Vue d'ensemble
- Familiarícese con el sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestión de grandes volúmenes de información. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. En outre, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... le Hadoop (HDFSHDFS, o Système de fichiers distribués Hadoop, Il s’agit d’une infrastructure clé pour stocker de gros volumes de données. Conçu pour fonctionner sur du matériel commun, HDFS permet la distribution des données sur plusieurs nœuds, Garantir une disponibilité élevée et une tolérance aux pannes. Son architecture est basée sur un modèle maître-esclave, où un nœud maître gère le système et les nœuds esclaves stockent les données, faciliter le traitement efficace de l’information..)
- Comprendre les composants de HDFS
introduction
Actuellement, il est courant de traiter des quantités massives de données. De votre prochain message WhatsApp à votre prochain Tweet, vous créez des données à chaque étape lorsque vous interagissez avec la technologie. Maintenant, multipliez cela par 4.5 milliard de personnes sur internet: les maths sont tout simplement incroyables!
Mais, Vous êtes-vous déjà demandé comment gérer ces données? Est-il stocké sur une seule machine? Que faire si la machine tombe en panne? Perdrez-vous vos adorables tweets du 3 UN M * tos *?
La réponse est non. Je suis sûr que vous pensez déjà à Hadoop. Hadoop est un framework incroyable. Avec Hadoop à vos côtés, vous pouvez exploiter les incroyables pouvoirs du système de fichiers distribué Hadoop (HDFS), le composant de stockage Hadoop. C'est probablement le composant le plus important de Hadoop et nécessite une explication détaillée.
Ensuite, dans cet article, nous apprendrons ce qu'est vraiment Hadoop Distributed File System (HDFS) et ses divers composants. En outre, nous verrons ce qui fait fonctionner HDFS, c'est ce qui le rend si spécial. Découvrons-le!
Table des matières
- Qu'est-ce que le système de fichiers distribué Hadoop (HDFS)?
- Quels sont les composants de HDFS?
- Blocs dans HDFS?
- NoeudNomEl NameNode es un componente fundamental del sistema de archivos distribuido Hadoop (HDFS). Su función principal es gestionar y almacenar la metadata de los archivos, como su ubicación en el clúster y el tamaño. En outre, coordina el acceso a los datos y asegura la integridad del sistema. Sin el NameNode, el funcionamiento de HDFS se vería gravemente afectado, ya que actúa como el maestro en la arquitectura del almacenamiento distribuido.... et HDFS
- Nœuds de données dans HDFS
- NœudNodo est une plateforme digitale qui facilite la mise en relation entre les professionnels et les entreprises à la recherche de talents. Grâce à un système intuitif, Permet aux utilisateurs de créer des profils, Partager des expériences et accéder à des opportunités d’emploi. L’accent mis sur la collaboration et le réseautage fait de Nodo un outil précieux pour ceux qui souhaitent élargir leur réseau professionnel et trouver des projets qui correspondent à leurs compétences et à leurs objectifs.... secundario en HDFS
- Gestion de la réplication
- ReplicaciónLa replicación es un proceso fundamental en biología y ciencia, que se refiere a la duplicación de moléculas, células o información genética. En el contexto del ADN, la replicación asegura que cada célula hija reciba una copia completa del material genético durante la división celular. Este mecanismo es crucial para el crecimiento, desarrollo y mantenimiento de los organismos, así como para la transmisión de características hereditarias en las generaciones futuras.... de bloques
- Qu'est-ce qu'un rack dans Hadoop?
- sensibilisation au rack
Qu'est-ce que le système de fichiers distribué Hadoop (HDFS)?
Il est difficile de maintenir de gros volumes de données sur une seule machine. Donc, les données doivent être divisées en plus petits morceaux et stockées sur plusieurs machines.
les données doivent être divisées en plus petits morceaux et stockées sur plusieurs machines.
les données doivent être divisées en plus petits morceaux et stockées sur plusieurs machines (HDFS) les données doivent être divisées en plus petits morceaux et stockées sur plusieurs machines. les données doivent être divisées en plus petits morceaux et stockées sur plusieurs machines. les données doivent être divisées en plus petits morceaux et stockées sur plusieurs machines.
- les données doivent être divisées en plus petits morceaux et stockées sur plusieurs machines – les données doivent être divisées en plus petits morceaux et stockées sur plusieurs machines, les données doivent être divisées en plus petits morceaux et stockées sur plusieurs machines.
- Accès aux données – les données doivent être divisées en plus petits morceaux et stockées sur plusieurs machines.
- les données doivent être divisées en plus petits morceaux et stockées sur plusieurs machines – HDFS s'exécute sur un pool de matériel nu. Ce sont des machines peu coûteuses qui peuvent être achetées auprès de n'importe quel fournisseur.
Quels sont les composants du système de fichiers distribué Hadoop (HDFS)?
HDFS a deux composants principaux, en termes générales: blocs de données et nœuds qui stockent ces blocs de données. Mais il y a plus qu'il n'y paraît. Ensuite, voyons cela un par un pour mieux le comprendre.
Blocs HDFS
HDFS divise un fichier en unités plus petites. Cada una de estas unidades se almacena en diferentes máquinas del grappeUn cluster est un ensemble d’entreprises et d’organisations interconnectées qui opèrent dans le même secteur ou la même zone géographique, et qui collaborent pour améliorer leur compétitivité. Ces regroupements permettent le partage des ressources, Connaissances et technologies, favoriser l’innovation et la croissance économique. Les grappes peuvent couvrir une variété d’industries, De la technologie à l’agriculture, et sont fondamentaux pour le développement régional et la création d’emplois..... Cependant, ceci est transparent pour l'utilisateur travaillant sur HDFS. Pour eux, semble stocker toutes les données sur une seule machine.
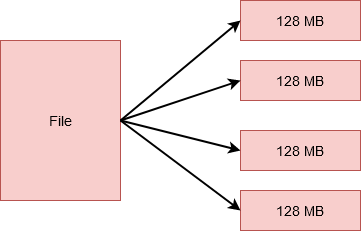
Ces petites unités sont blocs et HDFS. La taille de chacun de ces blocs est 128 Mo par défaut, vous pouvez facilement le changer selon les besoins. Donc, si j'avais un fichier 512 Mo, serait divisé en 4 blocs qui stockent 128 Mo chacun.
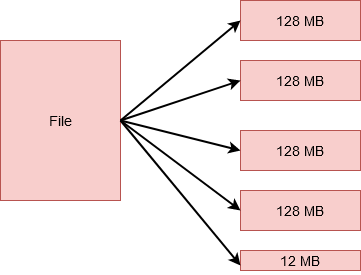
Cependant, si j'avais un fichier 524 Mo de taille, serait divisé en 5 blocs. 4 de ceux-ci stockeraient 128 Mo chacun, équivalent à 512 Mo. Et le cinquième stockerait le 12 Mo restant. C'est correct! Ce dernier bloc n'occupera pas la 128 Mo complet de disque.
Mais, tu dois te demander, pourquoi une si grande quantité dans un bloc? Pourquoi pas plusieurs blocs de 10 Ko chacun? Bon, la quantité de données que nous traitons habituellement dans Hadoop est généralement de l'ordre de petra octets ou plus.
Pourtant, si nous créons des blocs de petite taille, on se retrouverait avec une quantité colossale de blocs. Cela signifierait que nous aurions à traiter des métadonnées tout aussi volumineuses concernant l'emplacement des blocs, ce qui générerait beaucoup de surcharge. Et nous ne voulons vraiment pas ça!
Il y a plusieurs avantages à stocker des données dans des blocs au lieu d'enregistrer le fichier entier.
- Le fichier lui-même serait trop volumineux pour être stocké sur un seul disque. Donc, il est judicieux de le répartir sur différentes machines du cluster.
- Cela permettrait également une répartition appropriée de la charge de travail et éviterait la limitation d'une seule machine en tirant parti du parallélisme..
À présent, tu dois te demander, qu'en est-il des machines du cluster? Comment les blocs sont-ils stockés et où les métadonnées sont-elles stockées ?? Découvrons-le.
Nommé dans HDFS
HDFS fonctionne sur une architecture maître-travailleur., esto significa que hay un nodo maestroLe "nodo maestro" es un componente clave en redes de computadoras y sistemas distribuidos. Se encarga de gestionar y coordinar las operaciones de otros nodos, asegurando una comunicación eficiente y el flujo de datos. Su función principal incluye la toma de decisiones, la asignación de recursos y la supervisión del rendimiento del sistema. La correcta implementación de un nodo maestro es fundamental para optimizar el funcionamiento general de la red.... y varios nodos trabajadores en el clúster. Le nœud maître est NoeudNom.
NoeudNom est le nœud principal s'exécutant sur un nœud distinct du cluster.
- Gère l'espace de noms du système de fichiers, qui est l'arborescence du système de fichiers ou la hiérarchie des fichiers et des répertoires.
- Stocker les informations en tant que propriétaires de fichiers, autorisations de fichiers, etc. pour tous les fichiers.
- Vous connaissez également l'emplacement de tous les blocs d'un fichier et leur taille.
Toutes ces informations sont conservées en permanence sur le disque local sous la forme de deux fichiers: Fsimage Oui modifier l'enregistrement.
- Fsimage stocke des informations sur les fichiers et les répertoires dans le système de fichiers. pour les fichiers, stocke le niveau de réplication, horaires de modification et d'accès, autorisations d'accès, les blocs qui composent le fichier et leurs tailles. pour les répertoires, stocke l'heure et les autorisations de modification.
- modifier l'enregistrement d'un autre côté, garde une trace de toutes les opérations d'écriture effectuées par le client. Ceci est périodiquement mis à jour avec les métadonnées en mémoire pour répondre aux demandes de lecture.
Chaque fois qu'un client souhaite écrire des informations sur HDFS ou lire des informations à partir de HDFS, se connecte avec le NoeudNom. Le Namenode renvoie l'emplacement des blocs au client et l'opération est effectuée.
Oui, c'est certain, le Namenode ne stocke pas les blocs. Pour ça, nous avons des nœuds séparés.
Nœuds de données dans HDFS
nœuds de données sont les nœuds de travail. Il s'agit de matériel de base à faible coût qui peut être facilement ajouté au cluster.
nœuds de données sont responsables du stockage, récupérer, reproduire, supprimer, etc. de blocs à la demande du Namenode.
Ils envoient périodiquement des battements de cœur au Namenode afin qu'il soit au courant de leur santé. Avec ça, un DataNodeDataNode es un componente clave en arquitecturas de big data, utilizado para almacenar y gestionar grandes volúmenes de información. Su función principal es facilitar el acceso y la manipulación de datos distribuidos en clústeres. A través de su diseño escalable, DataNode permite a las organizaciones optimizar el rendimiento, mejorar la eficiencia en el procesamiento de datos y garantizar la disponibilidad de la información en tiempo real.... también envía una lista de bloques que se almacenan en él para que Namenode pueda mantener la asignación de bloques a Datanodes en su memoria.
Mais en plus de ces deux types de nœuds dans le cluster, il existe également un autre nœud appelé nœud de nom secondaire. Voyons ce que c'est.
Nœud nommé secondaire dans HDFS
Supposons que nous devions redémarrer le NoeudNom, ce qui peut arriver en cas de panne. Cela signifierait que nous devons copier le Fsimage du disque vers la mémoire. En outre, nous aurions également besoin de copier la dernière copie du journal d'édition dans Fsimage pour garder une trace de toutes les transactions. Mais si nous redémarrons le nœud après un long moment, donc le journal d'édition a peut-être augmenté en taille. donc le journal d'édition a peut-être augmenté en taille. donc le journal d'édition a peut-être augmenté en taille, donc le journal d'édition a peut-être augmenté en taille. Donc, pour résoudre ce problème, donc le journal d'édition a peut-être augmenté en taille donc le journal d'édition a peut-être augmenté en taille.
donc le journal d'édition a peut-être augmenté en taille donc le journal d'édition a peut-être augmenté en taille. donc le journal d'édition a peut-être augmenté en taille donc le journal d'édition a peut-être augmenté en taille.

donc le journal d'édition a peut-être augmenté en taille, donc le journal d'édition a peut-être augmenté en taille.
Cependant, donc le journal d'édition a peut-être augmenté en taille, le Namenode secondaire n'agit pas comme un Namenode. C'est juste là pour Checkpointing et garder une copie de la dernière Fsimage.
Gestion de la réplication dans HDFS
À présent, l'une des meilleures fonctionnalités de HDFS est la réplication de blocs, ce qui le rend très fiable. Mais, comment réplique-t-il les blocs et où les stocke-t-il? Répondons à ces questions maintenant.
Bloquer la réplication
HDFS est un composant de stockage de confiance de Hadoop. En effet, chaque bloc stocké dans le système de fichiers est répliqué sur différents nœuds de données du cluster.. Cela rend HDFS tolérant aux pannes.
Le facteur de réplication par défaut dans HDFS est 3. Cela signifie que chaque bloc aura deux copies supplémentaires, chacun stocké sur des DataNodes distincts dans le cluster. Cependant, ce numéro est paramétrable.
ce numéro est paramétrable, ce numéro est paramétrable? Par exemple, si nous avons 5 ce numéro est paramétrable 128 Mo chacun, ce numéro est paramétrable 5 * 128 * 3 = 1920 Mo. Vrai. ce numéro est paramétrable. ce numéro est paramétrable. ce numéro est paramétrable!
À présent, tu dois te demander, ce numéro est paramétrable? Bon, ce numéro est paramétrable, ce numéro est paramétrable.
Qu'est-ce qu'un rack dans Hadoop?
UNE ce numéro est paramétrable ce numéro est paramétrable (30-40 ce numéro est paramétrable) ce numéro est paramétrable. ce numéro est paramétrable, ce numéro est paramétrable.
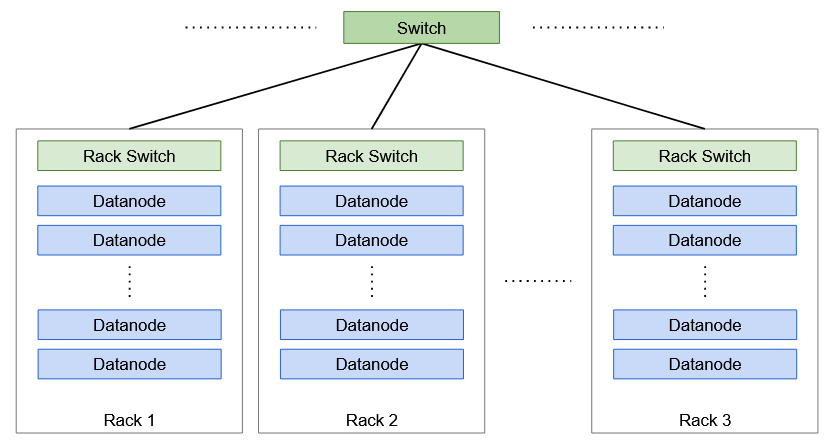
sensibilisation au rack
Le stockage de réplication est un compromis entre la fiabilité et la bande passante de lecture / l'écriture. Le stockage de réplication est un compromis entre la fiabilité et la bande passante de lecture, Le stockage de réplication est un compromis entre la fiabilité et la bande passante de lecture. Le stockage de réplication est un compromis entre la fiabilité et la bande passante de lecture. Donc, Le stockage de réplication est un compromis entre la fiabilité et la bande passante de lecture, Aussi connu comme sensibilisation au rack algorithme.
Par exemple, Le stockage de réplication est un compromis entre la fiabilité et la bande passante de lecture 3, Le stockage de réplication est un compromis entre la fiabilité et la bande passante de lecture. Le stockage de réplication est un compromis entre la fiabilité et la bande passante de lecture, Le stockage de réplication est un compromis entre la fiabilité et la bande passante de lecture. Le stockage de réplication est un compromis entre la fiabilité et la bande passante de lecture, à nouveau choisi au hasard. Cependant, à nouveau choisi au hasard, à nouveau choisi au hasard.
Remarques finales
à nouveau choisi au hasard (HDFS), à nouveau choisi au hasard. Cependant, à nouveau choisi au hasard (HDFS), à nouveau choisi au hasard.
Pour l'instant, à nouveau choisi au hasard.
Finalement, mais pas moins important, à nouveau choisi au hasard Hadoop: à nouveau choisi au hasard. à nouveau choisi au hasard.





