Cet article a été publié dans le cadre du Blogathon sur la science des données.
Qu'est-ce que l'apprentissage automatique?
Apprentissage automatique: Apprentissage automatique (ML) est un processus hautement itératif et ML Les modèles sont tirés des expériences passées et aussi pour analyser les données historiques. En outre, Les modèles ML peuvent identifier des modèles pour faire des prédictions sur l'avenir de l'ensemble de données donné.

WPourquoi l'apprentissage automatique est-il important?
Puisque le 5V domine le monde numérique d'aujourd'hui (le volume, variété, variance et visibilité de la valeur), la plupart des industries développent divers modèles pour analyser leur présence et leurs opportunités sur le marché, sur la base de ce résultat, ils livrent les meilleurs produits. services à vos clients à grande échelle.
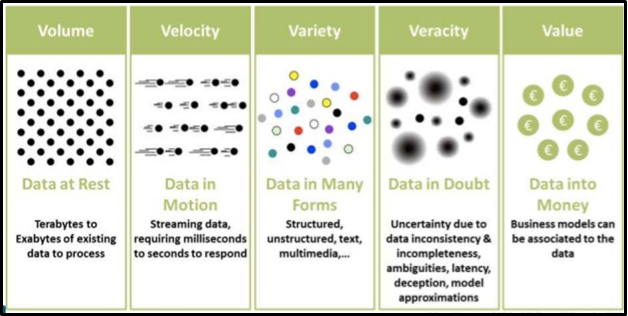
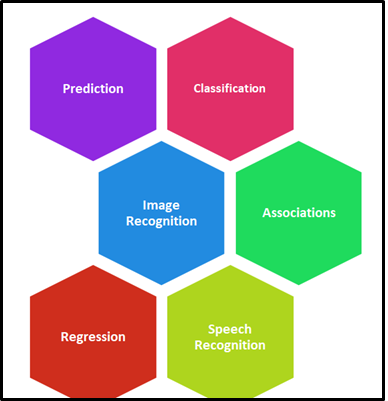
Quelles sont les principales applications d'apprentissage automatique?
Apprentissage automatique (ML) est largement applicable dans de nombreuses industries et la mise en œuvre et l'amélioration de leurs processus. Actuellement, ML a été utilisé dans plusieurs domaines et industries sans limites. La siguiente chiffre"Chiffre" est un terme utilisé dans divers contextes, De l’art à l’anatomie. Dans le domaine artistique, fait référence à la représentation de formes humaines ou animales dans des sculptures et des peintures. En anatomie, désigne la forme et la structure du corps. En outre, en mathématiques, "chiffre" Il est lié aux formes géométriques. Sa polyvalence en fait un concept fondamental dans de multiples disciplines.... representa el área donde ML juega un papel vital.
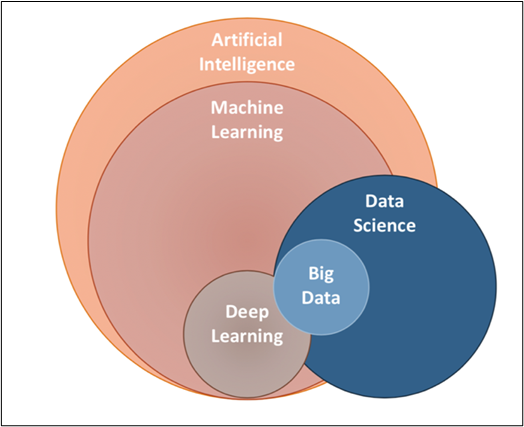
Où est l'apprentissage automatique dans l'espace de l'IA?
Jetez juste un coup d'œil à la Diagramme de Venn, nous pourrions comprendre où se situe le ML dans l'espace de l'IA et comment il se rapporte aux autres composants de l'IA.
Comment connaissons-nous les jargons qui volent autour de nous, voyons rapidement de quoi parle exactement chaque composant.
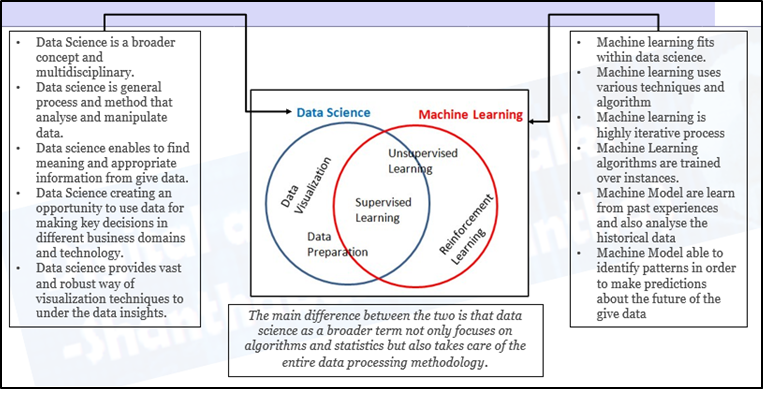
Comment la science des données et l'apprentissage automatique sont-ils liés?
Processus d'apprentissage automatique, est la première étape du processus de ML pour extraire des données de plusieurs sources et suivie d'un traitement de données affiné, ces données seraient la source des algorithmes de ML basés sur l'énoncé du problème, comme les modèles prédictifs, classements et autres disponibles dans l'espace mondial ML. Discutons de chaque processus un par un ici.
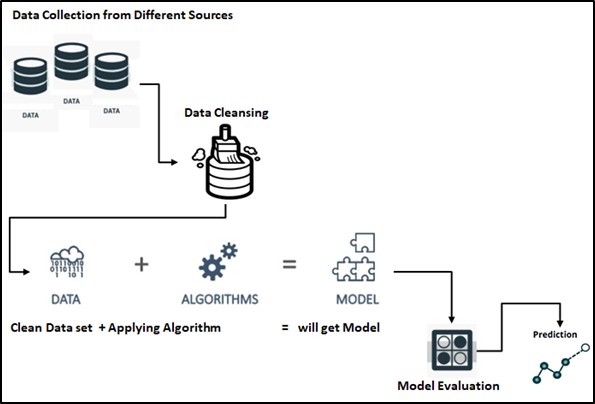
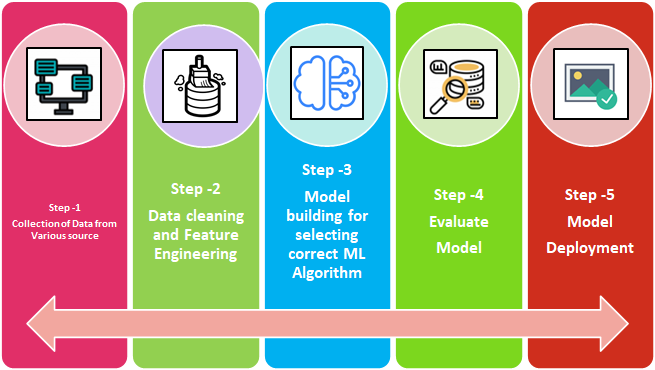
Apprentissage automatique – Etapas: Nous pouvons diviser les étapes du processus des AA en 5 comme mentionné ci-dessous dans l'organigramme.
- Base de données
- Négociation de données
- Construction du modèle
- Évaluation du modèle
- Déploiement du modèle
Identification des problèmes commerciaux, avant de passer aux étapes précédentes. Ensuite, nous devons être clairs sur l'objectif de la finalité de la mise en œuvre de la ML. Trouver la solution au problème donné / identifié. nous devons collecter les données et surveiller correctement les prochaines étapes.
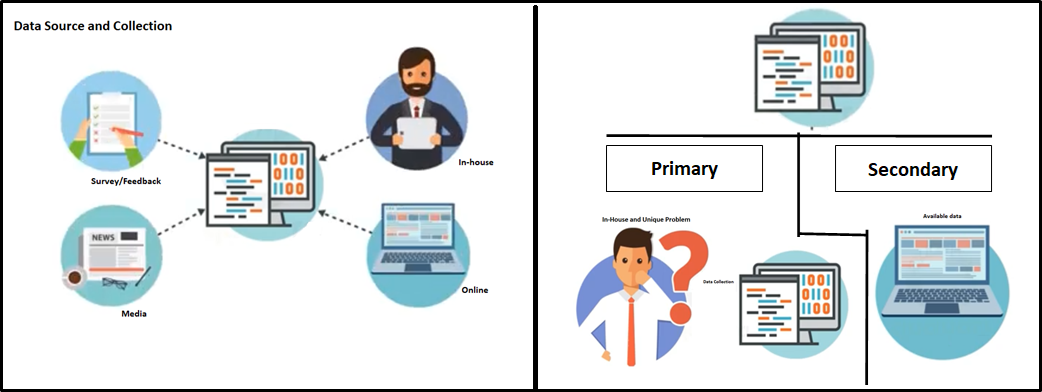
Base de données
La collecte de données provenant de différentes sources peut être interne et / ou externe pour répondre aux exigences / problèmes commerciaux. Les données peuvent être dans n'importe quel format. CSV, XML.JSON, etc., ici, le Big Data joue un rôle essentiel pour s'assurer que les données correctes sont dans le format et la structure attendus.
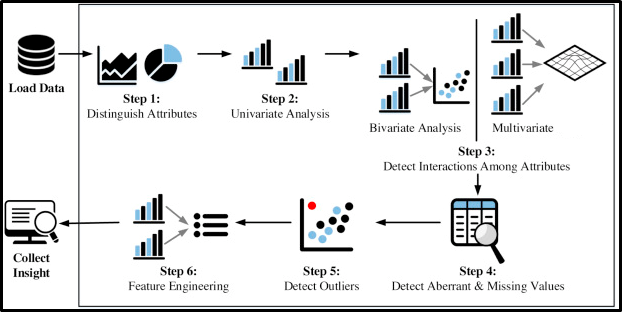
Négociation et traitement des données: L'objectif principal de cette étape et de cette approche sont les suivants.
Traitement de l'information (AED):
- Comprendre l'ensemble de données donné et aider à nettoyer l'ensemble de données donné.
- Vous permet de mieux comprendre les caractéristiques et les relations entre elles
- Extraire les variables essentielles et laisser de côté / supprimer les variables non essentielles.
- Gestion des valeurs manquantes ou erreur humaine.
- Identification des valeurs aberrantes.
- Le processus EDA maximiserait les informations à partir d'un ensemble de données.
Ingénierie fonctionnelle:
- Gestion des valeurs manquantes dans les variables
- Convertir catégorique en numérique car la plupart des algorithmes ont besoin de caractéristiques numériques.
- Besoin de corriger non gaussien (Ordinaire). Les modèles linéaires supposent que les variables ont une distribution gaussienne.
- Trouver des valeurs aberrantes sont présentes dans les données, nous tronquons donc les données au-dessus d'un seuil ou transformons les données en transformant les enregistrements.
- Fonctions d'échelle. Ceci est nécessaire pour donner la même importance à toutes les caractéristiques et pas plus à celle dont la valeur est la plus grande.
- L'ingénierie des fonctionnalités est un processus long et coûteux.
- L'ingénierie des fonctionnalités peut être un processus manuel, peut être automatisé
EntraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... y pruebas:
- Les données d'apprentissage sont utilisées pour garantir que la machine reconnaît les modèles dans les données., la validation croisée des données est utilisée pour assurer une meilleure exactitude et
l'efficacité de l'algorithme utilisé pour entraîner la machine. - Les données de test sont utilisées pour voir dans quelle mesure la machine peut prédire de nouvelles réponses en fonction de votre entraînement..
- La procédure de division de test de train est utilisée pour estimer la performance ML des algorithmes lorsqu'ils sont utilisés pour faire des prédictions sur des données qui ne sont pas
utilisé pour entraîner le modèle.
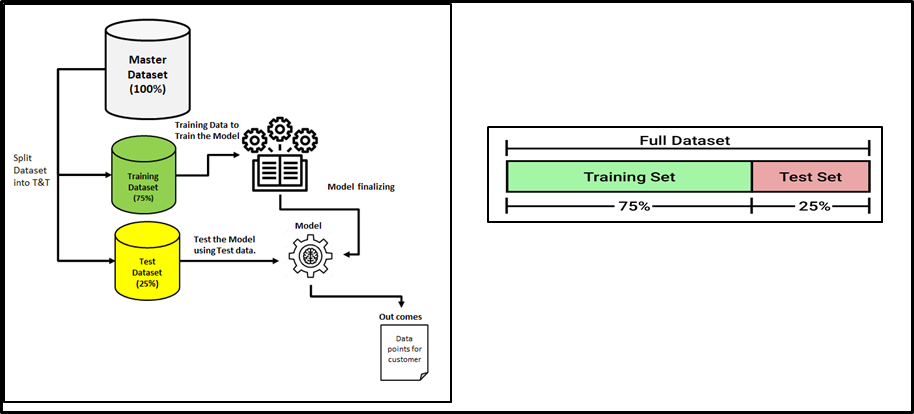
Entraînement
- Les données d'entraînement sont l'ensemble de données sur lequel le modèle s'entraîne.
- Former des données à partir desquelles le modèle a appris des expériences.
- Les ensembles d'entraînement sont utilisés pour ajuster et ajuster vos modèles.
Essais
- Les données de test sont les données qui sont utilisées pour vérifier si le modèle a
vous avez assez bien appris des expériences que vous avez acquises sur l'ensemble de données du train. - Ensembles de test
sont des données « invisible » pour évaluer vos modèles.
Données de train: Former notre algorithme d'apprentissage automatique
Données de test: Après avoir formé le modèle, les données de test sont utilisées pour tester votre efficacité et les performances du modèle.
Le but de l'état aléatoire dans la division de test de train: état_aléatoire assure que le divisions que vous générez sont reproductibles. Les état_aléatoire que vous fournissez est utilisé comme une semence pour le Aléatoire générateur de nombres. Cela garantit que le Aléatoire les nombres sont générés dans le même ordre.
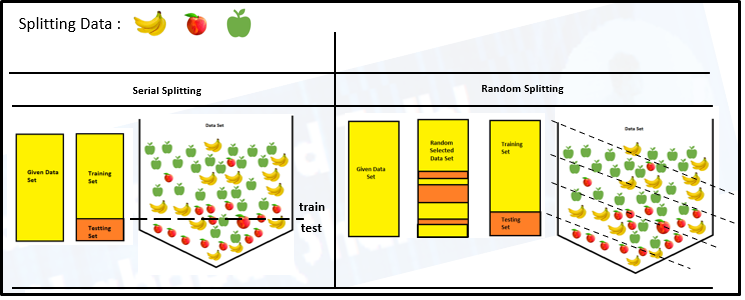
Données divisées en ensemble d'entraînement / test
- Nous avions l'habitude de diviser un ensemble de données en données d'entraînement et de données de test dans l'espace d'apprentissage automatique.
- La plage divisée est généralement 20% Al 80% entre les étapes de test et d'apprentissage de l'ensemble de données donné.
- Une grande quantité de données serait dépensée pour entraîner votre modèle
- Le reste du montant peut être dépensé pour évaluer votre modèle de test.
- Mais je ne peux pas mélanger / réutiliser les mêmes données à des fins de formation et de test
- Si vous évaluez votre modèle avec les mêmes données que vous avez utilisées pour l'entraîner, votre modèle pourrait être très sur-réglé. Ensuite, la question se pose de savoir si les modèles peuvent prédire de nouvelles données.
- Donc, vous devriez avoir des sous-ensembles de test et d'entraînement distincts de votre ensemble de données.
ÉVALUATION DU MODÈLE: Chaque modèle a sa propre mythologie d'évaluation de modèle, certaines des meilleures critiques sont ici.
- Évaluer régression Modèle.
- Somme de l'erreur au carré (ESS)
- Erreur quadratique moyenne (MSE)
- Erreur quadratique moyenne (RMSE)
- Erreur absolue moyenne (BEAUCOUP)
- Coefficient de détermination (R2)
- R2 ajusté
- Évaluer Classification Modèle.
- Matrice de confusion.
- Note de précision.
- AUC y ROC.
Déploiement d'un ML-modèle signifie simplement intégrer le modèle fini dans un environnement de production et obtenir des résultats pour prendre des décisions commerciales.
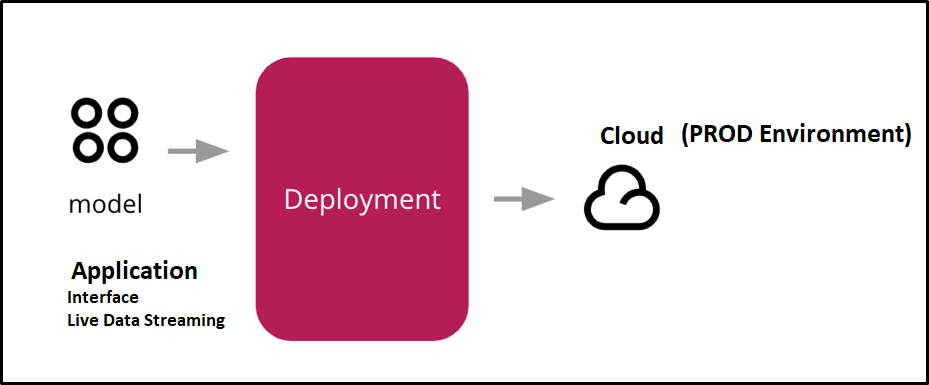
Donc, J'espère que vous pourrez comprendre le flux de processus de bout en bout de l'apprentissage automatique et je pense que cela vous serait utile. Merci pour votre temps.





