Vue d'ensemble
- Approche étape par étape pour effectuer l'EDA
- Des ressources comme des blogs, MOOCS pour se familiariser avec EDA
- Se familiariser avec diverses techniques de visualisation de données, graphiques et schémas.
- Démonstration de quelques étapes avec l'extrait de code Python
Ce qui différencie un professionnel de la science des données d'un autre?
Ce n'est pas de l'apprentissage automatique, ce n'est pas l'apprentissage en profondeurL'apprentissage en profondeur, Une sous-discipline de l’intelligence artificielle, s’appuie sur des réseaux de neurones artificiels pour analyser et traiter de grands volumes de données. Cette technique permet aux machines d’apprendre des motifs et d’effectuer des tâches complexes, comme la reconnaissance vocale et la vision par ordinateur. Sa capacité à s’améliorer continuellement au fur et à mesure que de nouvelles données lui sont fournies en fait un outil clé dans diverses industries, de la santé..., ce n'est pas du SQL, est l'analyse exploratoire des données (AED). À quel point est-on doué pour identifier les modèles / Tendances des données cachées et valeur des informations extraites, est ce qui distingue les professionnels des données.

1. Qu'est-ce que l'analyse de données exploratoire?
L'analyse exploratoire des données est une approche d'analyse des ensembles de données pour résumer leurs principales caractéristiques, utilisant souvent des graphiques statistiques et d'autres méthodes de visualisation de données.
EDA aide les professionnels de la science des données de plusieurs manières: –
1 Mieux comprendre les données
2 Identifier divers modèles de données
3 Mieux comprendre l'énoncé du problème
[ Noter: les base de donnéesUn "base de données" ou ensemble de données est une collection structurée d’informations, qui peut être utilisé pour l’analyse statistique, Apprentissage automatique ou recherche. Les ensembles de données peuvent inclure des variables numériques, catégorique ou textuelle, Et leur qualité est cruciale pour des résultats fiables. Son utilisation s’étend à diverses disciplines, comme la médecine, Économie et sciences sociales, faciliter la prise de décision éclairée et l’élaboration de modèles prédictifs.... in this blog is being opted as iris dataset]
2. Vérification des détails d'introduction sur les données
La première et la plus importante étape de toute analyse de données, après avoir chargé le fichier de données, devrait consister à vérifier quelques détails introductifs. Quoi, non. Des colonnes, non. de rangées, types de fonctionnalités (catégorique ou numérique), types de données d'entrée de colonne.
Extrait de code Python
data.info ()
Index de plage: 150 billets, 0 une 149
Colonnes de données (5 colonnes au total):
# Colonne Type de nombre non nul
– —— ————– —–
0 longueur_sépale 150 non nul float64
1 sepal_width 150 float64 non nul
2 longueur_pétale 150 non nul float64
3 pétale_largeur 150 non nul float64
4 espèce 150 objet non nul
types: float64 (4), objet (1)
utilisation de la mémoire: 6.0+ Ko
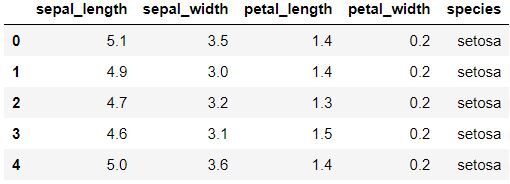
data.head () Pour afficher les cinq premières lignes
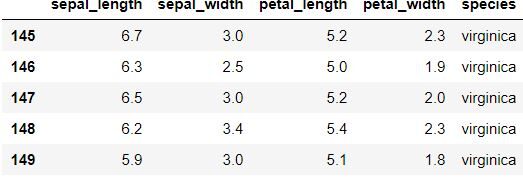
data.tail () pour afficher les cinq dernières lignes
3. Point de vue statistique
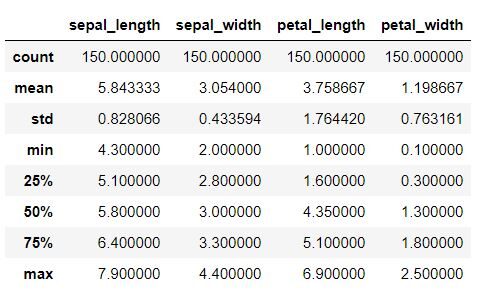
Cette étape doit être effectuée pour obtenir des détails sur diverses données statistiques en tant que moyenne, écart-type, médianLa médiane est une mesure statistique qui représente la valeur centrale d’un ensemble de données ordonnées. Pour le calculer, Les données sont organisées de la plus basse à la plus élevée et le numéro au milieu est identifié. S’il y a un nombre pair d’observations, La moyenne des deux valeurs fondamentales est calculée. Cet indicateur est particulièrement utile dans les distributions asymétriques, puisqu’il n’est pas affecté par les valeurs extrêmes...., valeur maximum, valeur minimum.
Extrait de code Python
données.décrire ()
4. Nettoyage des données
C'est l'étape la plus importante de l'EDA qui consiste à supprimer des lignes / colonnes en double, remplir les entrées vides avec des valeurs comme la moyenne / médiane des données, supprimer plusieurs valeurs, supprimer les entrées nulles
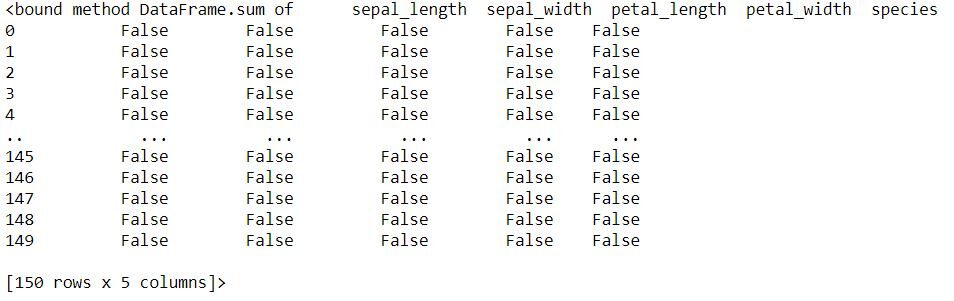
Vérification des entrées nulles
Extrait de code Python
data.IsNull (). sum da el número de valores perdidos para cada variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes....
Supprimer les entrées nulles
Extrait de code Python
data.dropna (axe = 0, en place = vrai) S'il y a des entrées nulles
Remplir des valeurs au lieu d'entrées nulles (si c'est une fonction numérique)
Les valeurs peuvent être la moyenne, la médiane ou tout nombre entier
Extrait de code Python
Les données["sepal_length"].remplir (valeur = données["sepal_length"].moyenne (), en place = vrai) s'il y a une entrée nulle
Vérification des doublons
Extrait de code Python
données.dupliquées (). somme () renvoie le nombre total d'entrées en double
Supprimer les doublons
Extrait de code Python
data.drop_duplicates (en place = vrai)
5. Visualisation de données
La visualisation des données est la méthode de conversion des données brutes en une forme visuelle, comme une carte ou un graphique, pour faciliter la compréhension des données et extraire des informations utiles..
L'objectif principal de la visualisation de données est de mettre de grands ensembles de données dans une représentation visuelle. C'est l'une des étapes importantes et faciles en matière de science des données.
Vous pouvez consulter le blog ci-dessous pour plus de détails sur la visualisation des données.
Différents types d'analyse de visualisation sont:
ongle. Analyse univariée:
Cela montre chaque observation / distribution des données dans une seule variable de données.. Se puede mostrar con la ayuda de varios diagramas como Diagramme de dispersionLe nuage de points est un outil graphique utilisé en statistiques pour visualiser la relation entre deux variables. Il se compose d’un ensemble de points dans un plan cartésien, où chaque point représente une paire de valeurs correspondant aux variables analysées. Ce type de graphique vous permet d’identifier des modèles, Tendances et corrélations possibles, faciliter l’interprétation des données et la prise de décision sur la base des informations visuelles présentées...., schéma de ligne, diagramme d'histogramme (résumé), boîtes à moustachesDiagrammes encadrés, Aussi connu sous le nom de diagrammes en boîte et à moustaches, sont des outils statistiques qui représentent la distribution d’un ensemble de données. Ces diagrammes montrent la médiane, quartiles et valeurs aberrantes, Permettre de visualiser la variabilité et la symétrie des données. Ils sont utiles pour la comparaison entre différents groupes et pour l’analyse exploratoire, faciliter l’identification des tendances et des modèles dans les données...., diagramme de violonLe diagramme du violon est une représentation graphique qui combine les caractéristiques d’une boîte à moustaches et d’un graphique de densité. Utilisé pour visualiser la distribution d’un ensemble de données, montrant à la fois la médiane et la variabilité par leur forme, qui ressemble à un violon. Ce type de graphique est très utile dans l’analyse statistique, puisqu’il permet de comparer plusieurs distributions de manière claire et efficace...., etc.
B. Analyse bi-variable:
Des écrans d'analyse bivariée sont effectués pour révéler la relation entre deux variables de données. Il peut également être représenté à l'aide de diagrammes de dispersion, histogrammesLes histogrammes sont des représentations graphiques qui montrent la distribution d’un ensemble de données. Ils sont construits en divisant la plage de valeurs en intervalles, O "Bacs", et compter la quantité de données tombées dans chaque intervalle. Cette visualisation vous permet d’identifier des modèles, Tendances et variabilité des données, faciliter l’analyse statistique et la prise de décision éclairée dans diverses disciplines...., cartes thermiques, boîtes à moustaches, diagrammes de violon, etc.
C. Analyse multivariable:
Analyse multivariée, comme le nom le suggère, sont affichés pour révéler la relation entre plus de deux variables de données.
Diagrammes de dispersion, histogrammes, boîtes à moustaches, les diagrammes de violon peuvent être utilisés pour l'analyse multivariée
Plusieurs parcelles
Vous trouverez ci-dessous quelques-uns des graphiques pouvant être implémentés pour une analyse univariée, bivarié et multivarié
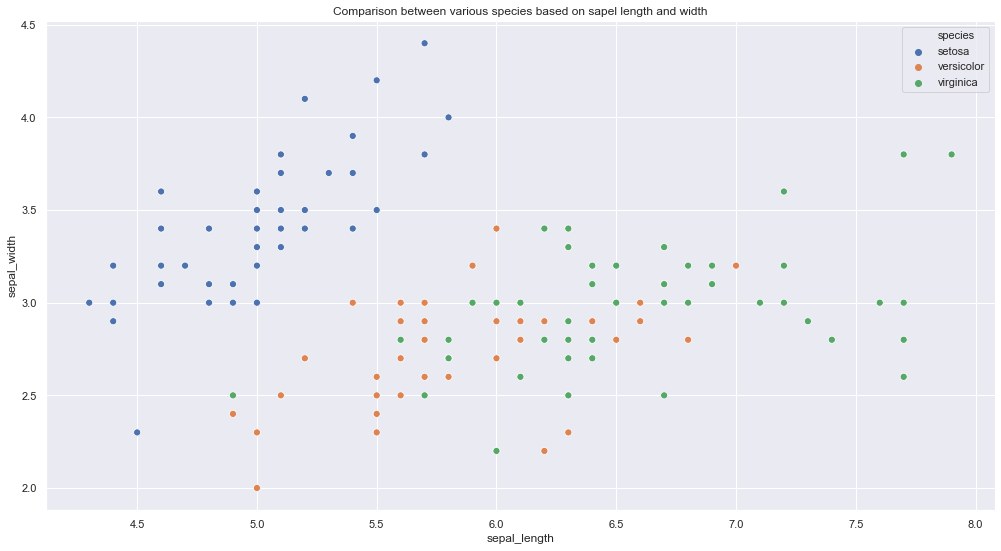
ongle. Nuage de pointsUn nuage de points est une représentation visuelle qui montre la relation entre deux variables numériques à l’aide de points sur un plan cartésien. Chaque axe représente une variable, et l’emplacement de chaque point indique sa valeur par rapport aux deux. Ce type de graphique est utile pour identifier des modèles, Corrélations et tendances dans les données, faciliter l’analyse et l’interprétation des relations quantitatives....
Extrait de code Python
plt.figure (taille de la figue = (17,9))
plt.titre (‘Comparación entre varias especies según la longitud y el ancho del sapel’)
sns.scatterplot (Les données['sepal_length'],Les données['sepal_width'], ton = données['espèce'], s = 50)
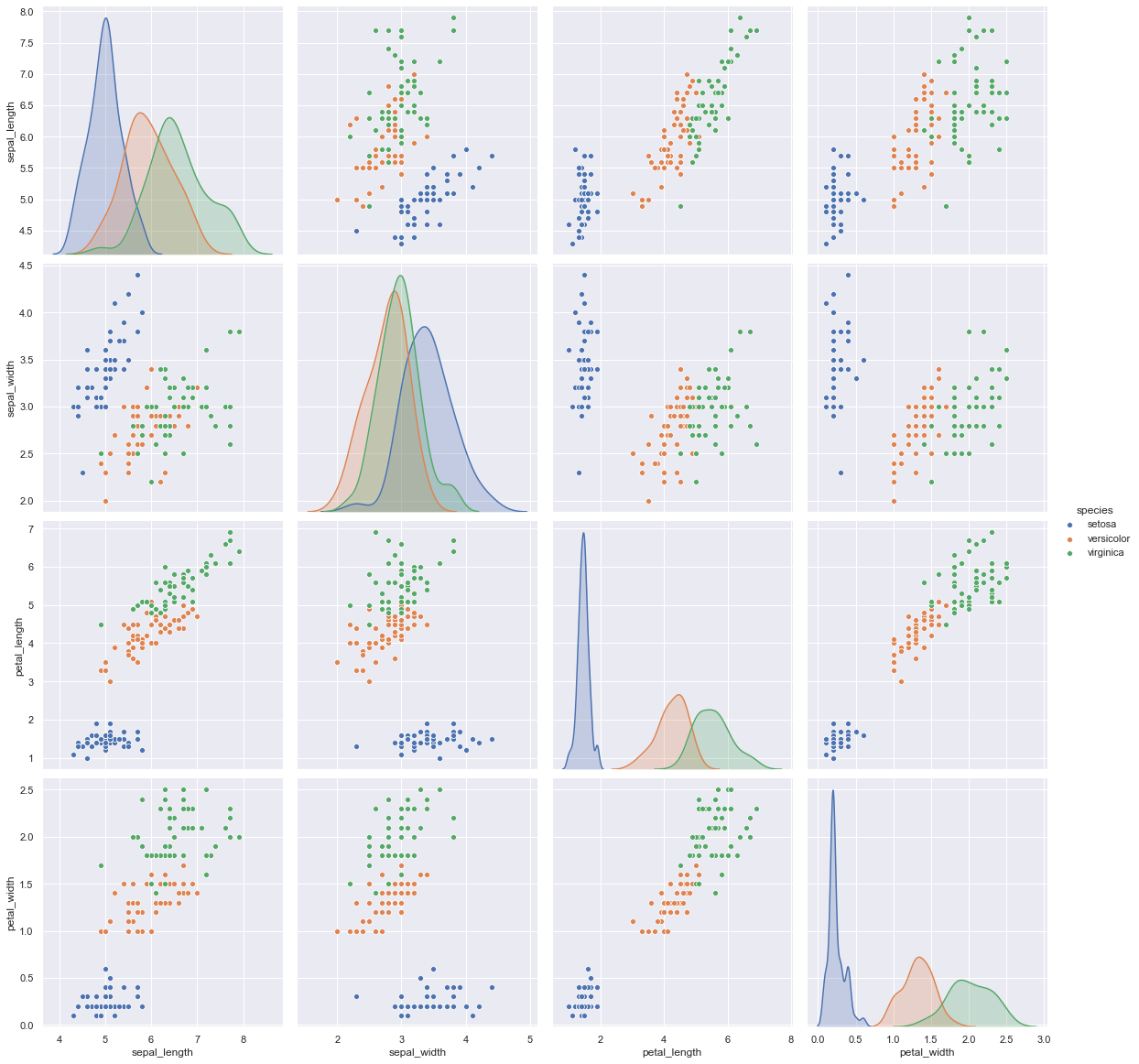
Pour l'analyse multivariée
Extrait de code Python
sns.pairplot (Les données, teinte = "espèce", hauteur = 4)
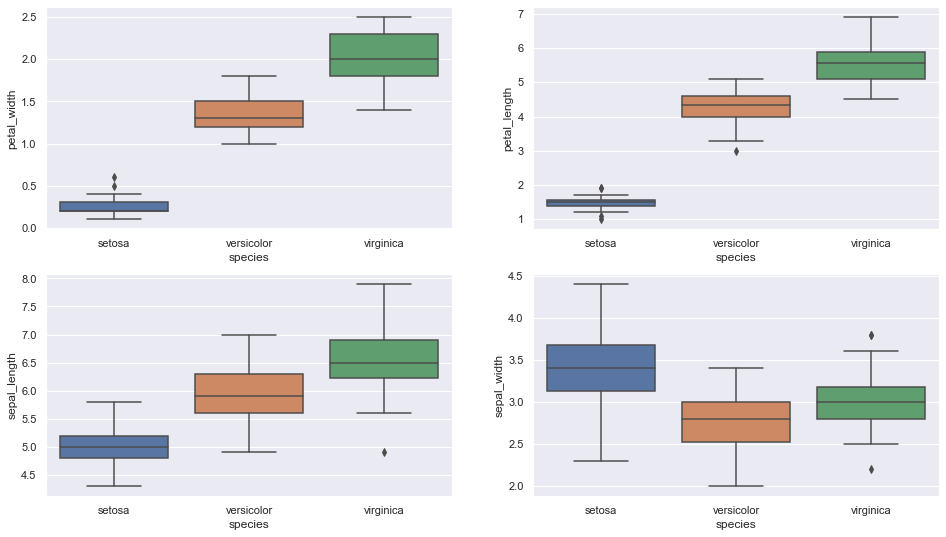
B. Box plot
Box plot pour voir comment la caractéristique catégorielle est distribuée « Espèce » avec les quatre autres variables d'entrée
Extrait de code Python
figure, axes = plt.subplots (2, 2, taille de la figue = (16,9))
sns.boxplot (y = « pétale_largeur », x = « espèce », données = iris_data, orient = ‘v’, hache = haches[0, 0])
sns.boxplot (y = « longueur_pétale », x = « espèce », données = iris_data, orient = ‘v’, hache = haches[0, 1])
sns.boxplot (y = " longueur_sepal ", x = "espèce", données = iris_data, orient = ‘v’, hache = haches[1, 0])
sns.boxplot (y = « sepal_width », x = « espèce », données = iris_data, orient = ‘v’, hache = ejes[1, 1])
plt.show ()
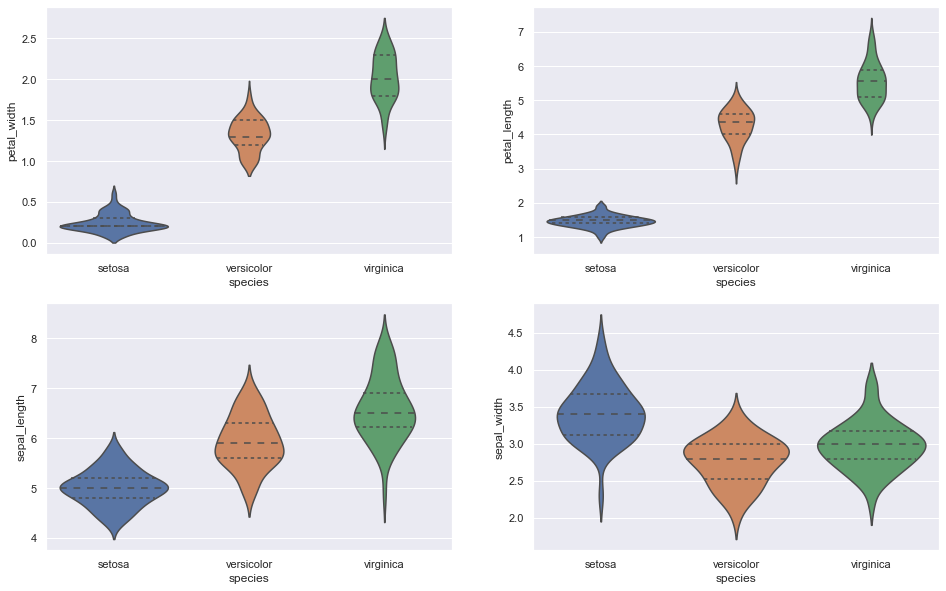
C. Cadre de violon
Plus informatif que la boîte à moustaches et montre la distribution complète des données.
Extrait de code Python
figure, axes = plt.subplots (2, 2, taille de la figue = (16,10))
sns.violinplot (y = "pétale_largeur", x = "espèce", données = iris_data, orient = ‘v’, hache = haches[0, 0], inner = ‘quartile’)
sns.violinplot (y = « longueur_pétale », x = « espèce », données = iris_data, orient = ‘v’, hache = ejes[0, 1], inner = ‘quartile’)
sns.violinplot (y = " longueur_sepal ", x = "espèce", données = iris_data, orient = ‘v’, hache = haches[1, 0], inner = ‘quartile’)
sns.violinplot (y = "sepal_width", x = "espèce", données = iris_data, orient = ‘v’, hache = haches[1, 1], inner = ‘quartile’)
plt.show ()
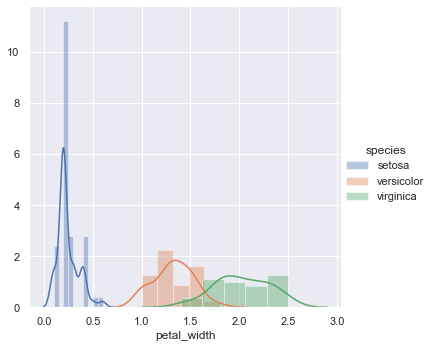
ré. Histogrammes
Peut être utilisé pour visualiser la fonction de densité de probabilité (PDF)
Extrait de code Python
sns.FacetGrid (iris_data, teinte = "espèce", hauteur = 5)
.carte (sns.distplot, « pétale_largeur »)
.ajouter_légende ();
Sur ce je termine ce blog.
Bonjour à tous, Namaste
Je m'appelle Pranshu Sharma et je suis un passionné de science des données
Merci beaucoup d'avoir pris votre temps précieux pour lire ce blog.. N'hésitez pas à signaler d'éventuelles erreurs (après tout, je suis apprenti) et fournir les commentaires correspondants ou laisser un commentaire.
Dhanyvaad !!
Retour d'information:
Courrier électronique: [email protégé]
Vous pouvez vous référer au blog mentionné ci-dessous pour vous familiariser avec l'analyse exploratoire des données.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





