introduction
Tous les modèles sont faux, mais certains sont utiles – Boîte George
L'analyse de régression marque la première étape de la modélisation prédictive. Sans doute, c'est assez simple à mettre en oeuvre. Ni sa syntaxe ni ses paramètres ne créent de confusion. Mais, il suffit d'exécuter une seule ligne de code, ne résout pas le but. Pas seulement en regardant les valeurs R² ou MSE. La régression en dit bien plus que cela !!
Un R, retours d'analyse de régression 4 graphiques utilisant plot(model_name) une fonction. Chacun des graphiques fournit des informations importantes ou plutôt une histoire intéressante sur les données. Malheureusement, beaucoup de débutants ne parviennent pas à déchiffrer les informations ou ne se soucient pas de ce que disent ces intrigues. Une fois que vous avez compris ces graphiques, vous pouvez apporter une amélioration significative à votre modèle de régression.
Pour améliorer le modèle, vous devez également comprendre les hypothèses de régression et les moyens de les corriger lorsqu'elles sont violées.
Dans cet article, J'ai expliqué les hypothèses de régression et les graphiques importants (avec des correctifs et des solutions) pour vous aider à comprendre le concept de régression plus en détail. Comme indiqué ci-dessus, avec cette connaissance, vous pouvez apporter des améliorations drastiques à vos modèles.
Noter: Pour comprendre ces graphiques, doit connaître les bases de l'analyse de régression. Si vous êtes complètement nouveau, tu peux commencer ici. Alors, continuer avec cet article.

Hypothèses de régression
La régression est une approche paramétrique. 'Paramétrique’ signifie que vous faites des hypothèses sur les données à des fins d'analyse. En raison de son côté paramétrique, la régression est de nature restrictive. Ne fonctionne pas bien avec des ensembles de données qui ne répondent pas à vos hypothèses. Donc, pour une analyse de régression réussie, il est essentiel de valider ces hypothèses.
Ensuite, Comment vérifieriez-vous (validerait) si un ensemble de données suit toutes les hypothèses de régression? Vérifiez-le à l'aide de graphiques de régression (expliqué ci-dessous) avec quelques preuves statistiques.
Examinons les hypothèses importantes dans l'analyse de régression:
- Il doit y avoir une relation linéaire et additive entre la variable dépendante (réponse) et la variable indépendante (prédicteur). Une relation linéaire suggère qu'un changement de réponse Y dû à un changement d'une unité de X¹ est constant, quelle que soit la valeur de X¹. Une relation additive suggère que l'effet de X¹ sur Y est indépendant des autres variables.
- Il ne doit pas y avoir de corrélation entre les termes résiduels (Erreur). L'absence de ce phénomène est connue sous le nom d'autocorrélation..
- Les variables indépendantes ne doivent pas être corrélées. L'absence de ce phénomène est connue sous le nom de multicolinéarité..
- Les termes d'erreur doivent avoir une variance constante. Ce phénomène est connu sous le nom d'homoscédasticité.. La présence de variance non constante fait référence à l'hétéroscédasticité.
- Les termes d'erreur doivent être distribués normalement.
Que faire si ces hypothèses sont violées?
Analysons des hypothèses spécifiques et découvrons vos résultats (si elles sont violées):
1. Linéaire et additif: Si vous ajustez un modèle linéaire à un ensemble de données non linéaires et non additives, l'algorithme de régression ne capturerait pas la tendance mathématiquement, ce qui aboutirait à un modèle inefficace. En outre, cela entraînera des prédictions erronées dans un ensemble de données invisible.
Comment vérifier: Recherchez les graphiques des valeurs résiduelles par rapport aux valeurs ajustées (expliqué ci-dessous). En outre, peut inclure des termes polynomiaux (X, X², X³) dans votre modèle pour capturer l'effet non linéaire.
2. Autocorrélation: La présence de corrélation en termes d'erreur réduit considérablement la précision du modèle. Cela se produit généralement dans les modèles de séries temporelles où l'instant suivant dépend de l'instant précédent.. Si les termes d'erreur sont corrélés, les erreurs-types estimées ont tendance à sous-estimer la véritable erreur-type.
Si ça arrive, rend les intervalles de confiance et les intervalles de prédiction plus étroits. Un intervalle de confiance plus étroit signifie qu'un intervalle de confiance du 95% aurait une probabilité inférieure à 0,95 contenir la valeur réelle des coefficients. Comprenons les intervalles de prédiction étroits avec un exemple:
Par exemple, le coefficient des moindres carrés de X¹ est 15.02 et son erreur standard est 2.08 (pas d'autocorrélation). Mais en présence d'autocorrélation, l'erreur standard est réduite à 1,20. Par conséquent, l'intervalle de prédiction est réduit à (13.82, 16.22) depuis (12.94, 17.10).
En outre, des erreurs types plus faibles rendraient les valeurs p associées inférieures aux valeurs réelles. Cela nous amènera à conclure à tort qu'un paramètre est statistiquement significatif..
Comment vérifier: Recherchez la statistique Durbin-Watson (DW). Doit être entre 0 Oui 4. Si DW = 2, n'implique pas d'autocorrélation, 0 <DW <2 implique une autocorrélation positive tandis que 2 <DW <4 indique une autocorrélation négative. En outre, vous pouvez afficher le tracé des résidus en fonction du temps et rechercher le modèle saisonnier ou corrélé dans les résidus.
3. Multicolinéarité: Ce phénomène existe lorsque les variables indépendantes ont une corrélation modérée ou élevée. Dans un modèle à variables corrélées, il devient difficile de découvrir la véritable relation d'un prédicteur avec une variable de réponse. En d'autres termes, difficile de déterminer quelle variable contribue réellement à prédire la variable de réponse.
Un autre point, avec présence de prédicteurs corrélés, les erreurs types ont tendance à augmenter. Oui, avec de grandes erreurs standard, l'intervalle de confiance s'élargit, conduisant à des estimations moins précises des paramètres de pente.
En outre, quand les prédicteurs sont corrélés, le coefficient de régression estimé d'une variable corrélée dépend des autres prédicteurs disponibles dans le modèle. Si ça arrive, vous vous retrouverez avec une conclusion erronée qu'une variable affecte fortement / faiblement à la variable cible. Étant donné que, même si vous supprimez une variable corrélée du modèle, vos coefficients de régression estimés changeraient. Ce n'est pas bon!
Comment vérifier: Vous pouvez utiliser le nuage de points pour visualiser l'effet de corrélation entre les variables. En outre, vous pouvez également utiliser le facteur VIF. La valeur de VIF = 10 implique une multicolinéarité sérieuse. Surtout, un tableau de correspondance devrait également résoudre le problème.
4. Hétéroscédasticité: La présence d'une variance non constante dans les termes d'erreur entraîne une hétéroscédasticité. Généralement, une variance non constante survient en présence de valeurs aberrantes ou de valeurs d'effet de levier extrêmes. Ces valeurs semblent avoir trop de poids, ils influencent donc de manière disproportionnée les performances du modèle. Lorsque ce phénomène se produit, l'intervalle de confiance pour la prédiction hors échantillon a tendance à être trop large ou étroit.
Comment vérifier: Vous pouvez voir le tracé des résidus par rapport à l'ajustement. S'il y a hétéroscédasticité, le graphique affichera un motif en forme d'entonnoir (montré dans la section suivante). En outre, vous pouvez utiliser le test de Breusch-Pagan / cuisiner – Test général de Weisberg ou White pour détecter ce phénomène.
5. Distribution normale des termes d'erreur: Si les termes d'erreur ne sont pas distribués normalement, les intervalles de confiance peuvent devenir trop larges ou trop étroits. Une fois que l'intervalle de confiance devient instable, l'estimation des coefficients basée sur la minimisation des moindres carrés est difficile. La présence d'une distribution anormale suggère qu'il existe des points de données inhabituels qui doivent être étudiés de près pour créer un meilleur modèle..
Comment vérifier: Vous pouvez voir le graphique QQ (indiqué ci-dessous). Vous pouvez également effectuer des tests statistiques de normalité tels que le test de Kolmogorov-Smirnov., le test de Shapiro-Wilk.
Interprétation des graphiques de régression
Jusqu'ici, nous avons appris d'importantes hypothèses de régression et des méthodes pour entreprendre, si ces hypothèses sont violées.
Mais ce n'est pas la fin. À présent, vous devez également connaître les solutions pour remédier à la violation de ces hypothèses. Dans cette section, j'ai expliqué le 4 des graphiques de régression ainsi que des méthodes pour surmonter les limites des hypothèses.
1. Valeurs résiduelles vs valeurs ajustées
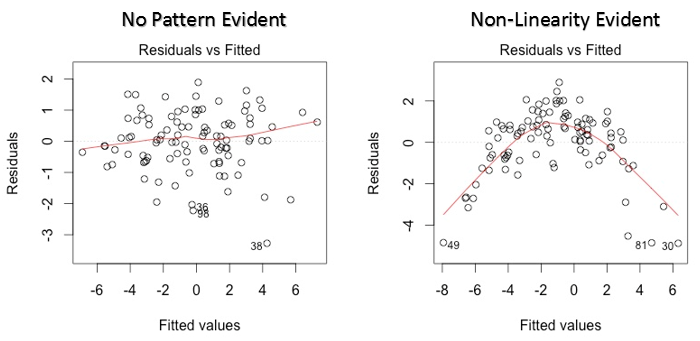
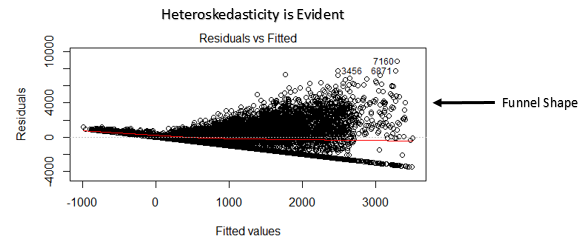
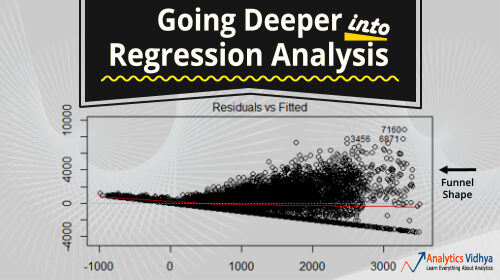
Ce nuage de points montre la distribution des résidus (erreurs) par rapport aux valeurs ajustées (valeurs prédites). C'est l'une des intrigues les plus importantes que tout le monde devrait apprendre. Révèle diverses informations utiles, y compris les valeurs aberrantes. Les valeurs aberrantes dans ce graphique sont étiquetées par leur numéro d'observation, ce qui les rend faciles à repérer.
Il y a deux choses importantes que vous devez apprendre:
- S'il y a un modèle (Peut être, une forme parabolique) dans ce graphique, le considérer comme des signes de non-linéarité dans les données. Cela signifie que le modèle ne capture pas les effets non linéaires.
- Si la forme d'un entonnoir est évidente dans le graphique, le considérer comme un signe de variance non constante, c'est-à-dire, hétéroscédasticité.
Solution: Pour surmonter le problème de la non-linéarité, vous pouvez faire une transformation non linéaire de prédicteurs comme log (X), √X ou X² transforment la variable dépendante. Pour surmonter l'hétéroscédasticité, une façon possible est de transformer la variable de réponse en log (Oui) le Y. En outre, vous pouvez utiliser la méthode des moindres carrés pondérés pour traiter l'hétéroscédasticité.
2. Graphique QQ normal
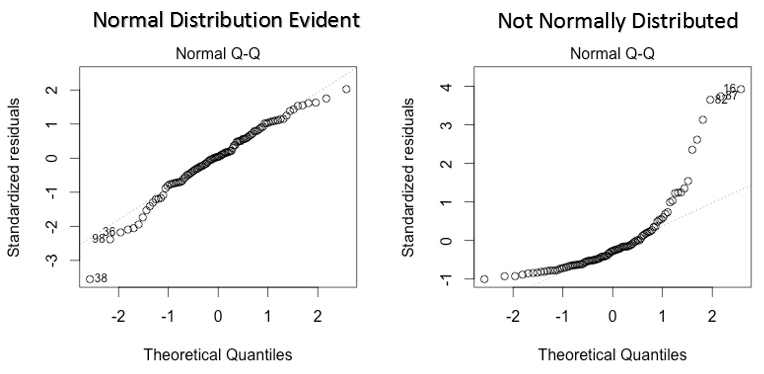
Ce qq ou quantile-quantile est un diagramme de dispersion qui nous aide à valider l'hypothèse de distribution normale dans un ensemble de données. En utilisant ce graphique, nous pouvons déduire si les données proviennent d'une distribution normale. Le cas échéant, le graphique montrerait une ligne assez droite. Il y a une absence de normalité dans les erreurs avec déviation en ligne droite.
Si vous vous demandez ce qu'est un "quantile", voici une définition simple: Considérez les quantiles comme des points dans vos données en dessous desquels se situe une certaine proportion de données. Le quantile est souvent appelé centile. Par exemple: quand on dit que la valeur centile 50 il est 120, signifie que la moitié des données est en dessous 120.
Solution: Si les erreurs ne sont pas distribuées normalement, la transformation non linéaire des variables (réponse ou prédicteurs) peut apporter une amélioration du modèle.
3. Tableau d'emplacement à l'échelle
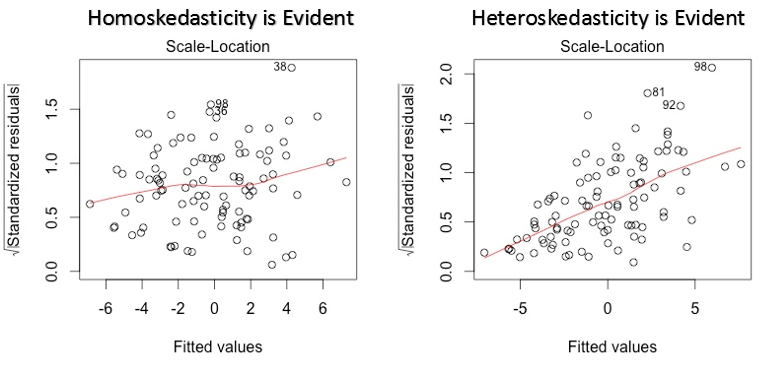
Ce graphique est également utilisé pour détecter l'homoscédasticité (hypothèse de variance égale). Montre comment les résidus sont distribués sur la plage de prédicteurs.. Il est similaire au graphique valeur résiduelle vs ajusté, sauf qu'il utilise des valeurs résiduelles standardisées. Idéalement, il ne devrait y avoir aucun motif discernable dans l'intrigue. Cela impliquerait que les erreurs sont normalement distribuées. Mais, au cas où le graphique montre un motif discernable (probablement une forme d'entonnoir), impliquerait une distribution d'erreur non normale.
Solution: Suivez la solution pour l'hétéroscédasticité donnée dans le graphique 1.
4. Graphique résiduel vs effet de levier
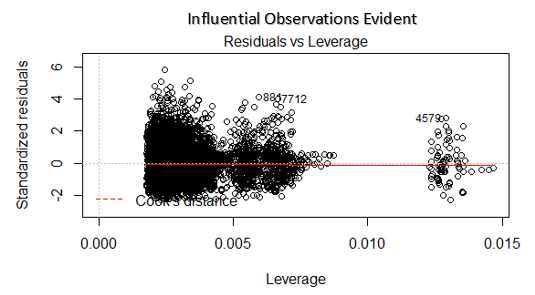
Également connu sous le nom de diagramme de distance de Cook. La distance de Cook essaie d'identifier les points qui ont plus d'influence que les autres points. De tels points d'influence ont tendance à avoir un impact considérable sur la droite de régression.. En d'autres termes, l'ajout ou la suppression de tels points du modèle peut changer complètement les statistiques du modèle.
Mais, Ces observations influentes peuvent-elles être traitées comme des valeurs aberrantes ?? Cette question ne peut être répondue qu'après avoir examiné les données. Donc, dans ce graphique, les grandes valeurs marquées par la distance de cuisson peuvent nécessiter une enquête plus approfondie.
Solution: Pour influencer les observations qui ne sont rien de plus que des valeurs aberrantes, oui pas beaucoup, vous pouvez supprimer ces lignes. Alternativement, vous pouvez réduire l'observation des valeurs aberrantes avec la valeur maximale dans les données ou traiter ces valeurs comme des valeurs manquantes.
Cas d'étude: Comment j'ai amélioré mon modèle de régression en utilisant la transformation logarithmique
Remarques finales
Vous pouvez exploiter la véritable puissance de l'analyse de régression en appliquant les solutions décrites ci-dessus.. La mise en œuvre de ces correctifs dans R est assez facile. Si vous voulez connaître une solution spécifique dans R, Vous pouvez laisser un commentaire, Je serai heureux de vous aider avec les réponses..
Le but de cet article était de vous aider à acquérir la compréhension et la perspective sous-jacentes des diagrammes de régression et des hypothèses.. De cette manière, vous aurez plus de contrôle sur votre analyse et pourrez modifier l'analyse selon vos besoins.
Avez-vous trouvé cet article utile? Avez-vous utilisé ces correctifs pour améliorer les performances du modèle? Partagez votre expérience / suggestions dans les commentaires.





