introduction
Résolvons les environnements Cartpole, Lunar Lander et Pong d'OpenAI avec l'algorithme STRENGTH.
Le apprentissage par renforcementL’apprentissage par renforcement est une technique d’intelligence artificielle qui permet à un agent d’apprendre à prendre des décisions en interagissant avec un environnement. Par le biais de commentaires sous forme de récompenses ou de punitions, L’agent optimise son comportement pour maximiser les récompenses accumulées. Cette approche est utilisée dans une variété d’applications, Des jeux vidéo à la robotique en passant par les systèmes de recommandation, se démarquant par sa capacité à apprendre des stratégies complexes.... es posiblemente la rama más genial de la inteligencia artificial. A déjà démontré ses prouesses: étonner le monde, battre les champions du monde aux jeux d'échecs, Allez et incluez DotA 2.
Dans cet article, J'analyserais un algorithme plutôt rudimentaire et montrerais comment même cela peut atteindre un niveau de performance surhumain dans certains jeux.
L'apprentissage par renforcement offre with conception « Agents » qui interagit avec un « Environnement » et apprenez par vous-même comment « Trier » l'environnement par essais et erreurs systématiques. Un environnement peut être un jeu comme les échecs ou la course, ou cela pourrait même être une tâche comme résoudre un labyrinthe ou atteindre un objectif. L'agent est le bot qui effectue l'activité.
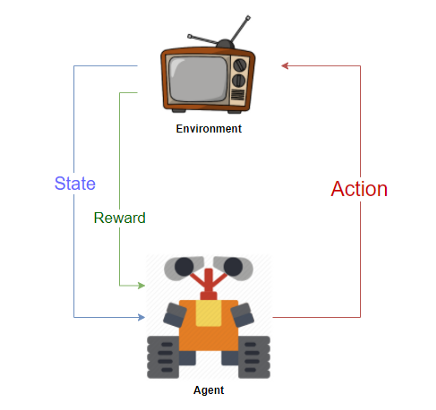
Un agent reçoit « récompenses » lors de l'interaction avec l'environnement. L'agent apprend à exécuter les « Actions » nécessaire pour maximiser la récompense que vous recevez de l'environnement. Un environnement est considéré comme résolu si l'agent accumule un seuil de récompense prédéfini. Ce discours ringard explique comment nous apprenons aux robots à jouer aux échecs surhumains ou aux androïdes bipèdes à marcher.
RENFORCER l'algorithme
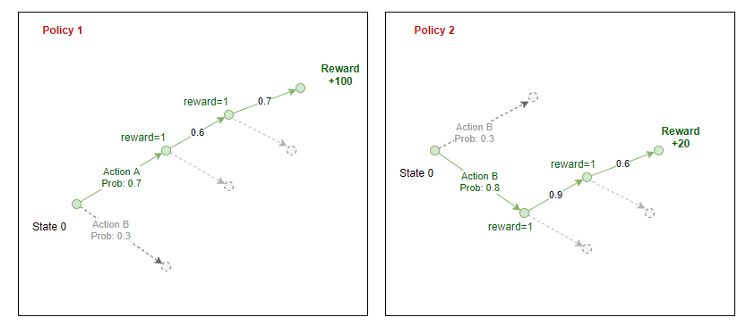
REINFORCE pertenece a una clase especial de algoritmos de aprendizaje por refuerzo llamados algoritmos de penteLe gradient est un terme utilisé dans divers domaines, comme les mathématiques et l’informatique, pour décrire une variation continue de valeurs. En mathématiques, fait référence au taux de variation d’une fonction, pendant la conception graphique, S’applique à la transition de couleur. Ce concept est essentiel pour comprendre des phénomènes tels que l’optimisation dans les algorithmes et la représentation visuelle des données, permettant une meilleure interprétation et analyse dans... de políticas. Une implémentation simple de cet algorithme consisterait à créer un Politique: un modèle qui prend un état en entrée et génère la probabilité d'effectuer une action en sortie. Une politique est essentiellement un guide ou un aide-mémoire pour l'agent qui indique les mesures à prendre dans chaque état.. Alors, la politique est répétée et légèrement modifiée à chaque étape jusqu'à ce que nous obtenions une politique qui résout l'environnement.
La política suele ser una neuronal rougeLes réseaux de neurones sont des modèles computationnels inspirés du fonctionnement du cerveau humain. Ils utilisent des structures appelées neurones artificiels pour traiter et apprendre des données. Ces réseaux sont fondamentaux dans le domaine de l’intelligence artificielle, permettant des avancées significatives dans des tâches telles que la reconnaissance d’images, Traitement du langage naturel et prédiction de séries temporelles, entre autres. Leur capacité à apprendre des motifs complexes en fait des outils puissants.. que toma el estado como entrada y genera una distribución de probabilidad en el espacio de acción como salida.
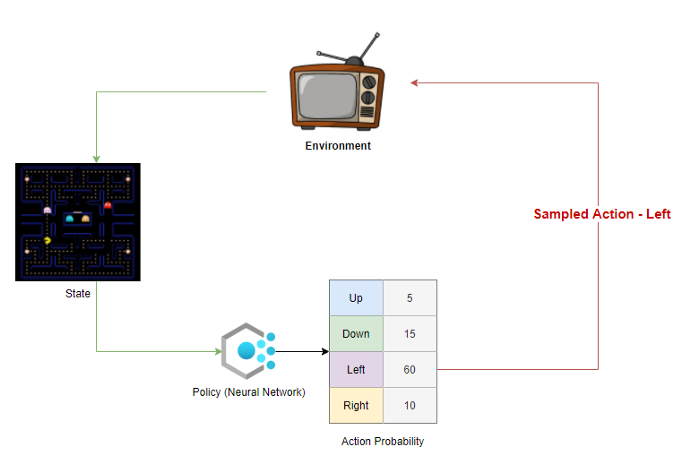
L'objectif de la politique est de maximiser la "Récompense attendue".
Chaque politique génère la probabilité d'entreprendre une action dans chaque station de l'environnement.
L'agent échantillonne ces probabilités et sélectionne une action à entreprendre dans l'environnement. A la fin d'un épisode, nous connaissons les récompenses totales que l'agent peut obtenir s'il suit cette politique. Nous reproduisons la récompense à travers l'itinéraire emprunté par l'agent pour estimer le « récompense attendue » dans chaque état pour une politique donnée.

Ici, la récompense actualisée est la somme de toutes les récompenses que l'agent reçoit dans ce futur actualisées par un facteur Gamma.

La récompense à prix réduit à n'importe quelle étape est la récompense que vous recevez à l'étape suivante + une somme actualisée de toutes les récompenses que l'agent recevra à l'avenir.
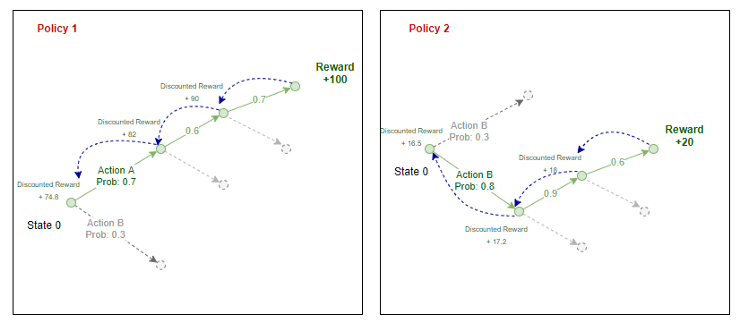
Pour l'équation ci-dessus, c'est ainsi que nous calculons la récompense attendue:
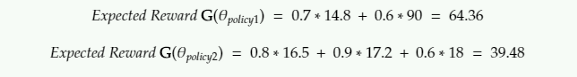
Selon l'implémentation originale de l'algorithme STRENGTH, la récompense attendue est la somme des produits d'un enregistrement de cotes et récompenses réduites.
Étapes de l'algorithme
Les étapes impliquées dans la mise en œuvre du RENFORCEMENT seraient les suivantes:
- Initialiser une politique aléatoire (un NN qui prend l'état en entrée et renvoie la probabilité des actions)
- Utilisez la politique pour jouer N étapes du jeu: enregistrer les probabilités d'action, de la politique, la récompense de l'environnement, l'action, échantillonné par l'agent
- Calculer la récompense actualisée pour chaque étape par rétropropagation
- Calculer la récompense attendue G
- Ajuster les pondérations de la politique (erreur de propagation inverse dans NN) augmenter G
- Répéter de 2
Voir la mise en œuvre à l'aide de Pytorch dans mon Github.
Ville
J'ai testé l'algorithme dans Pong, CartPole et l'atterrisseur lunaire. Il faut une éternité pour s'entraîner à Pong et Lunar Lander: plus de 96 horas de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... cada uno en una GPU en la nube. Il existe plusieurs mises à jour de cet algorithme qui peuvent le faire converger plus rapidement, que je n'ai pas discuté ou mis en œuvre ici. Consultez les modèles d'acteurs critiques et l'optimisation des politiques à venir si vous souhaitez en savoir plus.
Chariot

État:
Position horizontale, vitesse horizontale, angle de pôle, vitesse angulaire
Comportement:
Pousser le chariot vers la gauche, Pousser le chariot vers la droite
Jeu de politique aléatoire:
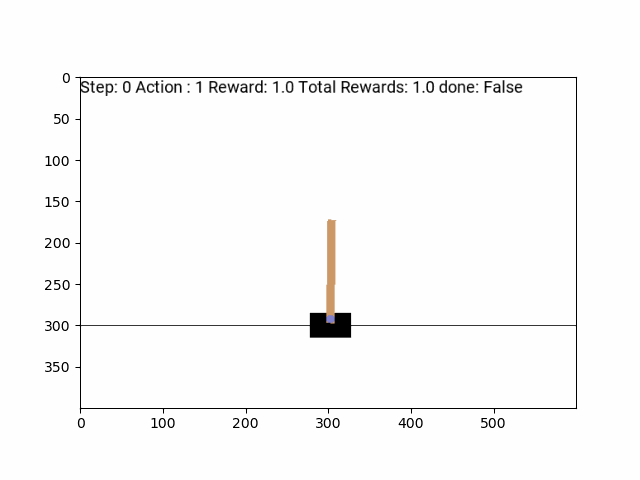
Politique des agents formés avec RENFORCE:
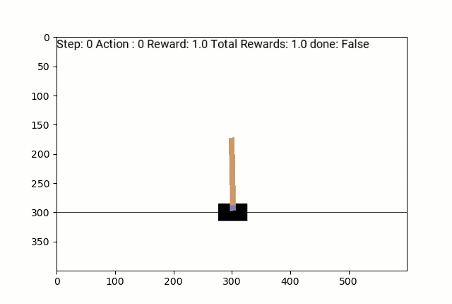
Atterrisseur lunaire
Agent de jeu aléatoire
État:
L'état est une matrice de 8 vecteur. Je ne sais pas ce qu'ils représentent.
Comportement:
0: ne fais rien
1: camion de pompiers gauche
2: Camion de pompier
3: pompier droit
Politique des agents formés avec RENFORCE:
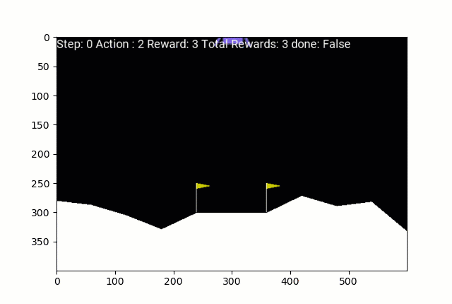
Atterrisseur lunaire entraîné avec RENFORCE
Puer
C'était beaucoup plus difficile à former. Formé sur un serveur cloud GPU pendant des jours.
État: Image
Comportement: Déplacer la palette vers la gauche, déplacer la palette vers la droite
Agent formé
L'apprentissage par renforcement a progressé à pas de géant au-delà du RENFORCEMENT. Mon objectif dans cet article était 1. apprendre les bases de l'apprentissage par renforcement et 2. montrer à quel point même des méthodes aussi simples peuvent être puissantes pour résoudre des problèmes complexes. j'aimerais bien les essayer sur certains « Jeux » gagner de l'argent comme la bourse … Je suppose que c'est le Saint Graal parmi les data scientists.
Dépôt Github: https://github.com/kvsnoufal/reinforce
Epaules de géants:
- Algorithmes de gradient de politique (https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html)
- Dériver RENFORCER (https://medium.com/@thechrisyoon/deriving-policy-gradients-and-implementing-reinforce-f887949bd63)
- Cours d'apprentissage de renforcement Udacity (https://github.com/udacity/deep-reinforcement-learning)
A propos de l'auteur

Noufal kv
Travailler chez Dubai Holding, Les EAU en tant que data scientist. Vous pouvez me contacter au [email protégé] O https://www.linkedin.com/in/kvsnoufal/





