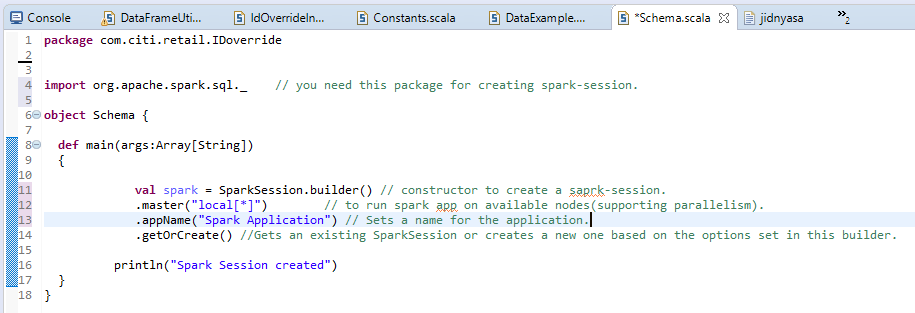
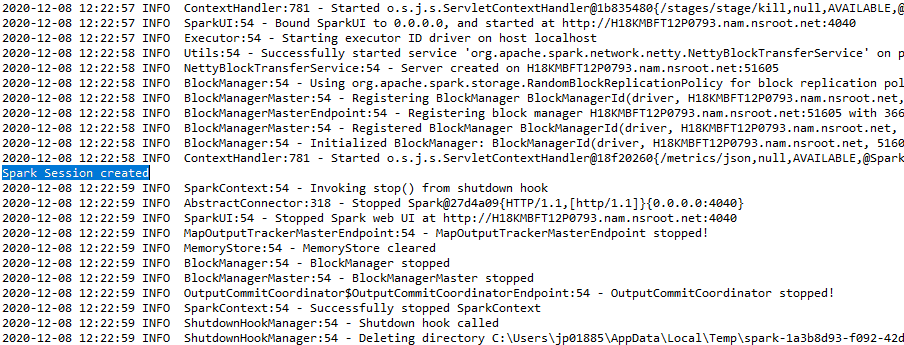
La sortie s’affichera sous la forme: –
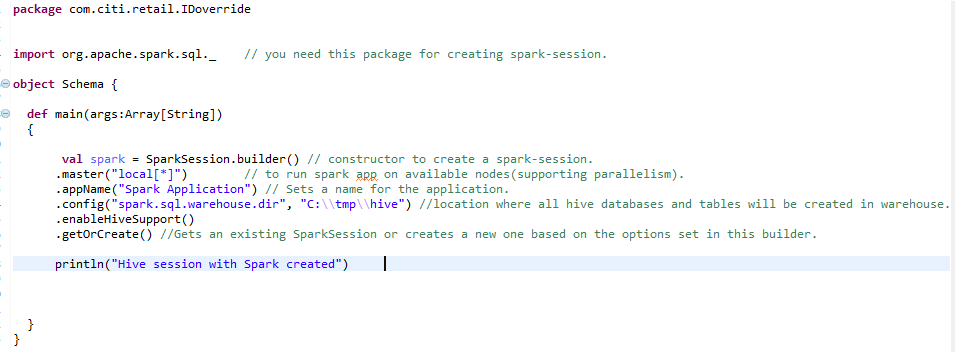
b) Session Spark pour l’environnement Hive: –
Pour créer un environnement de ruche à grande échelle, Nous avons besoin de la même session d’étincelle avec une ligne supplémentaire ajoutée. enableHiveSupport () – activer la prise en charge de Hive, y compris la connectivité au metastore Hive persistant, Prise en charge de Hive Serde et fonctions définies par l’utilisateur Hive.
C) Creación de RDD (Ensemble de données distribué résilient)RDD (Ensemble de données distribué résilient) es una abstracción fundamental en Apache Spark que permite el procesamiento eficiente de grandes volúmenes de datos. Se caracteriza por su capacidad para ser tolerante a fallos, permitiendo la recuperación de datos perdidos mediante la reconstrucción de particiones. Los RDD son inmutables, lo que facilita la paralelización de operaciones y mejora el rendimiento en la computación distribuida. Su uso es esencial para el análisis de datos... et la transformation de RDD en DataFrame: –
Ensuite, après la première étape de la création de Spark-Session, nous sommes libres de créer des RDD, Jeux de données ou trames de données. Il s’agit des structures de données dans lesquelles nous pouvons stocker de grandes quantités de données.
Élastique:- Cela signifie Fault Tolerance afin qu’ils puissent recalculer les partitions manquantes ou endommagées en raison de défaillances de nœuds.
Partitionné:- signifie que les données sont réparties sur plusieurs nœuds (Le pouvoir du parallélisme).
Ensembles de données: – Données qui peuvent être téléchargées en externe et qui peuvent se présenter sous n’importe quelle forme, c'est-à-dire, JSONJSON, o Notation d’objet JavaScript, Il s’agit d’un format d’échange de données léger, facile à lire et à écrire pour les humains, et facile à analyser et à générer pour les machines. Il est couramment utilisé dans les applications Web pour envoyer et recevoir des informations entre un serveur et un client. Sa structure est basée sur des paires clé-valeur, ce qui le rend polyvalent et largement adopté dans le développement de logiciels.., CSV ou fichier texte.
Les caractéristiques des RDD sont les suivantes: –
une) Calcul en mémoire: – Après avoir effectué des transformations de données, les résultats sont stockés dans la RAM plutôt que sur le disque. Donc, RDD ne peut pas utiliser de grands ensembles de données. La solution à ce problème est, au lieu d’utiliser RDD, L’utilisation de DataFrame est prise en compte / Jeu de donnéesUn "base de données" ou ensemble de données est une collection structurée d’informations, qui peut être utilisé pour l’analyse statistique, Apprentissage automatique ou recherche. Les ensembles de données peuvent inclure des variables numériques, catégorique ou textuelle, Et leur qualité est cruciale pour des résultats fiables. Son utilisation s’étend à diverses disciplines, comme la médecine, Économie et sciences sociales, faciliter la prise de décision éclairée et l’élaboration de modèles prédictifs.....
B) Évaluations paresseuses: – Cela signifie que les actions des transformations effectuées ne sont évaluées que lorsque la valeur est nécessaire.
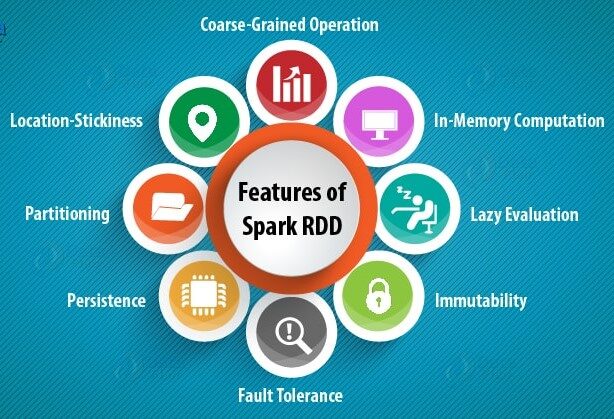
C) Tolérance aux pannes: – Les RDD Spark sont tolérants aux pannes car ils suivent les informations de traçabilité des données pour reconstruire automatiquement les données perdues en cas de défaillance.
ré) Immuabilité: – Données immuables (Non modifiable) Ils peuvent toujours être partagés en toute sécurité entre plusieurs processus. Nous pouvons recréer le RDD à tout moment.
moi) Fractionnement: – Cela signifie diviser les données, Ainsi, chaque partition peut être exécutée par différents nœuds, Ainsi, le traitement des données devient plus rapide.
F) Persistance:- Les utilisateurs peuvent choisir les RDD qu’ils doivent utiliser et choisir une stratégie de stockage pour eux.
gramme) Exploitation des céréales secondaires: – Cela signifie que lorsque les données sont divisées en différents clusters pour différentes opérations, podemos aplicar transformaciones una vez para todo el grappeUn cluster est un ensemble d’entreprises et d’organisations interconnectées qui opèrent dans le même secteur ou la même zone géographique, et qui collaborent pour améliorer leur compétitivité. Ces regroupements permettent le partage des ressources, Connaissances et technologies, favoriser l’innovation et la croissance économique. Les grappes peuvent couvrir une variété d’industries, De la technologie à l’agriculture, et sont fondamentaux pour le développement régional et la création d’emplois.... y no para diferentes particiones por separado.
ré) Utilisation de la structure de données et exécution de transformations: –
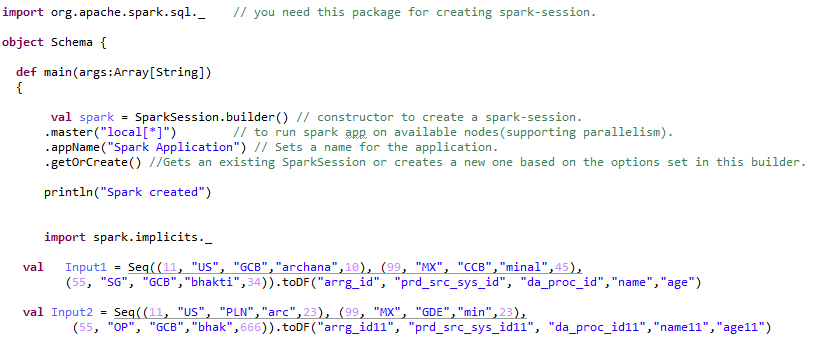
Lors de la conversion d’un RDD en trames de données, doit ajouter Importer spark.implicits._ Après l’étincelle session.
Le cadre de données peut être créé de plusieurs façons. Voyons les différentes transformations qui peuvent être appliquées au cadre de données.
Paso 1:- Création d’un cadre de données: –
Paso 2:- Exécution de différents types de transformations dans un cadre de données: –
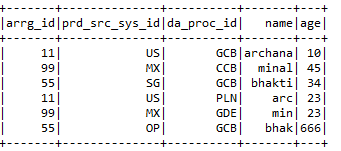
une) Veuillez sélectionner:- Sélectionnez les colonnes requises dans le bloc de données dont l’utilisateur a besoin.
Entrée1.select (« arrg_id », « da_proc_id »). Spectacle ()

B) selectExpr: – Sélectionnez les colonnes requises et renommez-les.
Entrée2.selectExpr (« arrg_id11 », « prd_src_sys_id11 comme prd_src_new », « da_proc_id11 »). Spectacle ()

C) avec colonne: – withColumns permet d’ajouter une nouvelle colonne avec la valeur particulière que l’utilisateur souhaite dans le bloc de données sélectionné.
Entrée1.avecColonne (« New_col », illuminé (nul))

ré) withColumnRenamed: – Renommez les colonnes de la trame de données particulière dont l’utilisateur a besoin.
Input1.withColumnRenamed (« da_proc_id », « da_proc_id_newname »)

moi) tomber:- Supprimer les colonnes dont l’utilisateur ne veut pas.
Entrée2.drop (« arrg_id11", » prd_src_sys_id11", « da_proc_id11 »)
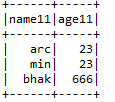
F) Connexion:- Unit 2 trames de données avec les clés de jointure des deux trames de données.
Entrée1.joindre (Entrée2, entrée1.col (« arrg_id ») === Entrée2.col (« arrg_id11"), » droit « )
.avecColonne (« prd_src_sys_id », illuminé (nul))
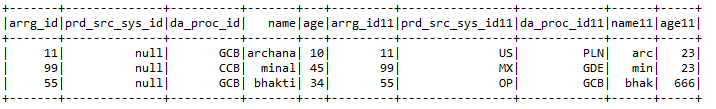
gramme) Fonctionnalités ajoutées:- Certaines des fonctionnalités ajoutées incluent
* Raconter:- Donne le nombre d’une colonne particulière ou le nombre de la trame de données dans son ensemble.
imprimer (Entrée1.count ())
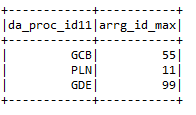
* Max .: – Donne la valeur maximale de la colonne en fonction d’une condition particulière.
input2.groupPar (« da_proc_id »). max (« arrg_id »). withColumnRenamed (« max (arrg_id) »,
« Arrg_id_max »)
* Min: – Donne une valeur minimale de la colonne dans le bloc de données.

h) filtre: – Filtrer les colonnes d’une trame de données en exécutant une condition particulière.

je) printSchéma: – Fournit des détails tels que les noms de colonne, Types de données de colonne et possibilité d’annulation ou non d’une colonne.
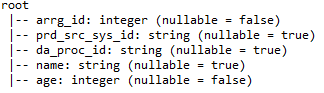
j) Union: – Combinez les valeurs de 2 trames de données tant que les noms de colonne des deux trames de données sont identiques.
MOI) Ruche:-
Hive est l’une des bases de données les plus utilisées dans le Big Data. Il est une sorte de base de donnéesUne base de données est un ensemble organisé d’informations qui vous permet de stocker, Gérez et récupérez efficacement les données. Utilisé dans diverses applications, Des systèmes d’entreprise aux plateformes en ligne, Les bases de données peuvent être relationnelles ou non relationnelles. Une bonne conception est essentielle pour optimiser les performances et garantir l’intégrité de l’information, facilitant ainsi la prise de décision éclairée dans différents contextes.... relacional donde los datos se almacenan en formato tabular. La base de données par défaut de la ruche est la Derby. Processus de la ruche Structuré et semi-structuré Les données. En cas de données non structurées, Tout d’abord, créez une table dans la ruche et chargez les données dans la table, ainsi structuré. Hive prend en charge tous les types de données primitives SQL.
Supports de ruche 2 types de tableaux: –
une) Tables gérées: – Il s’agit de la table par défaut dans Hive. Lorsque l’utilisateur crée une table dans Hive sans la spécifier comme externe, par défaut, une table interne est créée à un emplacement spécifique dans HDFS.
Par défaut, Une table interne sera créée dans un chemin de dossier similaire à / Nom d'utilisateur / ruche / Stock Répertoire HDFS. Nous pouvons remplacer l’emplacement par défaut par la propriété location lors de la création de la table.
Si nous éliminons la table ou la partition gérée, les données de table et les métadonnées associées à cette table seront supprimées du HDFS.
B) Table externe: – Les tables externes sont stockées en dehors du répertoire du coffre-fort. Ils peuvent accéder aux données stockées dans des sources telles que des emplacements HDFS distants ou des volumes de stockage Azure.
Chaque fois que nous laissons tomber le panneau extérieur, Seules les métadonnées associées à la table seront supprimées, les données de la table restent intactes par Hive.
Nous pouvons créer la table externe en spécifiant l’attribut EXTERNE dans l’instruction de la table de création Hive.
Commande de création d’une table externe.
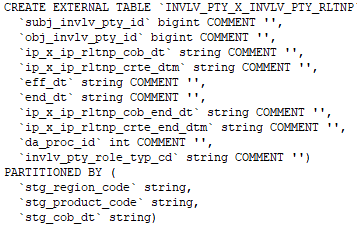
Commande permettant de vérifier si la table créée est externe ou non: –
DESC formaté