- Compter les valeurs de chaque classe.
cerveau_df['masque'].value_counts()

- Afficher aléatoirement une image IRM à partir de l'ensemble de données.
image = cv2.imread(brain_df.image_path[1301]) plt.imshow(image)
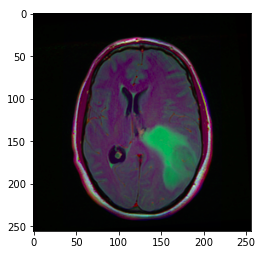
Image_path stocke le chemin de l'IRM cérébrale afin que nous puissions afficher l'image à l'aide de matplotlib.
Suggestion: la partie verdâtre de l'image ci-dessus peut être considérée comme la tumeur.
- En outre, afficher l'image de masque correspondante.
image1 = cv2.imread(brain_df.mask_path[1301]) plt.imshow(image1)
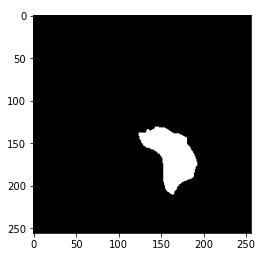
À présent, vous avez peut-être eu l'indice de ce qu'est vraiment le masque. Le masque est l'image de la partie du cerveau touchée par une tumeur à partir de l'image IRM correspondante. Ici, le masque provient de l'IRM cérébrale montrée ci-dessus.
- Analyser les valeurs de pixels de l'image du masque.
cv2.imread(brain_df.mask_path[1301]).max()
Départ: 255
La valeur maximale des pixels dans l'image du masque est 255, ce que la couleur blanche indique.
cv2.imread(brain_df.mask_path[1301]).min()
Départ: 0
La valeur minimale des pixels dans l'image du masque est 0, ce que la couleur noire indique.
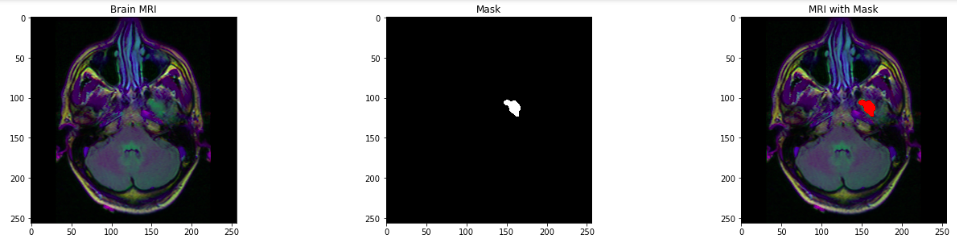
- Visualisation de l'IRM du cerveau, le masque correspondant et IRM avec le masque.
compter = 0
figure, axes = plt.subplots(12, 3, taille de la figue = (20, 50))
pour moi à portée(longueur(cerveau_df)):
si brain_df['masque'][je] ==1 et compter <5:
img = io.imread(brain_df.image_path[je])
haches[compter][0].titre.set_text(« IRM du cerveau »)
haches[compter][0].imshow(img)
masque = io.imread(brain_df.mask_path[je])
haches[compter][1].titre.set_text('Masque')
haches[compter][1].imshow(masque, cmap = 'gris')
img[masque == 255] = (255, 0, 0) #couleur rouge
haches[compter][2].titre.set_text(« IRM avec masque »)
haches[compter][2].imshow(img)
compte+=1
fig.tight_layout()
- Supprimer l'identification, car il n'est pas nécessaire pour le traitement.
# Supprimer la colonne d'identification du patient brain_df_train = brain_df.drop(colonnes = ['patient_id']) brain_df_train.shape
Vous obtiendrez la taille du bloc de données dans la sortie: (3929, 3)
- Convertir les données dans la colonne de masque du format entier au format chaîne, puisque nous aurons besoin des données au format chaîne.
brain_df_train['masque'] = brain_df_train['masque'].appliquer(lambda x: str(X)) brain_df_train.info()
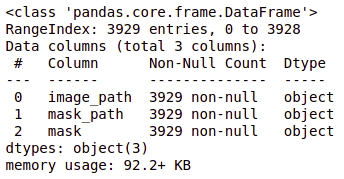
Comme tu peux le voir, maintenant chaque caractéristique a un type de données comme objet.
- Divisez les données en ensembles de test et d'apprentissage.
# diviser les données en données de train et de test de sklearn.model_selection importer train_test_split former, test = train_test_split(brain_df_train, taille_test = 0.15) |
- Augmentez plus de données avec ImageDataGenerator. ImageDataGenerator génère des lots de données d'image de tendeur avec une augmentation des données en temps réel.
Référer ici pour plus d'informations sur ImageDataGenerator et les paramètres en détail.
Nous allons créer un train_generator et un validation_generator à partir des données de train et un test_generator à partir des données de test.
# créer un générateur d'images à partir de keras_preprocessing.image importer ImageDataGenerator #Créer un générateur de données qui met à l'échelle les données de 0 à 1 et rend la validation fractionnée de 0.15 datagen = ImageDataGenerator(redimensionner=1./255., validation_split = 0.15) train_generator=datagen.flow_from_dataframe( dataframe=train, répertoire= './', x_col="chemin_image", y_col ="masque", sous-ensemble ="entraînement", taille_lot=16, shuffle=Vrai, class_mode="catégorique", target_size=(256,256)) valid_generator=datagen.flow_from_dataframe( dataframe=train, répertoire= './', x_col="chemin_image", y_col ="masque", sous-ensemble ="validation", taille_lot=16, shuffle=Vrai, class_mode="catégorique", target_size=(256,256)) # Créer un générateur de données pour les images de test test_datagen=ImageDataGenerator(redimensionner=1./255.) test_generator=test_datagen.flow_from_dataframe( cadre de données=test, répertoire= './', x_col="chemin_image", y_col ="masque", taille_lot=16, shuffle=Faux, class_mode="catégorique", target_size=(256,256))





