[*]
Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
conditions météorologiques. Son datos con un tamaño y complejidad tan grandes que ninguna de las herramientas tradicionales de administración de datos los almacenará o procesará con eficiencia.
Big Data es un campo que trata las formas de investigar, analizar y extraer información de forma consistente de una gran cantidad de datos estructurados o no estructurados.
Python tiene varias características incorporadas para admitir el procesamiento de datos, ya sea de tamaño pequeño o enorme. Estas funciones admiten el procesamiento de datos no estructurados y no convencionales. Esta es la razón por la que los científicos de datos y las empresas de Big Data prefieren elegir Python para el procesamiento de datos, ya que se considera uno de los requisitos más importantes en Big Data.
También existen otras tecnologías que pueden procesar Big Data de manera más eficiente que Python. Son Hadoop y Spark.
Hadoop
Hadoop es la mejor solución para almacenar y procesar Big Data porque Hadoop almacena archivos enormes en forma de sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestión de grandes volúmenes de información. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. En outre, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... (HDFSHDFS, o Système de fichiers distribués Hadoop, Il s’agit d’une infrastructure clé pour stocker de gros volumes de données. Conçu pour fonctionner sur du matériel commun, HDFS permet la distribution des données sur plusieurs nœuds, Garantir une disponibilité élevée et une tolérance aux pannes. Son architecture est basée sur un modèle maître-esclave, où un nœud maître gère le système et les nœuds esclaves stockent les données, faciliter le traitement efficace de l’information..) Hadoop sin especificar ningún esquema.
C'est très évolutif, ya que se puede agregar cualquier número de nodos para mejorar el rendimiento. En Hadoop, los datos están altamente disponibles si también se produce algún fallo de hardware.
Étincelle – étincelle
Spark también es una buena opción para procesar una gran cantidad de conjuntos de datos estructurados o no estructurados, ya que los datos se almacenan en clústeres. Spark concebirá almacenar la máxima cantidad de datos en la memoria para que se derramen en el disco. Almacenará una parte del conjunto de datos en la memoria y, donc, los datos restantes en el disco.
La primera opción de lenguaje de Toady Data Scientist es Python y tanto Hadoop como Spark proporcionan API de Python que brindan procesamiento de Big Data y también permiten un fácil acceso a las plataformas de Big Data.
Source de l'image: por mi
Necesidad de Python en Big Data
1. Open source:
Python es un lenguaje de programación de código abierto desarrollado a continuación bajo una licencia de suministro abierto aprobada por OSI, lo que lo crea libremente utilizable y distribuible, incluso para uso comercial.
Python es un lenguaje interpretado de alto nivel y de propósito general. No es necesario compilarlo para ejecutarse. Un programa conocido como intérprete ejecuta código Python en prácticamente cualquier tipo de sistema. Esto implica que un desarrollador puede modificar el código y ver rápidamente los resultados.
2. Facile à apprendre:
Python es muy fácil de aprender al igual que el idioma inglés. Su sintaxis y código son fáciles y legibles también para principiantes. Python tiene muchas aplicaciones como el desarrollo de aplicaciones web, science des données, apprentissage automatique, etc.
Python nos permite escribir programas con menos líneas de código que la mayoría de los otros lenguajes de programación. La popularidad de Python está creciendo rápidamente debido a su simplicidad.
3. Bibliotecas de procesamiento de datos:
Cuando se trata de procesamiento de datos, Python a un
rico conjunto de herramientas con una amplia gama de beneficios. Como es un lenguaje de código abierto, es fácil de aprender y también mejora continuamente. Python consiste en una lista de varias bibliotecas útiles para el procesamiento de datos y también integradas con otros lenguajes (como Java), así como con estructuras existentes. Python es más rico en bibliotecas que mejoran aún más su funcionalidad.
4. Compatibilidad con Hadoop y Spark:
El marco de Hadoop está escrito en lenguaje Java; cependant, los programas de Hadoop se pueden codificar en lenguaje Python o C ++. Podemos escribir programas como MapReduce en lenguaje Python, aunque no es el requisito para traducir el código a archivos jar de Java.
Spark proporciona una API de Python llamada PySpark lanzada por la comunidad de Apache Spark para admitir Python con Spark. Usando PySpark, uno simplemente integrará y trabajará con RDD dentro del lenguaje de programación Python también.
Spark viene con un shell de Python interactivo llamado PySpark shell. Este shell de PySpark es responsable del enlace entre la API de Python y el núcleo de chispa y de inicializar el contexto de chispa. PySpark también se puede iniciar directamente desde la línea de comando dando algunas instrucciones para uso interactivo.
5. Velocidad y eficiencia:
Python es un lenguaje de programación de alto nivel poderoso y eficiente. Ya sea para desarrollar una aplicación o trabajar para resolver cualquier problema comercial a través de la ciencia de datos, Python lo tiene cubierto todos estos límites. Python siempre funciona bien para optimizar la productividad y la eficiencia de los desarrolladores.
Podemos crear rápidamente un programa que puede resolver un problema comercial y satisface una necesidad práctica. Cependant,
Es posible que las soluciones no alcancen el rendimiento optimizado de Python mientras se desarrollan rápidamente.
6. Escalable y flexible:
Python es el lenguaje más popular para ML / AI debido a su conveniencia. La flexibilidad de Python también permite instrumentar el código de Python para formar la escalabilidad ML / AI posiblemente sin requerir una mayor experiencia en el sistema distribuido y muchos cambios de código invasivos. Donc, los usuarios de ML / AI obtienen las ventajas de la escalabilidad en todo el clúster con un esfuerzo mínimo.
Componentes de Hadoop:
Hay principalmente dos componentes de Hadoop:
- HDFS (Système de fichiers distribué Hadoop)
- Petite carte
Sistema de archivos distribuido Hadoop
El sistema de archivos Hadoop se desarrolló sobre la base del modelo de sistema de archivos distribuido. Funciona con hardware básico. A diferencia de los diferentes sistemas distribuidos, HDFS es extremadamente tolerante a fallas y está diseñado con hardware económico.
HDFS puede almacenar una gran cantidad de datos y también proporciona un acceso más fácil a esos datos. Para almacenar una cantidad tan grande de datos, los archivos se almacenan en múltiples sistemas. Estos archivos se almacenan de manera redundante para rescatar al sistema de posibles pérdidas de datos en caso de falla. En outre, HDFS ofrece aplicaciones para multiprocesamiento.
- Es responsable de almacenar datos en un grappeUn cluster est un ensemble d’entreprises et d’organisations interconnectées qui opèrent dans le même secteur ou la même zone géographique, et qui collaborent pour améliorer leur compétitivité. Ces regroupements permettent le partage des ressources, Connaissances et technologies, favoriser l’innovation et la croissance économique. Les grappes peuvent couvrir une variété d’industries, De la technologie à l’agriculture, et sont fondamentaux pour le développement régional et la création d’emplois.... como almacenamiento y procesamiento distribuidos.
- Los servidores de datos del nœudNodo est une plateforme digitale qui facilite la mise en relation entre les professionnels et les entreprises à la recherche de talents. Grâce à un système intuitif, Permet aux utilisateurs de créer des profils, Partager des expériences et accéder à des opportunités d’emploi. L’accent mis sur la collaboration et le réseautage fait de Nodo un outil précieux pour ceux qui souhaitent élargir leur réseau professionnel et trouver des projets qui correspondent à leurs compétences et à leurs objectifs.... de nombre y del nodo de conocimiento facilitan a los usuarios comprobar simplemente el estado del clúster.
- Cada bloque se replica varias veces de forma predeterminada 3 fois. Las réplicas se almacenan en nodos completamente diferentes.
- Hadoop Streaming actúa como un puente entre su código Python y, donc, el HDFS basado en Java, y le permite acceder sin problemas a los clústeres de Hadoop y ejecutar tareas de CarteRéduireMapReduce est un modèle de programmation conçu pour traiter et générer efficacement de grands ensembles de données. Propulsé par Google, Cette approche décompose le travail en tâches plus petites, qui sont répartis entre plusieurs nœuds d’un cluster. Chaque nœud traite sa partie, puis les résultats sont combinés. Cette méthode vous permet de faire évoluer les applications et de gérer d’énormes volumes d’informations, fondamental dans le monde du Big Data.....
- HDFS proporciona permisos y autenticación de archivos.
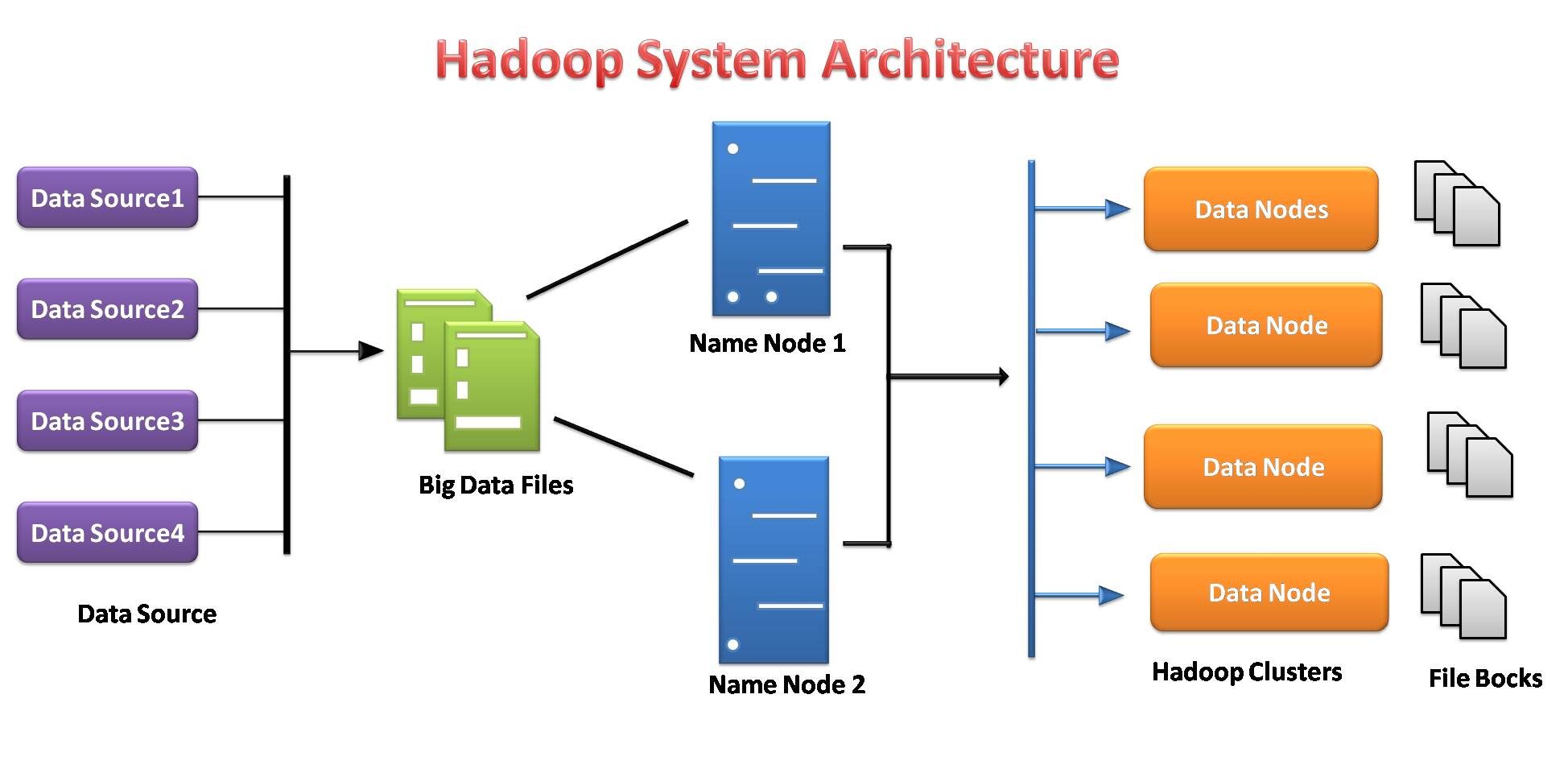
Source de l'image: por mi
Instalación de Hadoop en Google Colab
Hadoop es un marco de procesamiento de datos basado en programación Java. Instalemos la configuración de Hadoop paso a paso en Google Colab. Il y a deux manières, la primera es que tenemos que instalar java en nuestras máquinas y la segunda es que instalamos java en google colab, por lo que no es necesario instalar java en nuestras máquinas. Como usamos Google colab, elegimos la segunda forma de instalar Hadoop:
# Install java !apt-get install openjdk-8-jdk-headless -qq > /dev/null
#create java home variable import os os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64" os.environ["SPARK_HOME"] = "/content/spark-3.0.0-bin-hadoop3.2"
Paso 1: instalar Hadoop
#download hadoop !wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
#we’ll use the tar command with the -x flag to extract, -z to uncompress, #-v for verbose output, and -f to specify that we’re extracting from a file !tar -xzvf hadoop-3.3.0.tar.gz
#copying the hadoop file to user/local !cp -r hadoop-3.3.0/ /usr/local/
Paso 2: configurar la variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... de inicio de Java
#finding the default Java path !readlink -f /usr/bin/java | sed "s:bin/java::"
Paso 3: Ejecuta Hadoop
#Running Hadoop !/usr/local/hadoop-3.3.0/bin/hadoop
!mkdir ~/input
!cp /usr/local/hadoop-3.3.0/etc/hadoop/*.xml ~/input
!/usr/local/hadoop-3.3.0/bin/hadoop jar /usr/local/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep ~/input ~/grep_example 'allowed[.]*'
À présent, Google Colab está listo para implementar HDFS.
Petite carte
MapReduce es un modelo de programación que se asocia con la implementación del procesamiento y la generación de grandes conjuntos de datos con la ayuda de reglas algorítmicas distribuidas en paralelo en un clúster.
Un programa MapReduce consiste en un procedimiento de mapa, que realiza filtrado y clasificación, y una técnica de reducción, que realiza una operación de esquema.
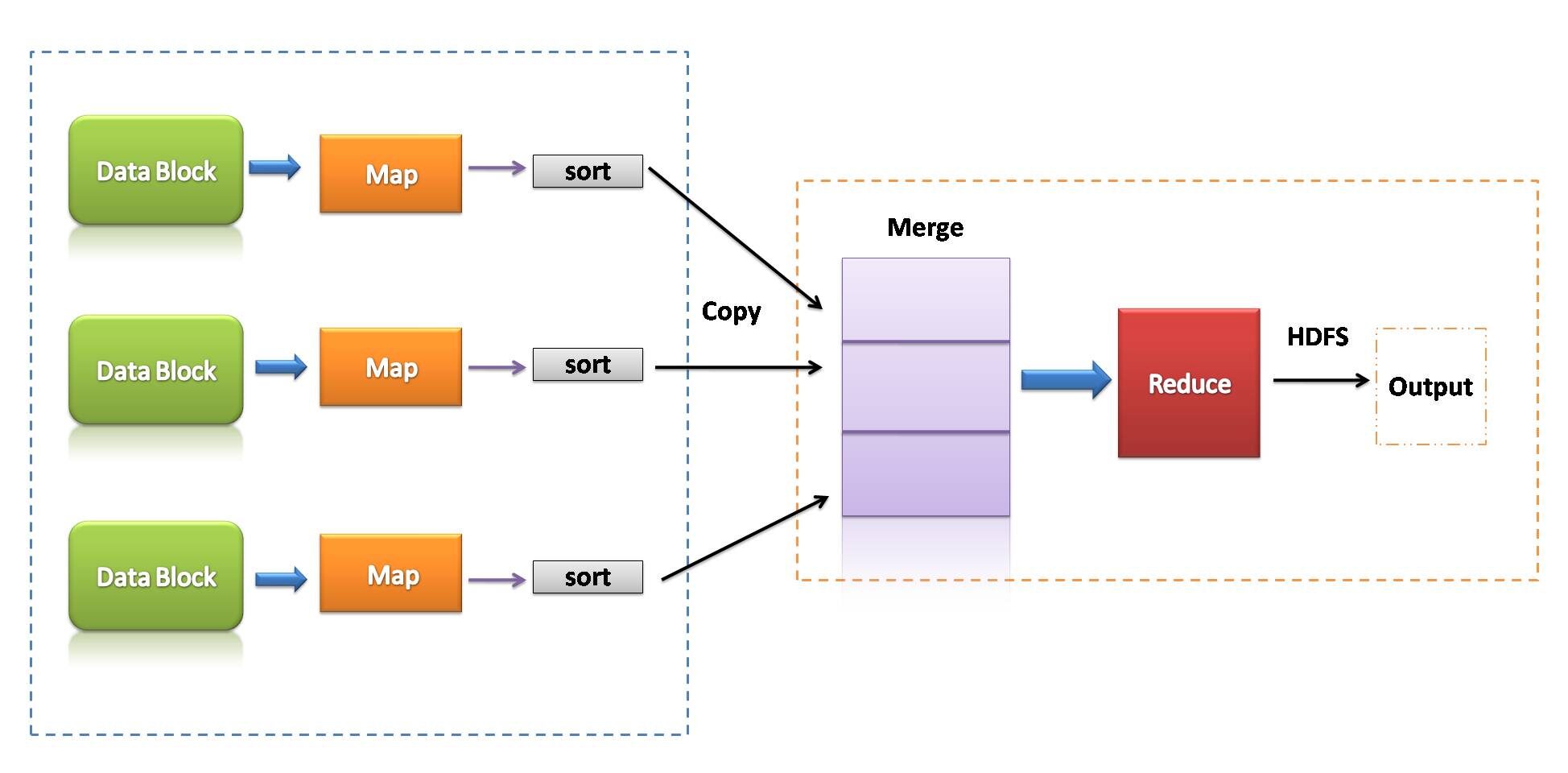
Source de l'image: por mi
- MapReduce podría ser un marco de procesamiento de datos para procesar datos en el clúster.
- Dos fases consecutivas: mapear y reducir.
- Cada tarea de mapa opera en partes separadas de datos.
- Después del mapa, el reductor trabaja con los datos generados por el asignador en los nodos de datos distribuidos.
- MapReduce usó E / S de disco para realizar operaciones con datos.
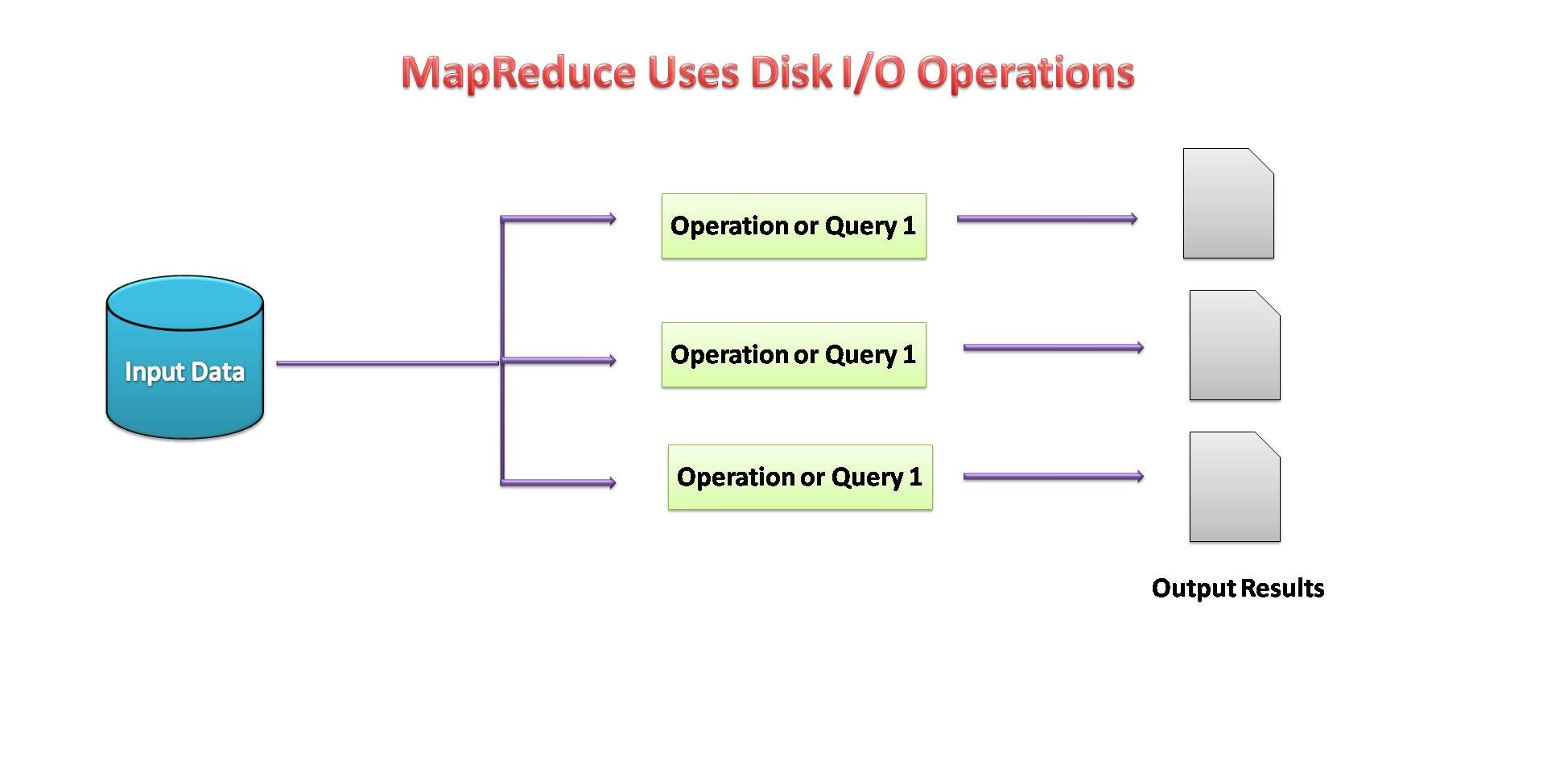
Source de l'image: por mi
Apache SparkApache Spark es un motor de procesamiento de datos de código abierto que permite el análisis de grandes volúmenes de información de manera rápida y eficiente. Su diseño se basa en la memoria, lo que optimiza el rendimiento en comparación con otras herramientas de procesamiento por lotes. Spark es ampliamente utilizado en aplicaciones de big data, machine learning y análisis en tiempo real, gracias a su facilidad de uso y...
Apache Spark es un motor de análisis de datos de código abierto para el procesamiento a gran escala de datos estructurados o no estructurados. Para trabajar con Python, incluidas las funcionalidades de Spark, la comunidad de Apache Spark había lanzado una herramienta llamada PySpark.
La API Spark Python (PySpark) revela el modelo de programación Spark a Python. Usando PySpark, podemos trabajar con RDD en el lenguaje de programación Python. Es atribuible a una biblioteca conocida como Py4j que pueden alcanzar esto.
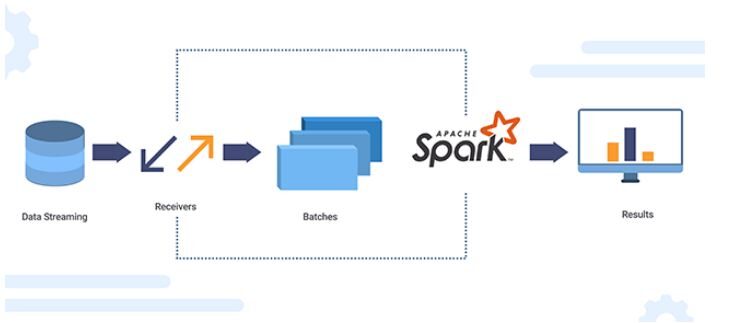
Source de l'image: XanonStack
Conjuntos de datos distribuidos resistentes (RDD)
Los conceptos sobre conjuntos de datos distribuidos resilientes (RDD) fils:
- El enfoque principal de la programación Spark es RDD.
- Spark es extremadamente tolerante a fallas. Tiene colecciones de objetos distribuidos en un clúster que pueden operar en paralelo.
- Al usar Spark, se puede recuperar automáticamente de una falla de la máquina.
- Podemos crear un RDD copiando los elementos de una colección existente o haciendo referencia a un conjunto de datos almacenado externamente.
- Hay dos tipos de operaciones que realizan los RDD: transformaciones y acciones.
- La operación de transformación utiliza un conjunto de datos existente para crear uno nuevo. Exemple: mapear, filtre, unir.
- Las acciones realizadas en el conjunto de datos y devuelven el valor al programa del controlador. Exemple: réduire, raconter, rassembler, sauvegarder.
Si la disponibilidad de memoria parece insuficiente, los datos se escriben en un disco como MapReduce.
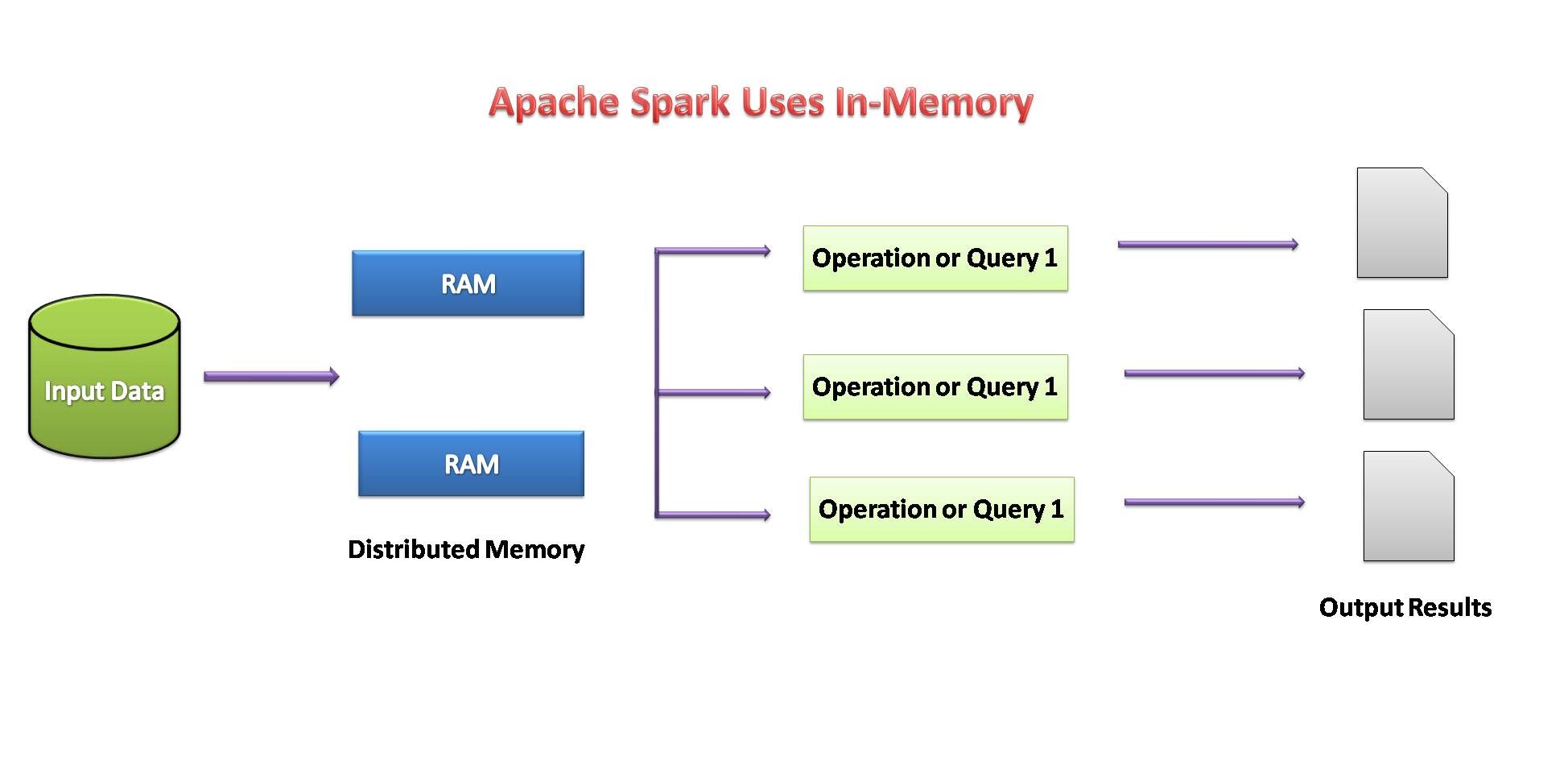
Source de l'image: por mi
Instalación de Spark en Google colab:
Spark es un marco de procesamiento de datos eficiente. podemos instalarlo fácilmente en el colab de Google.
# Install java !apt-get install openjdk-8-jdk-headless -qq > /dev/null
#Install spark (change the version number if needed) !wget -q https://archive.apache.org/dist/spark/spark-3.0.0/spark-3.0.0-bin-hadoop3.2.tgz
#Unzip the spark file to the current folder !tar xf spark-3.0.0-bin-hadoop3.2.tgz
#Set your spark folder to your system path environment. importer le système d'exploitation os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64" os.environ["SPARK_HOME"] = "/content/spark-3.0.0-bin-hadoop3.2"
#Install findspark using pip !pip install -q findspark
#Spark for Python (pyspark) !pip installer pyspark
#importing pyspark
import pyspark
#importing sparksessio
from pyspark.sql import SparkSession
#creating a sparksession object and providing appName
spark=SparkSession.builder.appName("local[*]").obtenirOuCréer()
#printing the version of spark print("Apache Spark version: ", spark.version)

À présent, Google Colab está listo para implementar Spark en Python.
Ventajas de Apache Spark:
- Spark es de 10 une 100 veces más rápido que Hadoop MapReduce cuando se habla de procesamiento de datos.
- Tiene sImplemente un marco de procesamiento de datos y API interactivas para Python que ayuden a acelerar el desarrollo de aplicaciones.
- En outre, es más eficiente ya que cuenta con múltiples herramientas para operaciones analíticas complejas.
- Se puede integrar fácilmente con la infraestructura de Hadoop existente.
conclusion:
Dans ce blog, estudiamos cómo Python puede convertirse también en una herramienta buena y eficiente para el procesamiento de Big Data. Podemos integrar todas las herramientas de Big Data con Python, lo que hace que el procesamiento de datos sea más fácil y rápido. Python se ha convertido en una opción adecuada no solo para la ciencia de datos sino también para el procesamiento de Big Data.
Merci pour la lecture. S'il vous plaît laissez-moi savoir s'il y a des commentaires ou des commentaires.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





