Cet article a été publié dans le cadre de la Blogathon sur la science des données.
introduction
Les données non structurées contiennent une grande quantité d'informations. C'est comme de l'énergie lorsqu'elle est exploitée, créer de la valeur pour vos parties prenantes. Plusieurs entreprises travaillent déjà fort dans ce domaine. Il ne fait aucun doute que les données non structurées sont bruyantes et un travail important doit être fait pour les nettoyer, les analyser et les rendre significatifs pour votre usage. Cet article traite d'un domaine qui permet d'analyser de grandes quantités de données en résumant le contenu et en identifiant les sujets d'intérêt.: Extraction de mots clés
Présentation de l'extraction de mots clés
C'est une technique d'analyse de texte. Nous pouvons obtenir des connaissances importantes sur le sujet dans un court laps de temps. Aide à concis le texte et à obtenir des mots-clés pertinents. Économisez du temps sur l'examen de l'intégralité du document. Des exemples de cas d'utilisation sont la recherche de sujets d'intérêt dans un article d'actualité et l'identification de problèmes en fonction des commentaires des clients, etc. L'une des techniques utilisées pour l'extraction de mots clés est TF-IDF (fréquence de terminaison – inverser la fréquence des documents)
TF – Présentation de l'IDF
Fréquence des trimestres – À quelle fréquence une définition apparaît-elle dans un texte. Il est mesuré comme le nombre de fois qu'une définition t apparaît dans le texte / Nombre total de mots dans le document
Inverser la fréquence des documents – Quelle est la pertinence d'un mot dans un document ?. Mesurer en tant que journal (nombre total de phrases / Nombre de phrases avec le terme t)
TF-IDF – La pertinence des mots se mesure par ce score. Il est mesuré en TF * Tsahal
Nous allons utiliser le même concept et essayer de le coder ligne par ligne en utilisant Python. Nous prendrons un plus petit ensemble de documents texte et effectuerons toutes les étapes ci-dessus. Bien qu'il existe déjà des concepts plus avancés pour l'extraction de mots clés sur le marché, Cet article vise à comprendre le concept de base derrière l'identification de la pertinence des mots. Commençons!
Mise en œuvre
1. Importer des packages
Nous avons besoin de tokenize pour créer des jetons de mots, itemgetter pour trier le dictionnaire et math pour effectuer l'opération de base de journal e
de nltk import tokenize de l'opérateur import itemgetter importer des mathématiques
2. Déclarer des variables
Nous allons déclarer une variable chaîne. Ce sera un espace réservé pour l'exemple de document texte.
doc="je suis diplômé. Je veux apprendre Python. J'aime apprendre Python. Python est facile. Python est intéressant. Apprendre augmente la réflexion. Tout le monde devrait investir du temps dans l'apprentissage"
3. Enlève les mots vides
Les mots vides sont des mots qui apparaissent souvent et peuvent ne pas être pertinents pour notre analyse.. Nous pouvons supprimer l'utilisation de la bibliothèque nltk
importer nltk
à partir de nltk.corpus importer des mots vides
de nltk.tokenize importer word_tokenize
stop_words = définir(mots.mots.mots('Anglais'))
4. Trouver le nombre total de mots dans le document.
Cela sera nécessaire lors du calcul de la fréquence de terminaison
total_mots = doc.split() total_word_length = longueur(total_mots) imprimer(longueur_mot_total)
5. Calculer le nombre total de phrases
Cela sera nécessaire lors du calcul de la fréquence inverse du document.
total_sentences = tokenize.sent_tokenize(doc) total_sent_len = len(total_phrases) imprimer(total_sent_len)
6. Calculer TF pour chaque mot
Nous commencerons par calculer le nombre de mots pour chaque mot sans nous arrêter et en conclusion nous diviserons chaque élément par le résultat de l'étape 4
tf_score = {}
pour chaque_mot dans total_mots:
chaque_mot = chaque_mot.remplacer('.','')
si each_word n'est pas dans les stop_words:
si chaque_mot dans tf_score:
tf_score[chaque mot] += 1
autre:
tf_score[chaque mot] = 1
# Diviser par total_word_length pour chaque élément du dictionnaire
tf_score.update((X, y/int(longueur_mot_total)) pour x, y dans tf_score.items())
imprimer(tf_score)
7. Fonction pour vérifier si le mot est présent dans une liste de phrases.
Cette méthode sera requise lors du calcul de l'IDF.
def check_sent(mot, Phrases):
finale = [tous([w dans x pour w dans mot]) pour x dans les phrases]
sent_len = [Phrases[je] pour moi à portée(0, longueur(final)) si définitif[je]]
retour int(longueur(envoyé_len))
8. Calculer l'IDF pour chaque mot.
Nous utiliserons la fonction à l'étape 7 pour itérer le mot à l'infini et stocker le résultat pour la fréquence inverse du document.
idf_score = {}
pour chaque_mot dans total_mots:
chaque_mot = chaque_mot.remplacer('.','')
si each_word n'est pas dans les stop_words:
si chaque_mot dans idf_score:
idf_score[chaque mot] = check_sent(chaque mot, total_phrases)
autre:
idf_score[chaque mot] = 1
# Effectuer un journal et diviser
idf_score.update((X, math.log(entier(total_sent_len)/
9. Calculatrice TF * Tsahal
Puisque la clé des deux dictionnaires est la même, on peut itérer un dictionnaire pour obtenir les clés et multiplier les valeurs des deux
tf_idf_score = {clé: tf_score[clé] * idf_score.get(clé, 0) pour la clé dans tf_score.keys()}
imprimer(tf_idf_score)
10. Créer une fonction pour obtenir N mots importants dans le document
def get_top_n(dict_elem, m):
résultat = dict(trié(dict_elem.items(), clé = itemgetter(1), inverse = vrai)[:m])
résultat de retour
11. Obtenir le 5 mots les plus importants
imprimer(get_top_n(tf_idf_score, 5))
conclusion
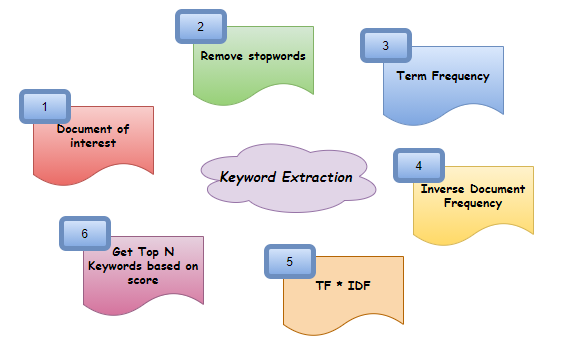
Ensuite, C'est l'une des façons dont vous pouvez créer votre propre extracteur de mots clés en python !! Les étapes ci-dessus peuvent être résumées de manière simple comme Document -> Effacer les mots vides -> Rechercher la fréquence du terme (TF) -> Trouver la fréquence des documents inversés (Tsahal) -> Rechercher TF * IDF -> Obtenir le Top N des mots clés. Partagez vos pensées si ce post était intéressant ou vous a aidé de quelque façon que ce soit. Toujours ouvert aux améliorations et suggestions. Vous pouvez trouver le code dans GitHub





