Les supports présentés dans cet article ne sont pas la propriété d'Analytics Vidhya et sont utilisés à la discrétion de l'auteur..
introduction
Nous formons essentiellement des machines pour y inclure une sorte d'automatisation. En apprentissage automatique, nous utilisons différents types d'algorithmes pour permettre aux machines d'apprendre les relations au sein des données fournies et de faire des prédictions avec celles-ci. Ensuite, le type de prédiction du modèle où nous avons besoin de la sortie prédite est une valeur numérique continue, ça s'appelle un problème de régression.
L'analyse de régression s'articule autour d'algorithmes simples, souvent utilisé en finance, investissements et autres, et établit la relation entre une seule variable dépendante qui dépend de plusieurs variables indépendantes. Par exemple, prévoir le prix d'une maison ou le salaire d'un employé, etc., sont les problèmes de régression les plus courants.
Nous allons d'abord discuter des types d'algorithmes de régression sous peu, puis passer à un exemple. Ces algorithmes peuvent être à la fois linéaires et non linéaires.
Algorithmes de ML linéaire

Régression linéaire
C'est un algorithme couramment utilisé et peut être importé à partir de la classe de régression linéaire. Une seule variable d'entrée est utilisée (l'important) pour prédire une ou plusieurs variables de sortie, en supposant que la variable d'entrée n'est pas corrélée les unes avec les autres. se présenter comme:
y = b * X + c
où variable dépendante de y, indépendant de x, pente b de la ligne de meilleur ajustement qui pourrait obtenir une sortie précise et c – leur croisement. À moins qu'il n'y ait une ligne exacte qui relie les variables dépendantes et indépendantes, il pourrait y avoir une perte de la production qui est normalement considérée comme le carré de la différence entre la production attendue et la production réelle, c'est-à-dire, fonction de perte.
Lorsque vous utilisez plusieurs variables indépendantes pour obtenir des résultats, est appelé La régression linéaire multiple. Ce type de modèle suppose qu'il existe une relation linéaire entre la caractéristique donnée et la sortie, quel est son limitation.
Régression de crête: la norme L2
Il s'agit d'un type d'algorithme qui est une extension d'une régression linéaire qui essaie de minimiser la perte, utilise également des données de régression multiple. Ses coefficients ne sont pas estimés par les moindres carrés ordinaires (AGC), mais par un estimateur appelé crest, qui est biaisé et a une variance plus faible que l'estimateur OLS, on obtient donc une contraction des coefficients. Avec ce type de modèle, on peut aussi réduire la complexité du modèle.
Bien que la contraction du coefficient se produise ici, ne sont pas complètement réduits à zéro. Donc, votre modèle final contiendra toujours tout.
Régression de boucle: la norme L1
C'est l'opérateur de sélection et de retrait minimum absolu. Cela pénalise la somme des valeurs absolues des coefficients pour minimiser l'erreur de prédiction. Rend les coefficients de régression de certaines variables à zéro. Il peut être construit en utilisant la classe LASSO. L'un des avantages de la boucle est sa sélection simultanée de fonctions. Cela permet de minimiser la perte de prédiction. D'un autre côté, nous devons garder à l'esprit que lasso ne peut pas faire une sélection de groupe, sélectionne également les fonctionnalités avant de saturer.
La boucle et la crête sont des méthodes de régularisation.

la source: Unsplash
Passons en revue quelques exemples:
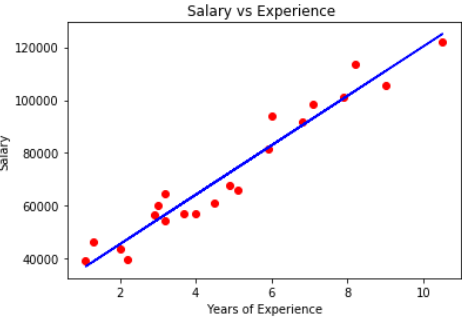
Supposons une donnée avec des années d'expérience et le salaire de différents employés. Notre objectif est de créer un modèle qui prédit le salaire de l'employé basé sur l'année d'expérience. Comme il contient une variable indépendante et une variable dépendante, nous pouvons utiliser une régression linéaire simple pour ce problème.
Algorithmes de ML non linéaires
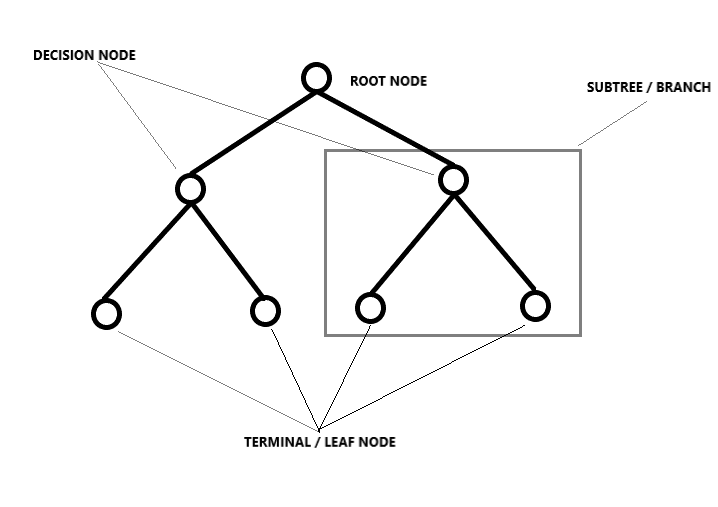
Régression de l'arbre de décision
Décompose un ensemble de données en sous-ensembles de plus en plus petits en le divisant, résultant en un arbre avec des nœuds de décision et des nœuds feuilles. L'idée ici est de tracer une valeur pour tout nouveau point de données reliant le problème. Le type de façon dont la division est effectuée est déterminé par les paramètres et l'algorithme, et la division s'arrête lorsqu'elle atteint le nombre minimum d'informations à ajouter. Les arbres de décision sont souvent payants, mais même s'il y a un léger changement dans les données, toute la structure change, ce qui signifie que les modèles deviennent instables.
la source: unsplash
Prenons un cas de prévision du prix de l'immobilier, étant donné un ensemble de 13 fonctionnalités et autour 500 Lignes, ici, vous devez prédire le prix de la maison. Puisque vous avez un nombre considérable d'échantillons ici, vous devez opter pour des arbres ou d'autres méthodes pour prédire les valeurs.
Forêt aléatoire
L'idée derrière la régression de forêt aléatoire est que, pour trouver le résultat, utiliser plusieurs arbres de décision. Les étapes qui y sont liées sont:
– Choisissez K points de données aléatoires dans l'ensemble d'apprentissage.
– Construire un arbre de décision associé à ces points de données
– Choisissez le nombre d'arbres à construire et répétez les étapes ci-dessus (fourni comme argument)
– Pour un nouveau point de données, faire en sorte que chacun des arbres prédise les valeurs de la variable dépendante pour l'entrée donnée.
– Attribuez la valeur moyenne des valeurs prédites à la sortie finale réelle.
Cela revient à deviner le nombre de boules dans une boîte.. Supposons que nous écrivions au hasard les valeurs de prédiction données par de nombreuses personnes, puis que nous calculions la moyenne pour prendre une décision sur le nombre de balles dans la boîte.. La forêt aléatoire est un modèle qui utilise plusieurs arbres de décision, que l'on sait, mais comme il y a beaucoup d'arbres, nécessite également beaucoup de temps de formation et de puissance de calcul, ce qui est encore un inconvénient.
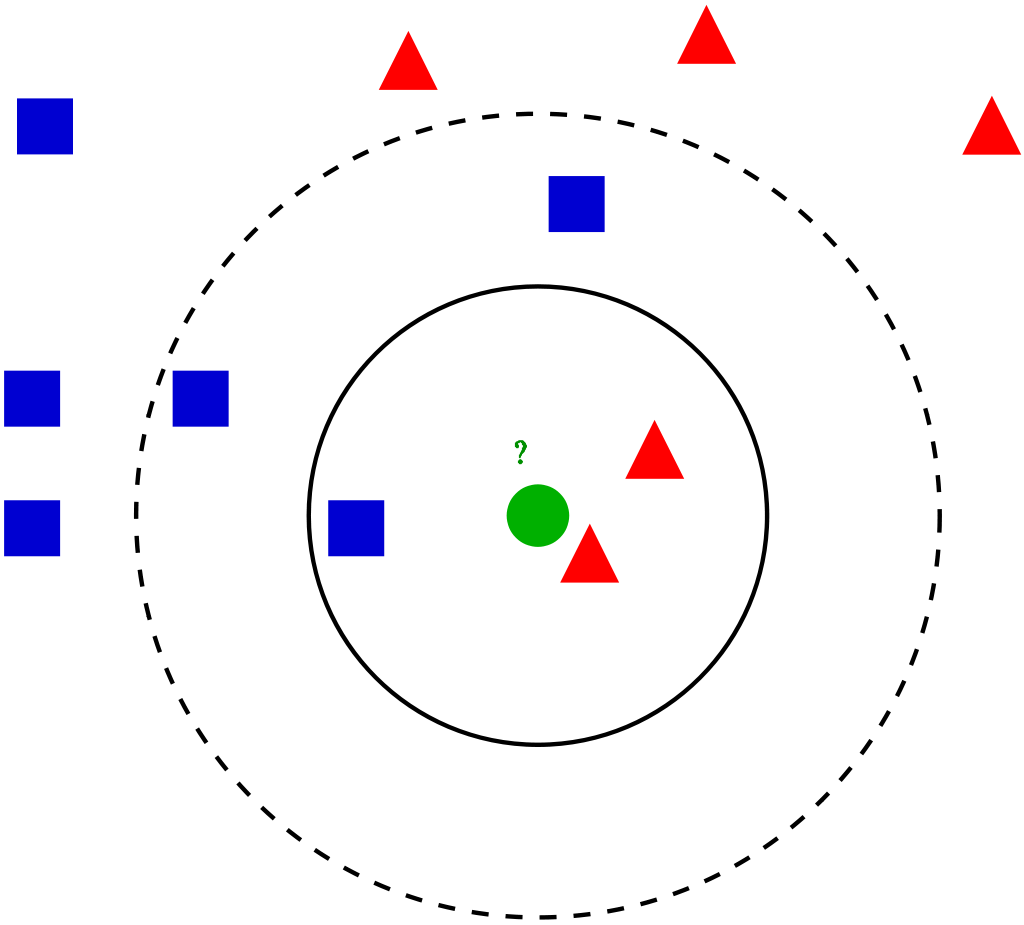
K Voisins les plus proches (modèle KNN)
Il peut être utilisé à partir de la classe KNearestNeighbors. Ils sont simples et faciles à mettre en œuvre. Pour une entrée saisie dans le dataset, les K voisins les plus proches aident à trouver les k instances les plus similaires dans l'ensemble d'apprentissage. L'une des valeurs moyennes de la médiane des voisins est prise comme valeur pour cette entrée.
la source: unsplash
La méthode pour trouver la valeur peut être donnée comme argument, dont la valeur par défaut est “Minkowski”, une combinaison de distances “euclidien” Oui “Manhattan”.
Les prédictions peuvent être lentes lorsque les données sont volumineuses et de mauvaise qualité. Étant donné que la prédiction doit prendre en compte tous les points de données, le modèle prendra plus de place pendant l'entraînement.
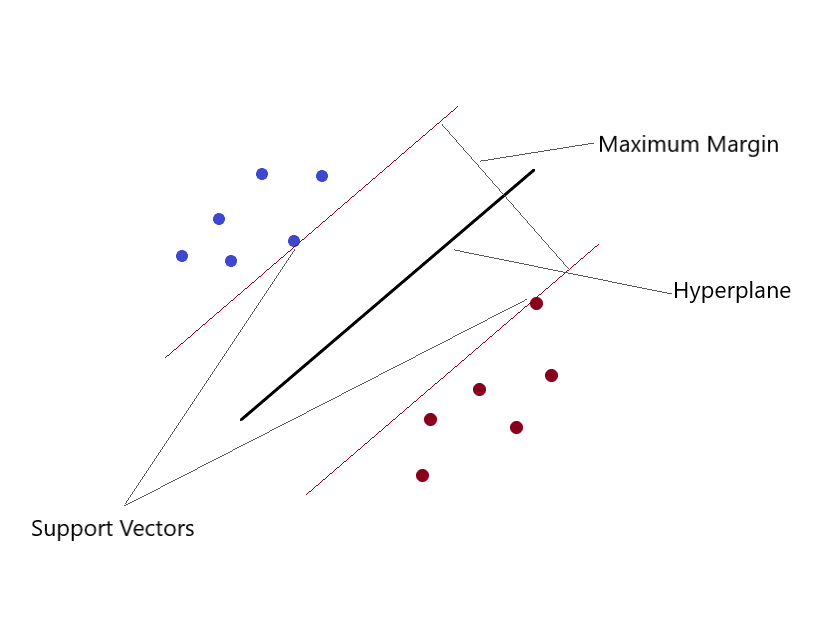
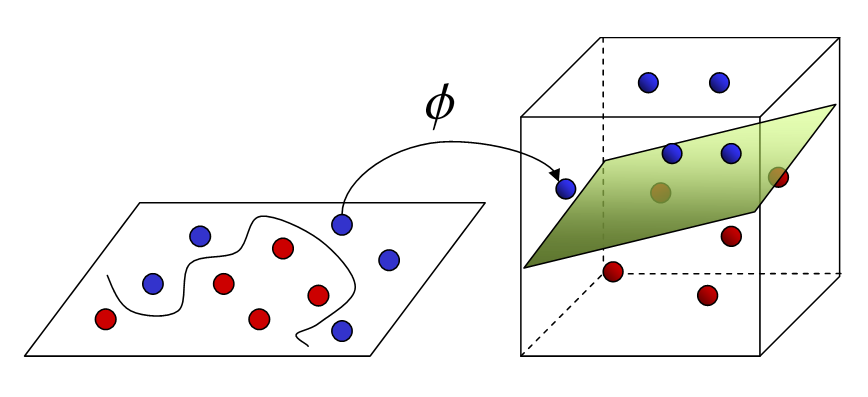
Machines à vecteurs de soutien (SVM)
Peut résoudre des problèmes de régression linéaire et non linéaire. Nous créons un modèle SVM en utilisant la classe SVR. en un espace multidimensionnel, lorsque nous avons plus d'une variable pour déterminer la sortie, alors chacun des points n'est plus un point comme en 2D, mais ce sont des vecteurs. Le type d'attribution de valeur le plus extrême peut être effectué en utilisant cette méthode. Vous séparez les classes et leur donnez des valeurs. La séparation est par le concept de Max-Margin (un hyperplan). Ce que vous devez garder à l'esprit, c'est que les SVM ne conviennent pas pour prédire les valeurs pour les grands ensembles d'entraînement.. SVM échec quand les données sont plus bruyantes.
la source: unsplash
la source: unsplash
Si les données d'entraînement sont beaucoup plus grandes que le nombre de fonctions, KNN est meilleur que SVM. SVM surpasse KNN lorsqu'il y a des fonctions plus importantes et moins de données d'entraînement.
Bon, nous sommes arrivés à la fin de cet article, nous avons brièvement discuté des types d'algorithmes de régression (théorie). Este es Surabi, j'ai un diplôme en technologie. Regarde moi Profil LinkedIn et connectez-vous. J'espère que vous avez apprécié cette lecture. Merci.
Les supports présentés dans cet article ne sont pas la propriété d'Analytics Vidhya et sont utilisés à la discrétion de l'auteur..





