Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
Fast.ai utilise des méthodes et des approches avancées d'apprentissage en profondeur pour générer des résultats de pointe. Cette approche que nous allons discuter nous permet de former des modèles plus précis, plus rapide, avec moins de données et en moins de temps et d'argent.
Fast.ai a été fondée par Jérémy Howard Oui raquel thomas fournir aux professionnels de l'apprentissage en profondeur un moyen rapide et facile d'obtenir des résultats de pointe dans les domaines d'apprentissage supervisé standard de l'apprentissage en profondeur, c'est-à-dire, Filtrage visuel, texte, tabulaire et collaboratif.
Commençons maintenant par Fast.ai.
Ce tutoriel suppose une compréhension de base de python3. Un ordinateur portable Jupyter avec un GPU est requis, comme le GPU accélère le processus de formation dans 100 fois par rapport au CPU. Vous pouvez y accéder depuis Collaboratif Google qui est un environnement d'ordinateur portable jupyter et fournit un GPU gratuit. Référer est pour activer le GPU gratuit dans Colab.
Former un classificateur d'images
Entraînons un classificateur d'images MNIST de base à l'aide de Fast.ai. L'ensemble de données MNIST se compose d'images de chiffres manuscrits du 0 Al 9. Donc, possède 10 classes et est un problème de classification multi-classes. Cela consiste en 60000 images dans l'ensemble de formation et 10000 images dans le jeu de validation.
Importations
Dans la première cellule, exécutez ce qui suit pour vous assurer que toutes les bibliothèques requises sont installées. Au contraire, la bibliothèque fastai sera installée et vous devrez redémarrer le runtime.
!pip install fastai --upgrade
Alors, importons la bibliothèque de vision fastai,
de fastai.vision.all import *
Si vous avez une expérience en programmation Python ou en développement de logiciels, vous vous demanderez s'il faut importer tous les sous-modules et fonctions de la classe (c'est-à-dire, utiliser *) c'est une pratique malsaine. Mais la bibliothèque fastai est conçue de telle manière que seules les fonctions requises sont importées et garantit qu'il n'y aura pas de charge inutile sur la mémoire.
Téléchargement de données
À présent, téléchargeons les données requises,
chemin = untar_data(URLs.MNIST)
Ici, nous utilisons une fonction fastai untar_data qui prend l'url de l'ensemble de données et télécharge et extrait l'ensemble de données, puis renvoie le chemin des données. Renvoie un Pathlib's Chemin Posix objet qui peut être utilisé pour accéder et naviguer facilement dans les systèmes de fichiers. Nous accédons à l'URL de l'ensemble de données MNIST depuis le fastai URL méthode composée d'URL de nombreux ensembles de données différents.
Nous pouvons vérifier le contenu du chemin en utilisant
#to list the contents
path.ls()
On voit qu'il y a deux dossiers. entraînement Oui essais composé de données d'entraînement et de données de validation, respectivement.
Chargement des données
Maintenant, nous pouvons charger les données,
dls = ImageDataLoaders.from_folder(chemin=chemin,
train='formation',
valid='test',
shuffle=Vrai)
Chargeurs de données d'images c'est l'un des types de classes que nous utilisons pour charger des ensembles de données pour des problèmes de vision par ordinateur. Généralement, les ensembles de données de vision par ordinateur sont structurés de manière à ce que la balise d'une image soit le nom du dossier dans lequel l'image est présente. Comment notre ensemble de données est structuré de cette façon, nous utilisons une méthode du_dossier pour charger des images à partir de dossiers dans le chemin donné.
Nous spécifions le chemin du jeu de données à partir duquel les images sont chargées par lots, nous spécifions le nom des dossiers constitués des données de formation et de validation qui seront utilisés pour la formation et la validation, puis on initialise mélanger une véritable, ce qui garantit que pendant que le modèle s'entraîne, les images sont mélangées et introduites dans le modèle.
Pour plus d'informations sur toute fonction fastai, nous pouvons utiliser la méthode doc () qui montre la courte documentation sur cette fonction.
doc(ImageDataLoaders.from_folder)
Nous pouvons voir certaines des données en utilisant show_batch () méthode,
dls.train.show_batch() dls.valid.show_batch()
Afficher respectivement quelques images de l'ensemble d'entraînement et de l'ensemble de validation.
Formation de modèle
Créons maintenant le modèle,
apprendre = cnn_learner(dls,
resnet18,
métriques=[précision, taux d'erreur])
Ici, nous utilisons cnn_learner c'est-à-dire, spécifier fastai pour construire un modèle de réseau neuronal convolutif à partir de l'architecture donnée, c'est-à-dire resnet18 et entraînez-vous sur le chargeur de données spécifié, c'est-à-dire dls et suivre les métriques fournies, c'est-à-dire précision Oui Taux d'erreur.
CNN est l'approche de pointe d'aujourd'hui pour la modélisation de la vision par ordinateur. Ici, nous utilisons une technique appelée transfert d'apprentissage pour former notre modèle. Cette technique utilise un Modèle préparé c'est-à-dire, une architecture standard et déjà formée pour un autre usage. Entrons dans les détails dans la section suivante.
Maintenant, entraînons-nous (en réalité, accordons-nous) modèle,
Nous pouvons voir que le modèle commence à s'entraîner avec des données pendant 4 époques. Les résultats ressemblent à ce qui suit,
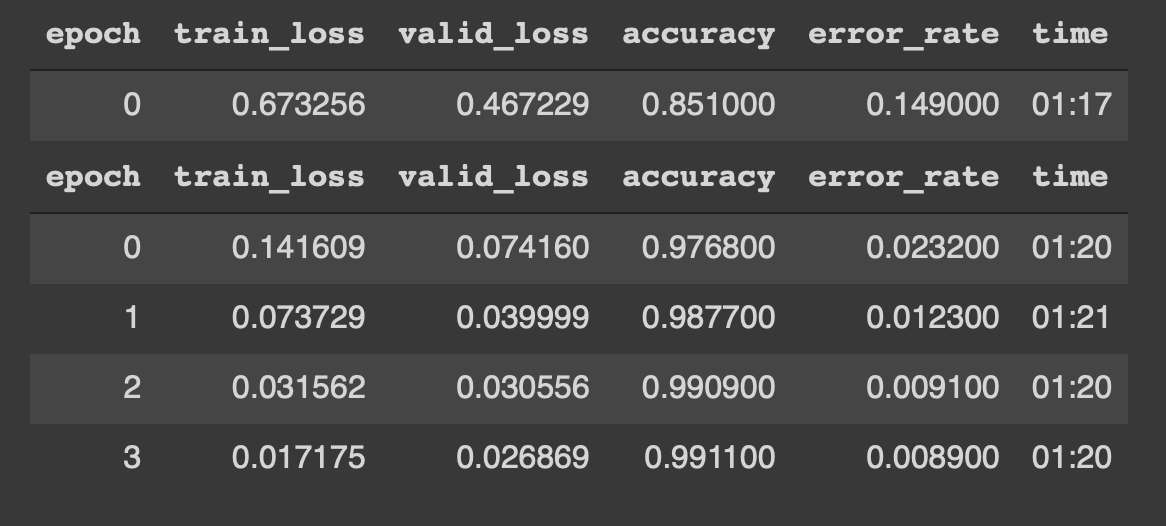
Waouh !! une précision de 99% et presque un 0,8% de error_rate sont, au sens propre, des résultats de pointe. En outre, nous avons pu y parvenir avec juste 4 époques, 5 lignes de code et 5 minutes de formation.
Mettre ensemble,
de fastai.vision.all import *
chemin = untar_data(URLs.MNIST)
dls = ImageDataLoaders.from_folder(chemin=chemin,
train='formation',
valid='test',
shuffle=Vrai)
apprendre = cnn_learner(dls,
resnet18,
métriques=[précision, taux d'erreur])
apprendre.fine_tune(4)
Ceci est possible grâce à une technique appelée Transférer l'apprentissage. Discutons-en un peu en détail.
Transférer l'apprentissage
avant de continuer, nous devons connaître les modèles pré-entraînés.
Modèles déjà formés ce sont essentiellement des architectures déjà formées sur un jeu de données différent et dans un but différent. Par exemple, Nous avons utilisé ressentiment18 comme notre réseau pré-formé. Aussi appelés réseaux résiduels, resent18 se compose de 18 couches et est formé sur plus d'un million d'images de l'ensemble de données ImageNet. Ce réseau pré-entraîné peut facilement classer les images en 1000 cours, comme des livres, des crayons, les animaux, etc. Donc, ce modèle connaît divers objets et choses avant même d'être entraîné sur notre ensemble de données. C'est pourquoi on l'appelle Préentrenada rouge.
À présent, l'apprentissage par transfert est la technique qui nous permet d'utiliser un modèle préalablement formé pour une nouvelle tâche et un nouvel ensemble de données. Transférer l'apprentissage il s'agit essentiellement du processus d'utilisation d'un modèle pré-entraîné pour une tâche différente de celle qui a été initialement formée, c'est-à-dire, dans ce cas, nous utilisons resent18 pour nous entraîner sur des images de chiffres manuscrits.
Ceci est possible grâce à une étape fondamentale appelée sintonie FINA. Lorsque nous avons un modèle préalablement formé, nous utilisons cette étape pour mettre à jour le modèle précédemment formé en fonction des besoins de notre tâche / Les données. Le réglage fin est essentiellement une technique d'apprentissage par transfert qui met à jour les poids du modèle pré-entraîné en s'entraînant pour certaines époques dans le nouvel ensemble de données..
Donc, En utilisant cette technique, nous pouvons obtenir des résultats de pointe dans notre tâche, c'est-à-dire, classer les chiffres manuscrits.
Faisons maintenant quelques prédictions
Prédire des images
Premier, obtenons tous les chemins d'images dans l'ensemble de test, puis convertissons-les en une image et faisons la prédiction.
# obtenir tous les chemins d'images du dossier de test images = get_image_files(chemin/'test')
# sélectionner une image et afficher img = PILImage.create(images[4432]) img
Prédire l'image
# prédire la classe d'image lb, _ , _ = apprendre.prédire(img) lbl
Rapport de classement
Nous pouvons également générer un rapport de classification à partir du modèle pour l'inférence.
interep = ClassificationInterprétation.from_learner(apprendre) interep.plot_confusion_matrix()
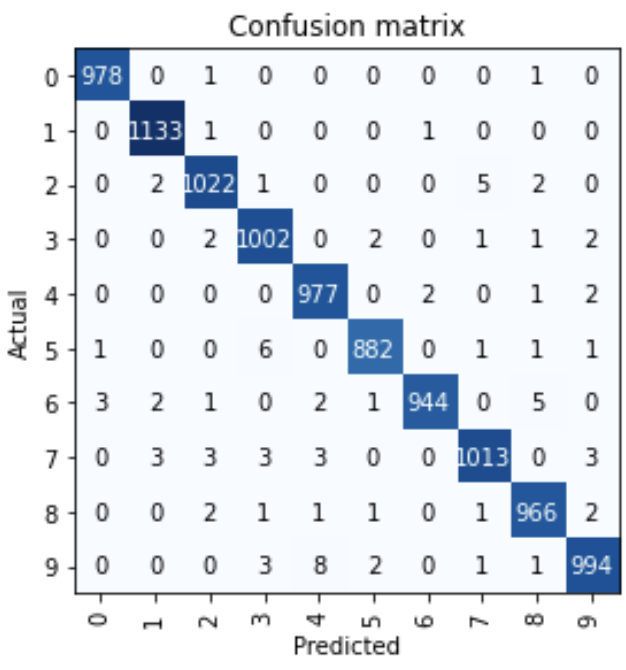
On voit presque 10000 images, seules quelques images ont été mal classées.
Merci et bon apprentissage en profondeur !!
Les références:
1. Apprentissage profond pratique pour les codeurs de Jeremy Howard et Sylvain Gugger
Par Narasimha Karthik J
Vous pouvez me contacter via Depuis le lien O Twitter
Les médias présentés dans cet article sur la création de modèles d'apprentissage en profondeur de nouvelle génération avec Fast.ai ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur..





