Cet article a été publié dans le cadre de la Blogathon sur la science des données.
Vue d'ensemble
introduction
Apache SparkApache Spark es un motor de procesamiento de datos de código abierto que permite el análisis de grandes volúmenes de información de manera rápida y eficiente. Su diseño se basa en la memoria, lo que optimiza el rendimiento en comparación con otras herramientas de procesamiento por lotes. Spark es ampliamente utilizado en aplicaciones de big data, machine learning y análisis en tiempo real, gracias a su facilidad de uso y... es un marco de procesamiento de datos que puede realizar rápidamente tareas de procesamiento en conjuntos de datos muy grandes y además puede repartir tareas de procesamiento de datos en múltiples computadoras, soit seul, soit en conjonction avec d’autres outils informatiques distribués. Il s’agit d’un moteur d’analyse unifié ultra-rapide pour le Big Data et l’apprentissage automatique.
Pour prendre en charge Python avec Spark, La communauté Apache Spark a publié un outil, PySpark. Avec Pyspark, vous pouvez travailler avec RDD dans le langage de programmation python.
Les composants Spark sont:
- Noyau d'étincelle
- Spark SQL
- Diffusion Spark
- Étincelle MLlib
- GraphX
- Étincelle R
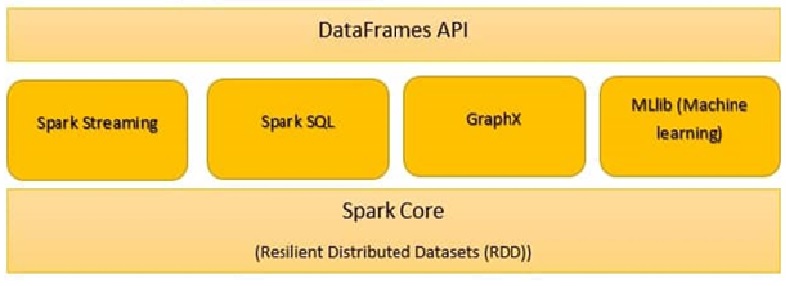
Noyau d'étincelle
Toutes les fonctionnalités fournies par Apache Spark sont axées sur le haut de Spark Core. Gérer toutes les fonctionnalités E / Essentiel S. Utilisé pour la répartition des tâches et la récupération des pannes. Spark Core est intégré à une collection spéciale appelée RDD (jeu de données distribué résilient). RDD fait partie des abstractions de Spark. Spark RDD maneja la partición de datos en todos los nodos de un grappeUn cluster est un ensemble d’entreprises et d’organisations interconnectées qui opèrent dans le même secteur ou la même zone géographique, et qui collaborent pour améliorer leur compétitivité. Ces regroupements permettent le partage des ressources, Connaissances et technologies, favoriser l’innovation et la croissance économique. Les grappes peuvent couvrir une variété d’industries, De la technologie à l’agriculture, et sont fondamentaux pour le développement régional et la création d’emplois..... Les conserve dans le pool de mémoire du cluster en tant qu’unité unique. Deux opérations sont effectuées dans RDD:
Transformation: c’est une fonction qui produit de nouveaux rdds à partir de rdds existants.
action: En transformation, Les RDD sont créés les uns par rapport aux autres. Mais quand nous voulons travailler avec l’ensemble de données réel, ensuite, à ce moment-là, nous utilisons Action.
Spark SQL
Le composant Spark SQL est un framework distribué pour le traitement des données structurées. Spark SQL fonctionne pour entrer des informations structurées et semi-structurées. Il permet également des applications analytiques puissantes et interactives dans les données historiques et de transmission. DataFrames et SQL fournissent un moyen commun d’entrer une plage de sources de données. Sa principale caractéristique est d’être un optimiseur basé sur les coûts et la tolérance aux échecs de requête moyens..
Diffusion Spark
Il s’agit d’un module complémentaire à l’API principale de Spark qui permet un traitement de flux évolutif, transmissions de données en direct hautes performances et tolérantes aux pannes. Diffusion Spark, regroupe les données actives en petits lots. Il le livre ensuite au système par lots pour traitement. Fournit également des fonctionnalités de tolérance aux pannes.
Spark GraphX:
GraphX dans Spark est une API pour les graphiques et l’exécution de graphiques parallèles. Il s’agit d’un moteur d’analyse de graphes réseau et d’un entrepôt de données. Dans les graphiques, il est également possible de regrouper, classer par catégories, Scooch, rechercher et trouver des itinéraires.
SparkR:
SparkR fournit une implémentation de cadre de données distribuée. Prend en charge les opérations en tant que sélection, filtré, agrégation, mais dans de grands ensembles de données.
Étincelle MLlib:
Spark MLlib est utilisé pour effectuer l’apprentissage automatique dans Apache Spark. MLlib se compose d’algorithmes et d’utilitaires populaires. MLlib on Spark est une bibliothèque d’apprentissage automatique évolutive qui analyse à la fois des algorithmes de haute qualité et à grande vitesse. Algorithmes d’apprentissage automatique en tant que régression, classification, regroupementLe "regroupement" Il s’agit d’un concept qui fait référence à l’organisation d’éléments ou d’individus en groupes ayant des caractéristiques ou des objectifs communs. Ce procédé est utilisé dans diverses disciplines, y compris la psychologie, Éducation et biologie, faciliter l’analyse et la compréhension de comportements ou de phénomènes. Dans le domaine de l’éducation, par exemple, Le regroupement peut améliorer l’interaction et l’apprentissage entre les élèves en encourageant le travail.., exploration de modèles et filtrage collaboratif. Les primitives d’apprentissage automatique de niveau inférieur, en tant qu’algorithme générique d’optimisation de la descente de gradient, ils sont également présents dans MLlib.
Spark.ml est la principale API d’apprentissage automatique pour Spark. La bibliothèque Spark.ml offre une API de niveau supérieur construite sur DataFrames pour créer des pipelines ML.
Les outils Spark MLlib sont fournis ci-dessous:
- Algorithmes ML
- Caractérisation
- Pipelines
- Persistance
- Utilitaires
-
Algorithmes ML
Les algorithmes ML forment le cœur de MLlib. Ceux-ci incluent des algorithmes d’apprentissage courants tels que la classification., régression, regroupement et filtrage collaboratifs.
MLlib standardise les API pour aider à combiner plusieurs algorithmes en un seul pipeline ou flux de travail. Les concepts clés sont les pipelines Api, où le concept de pipeline s’inspire du projet scikit-learn.
Transformateur:
Un transformateur est un algorithme qui peut transformer un DataFrame en un autre DataFrame. Techniquement, un transformateur implémente une méthode de transformation (), qui convertit un DataFrame en un autre, généralement en ajoutant une ou plusieurs colonnes. Par exemple:
Un transformateur de fonctionnalités peut prendre un DataFrame, lire une colonne (par exemple, texte), l’affecter à une nouvelle colonne (par exemple, vecteurs d’entités) et générez un nouveau DataFrame avec la colonne affectée attachée.
Un modèle d’apprentissage peut prendre un DataFrame, lire la colonne contenant les vecteurs d’entité, prédire la balise pour chaque vecteur d’entité et générer un nouveau DataFrame avec des balises prédites ajoutées sous forme de colonne.
EstimateurLe "Estimateur" est un outil statistique utilisé pour déduire les caractéristiques d’une population à partir d’un échantillon. Il s’appuie sur des méthodes mathématiques pour fournir des estimations précises et fiables. Il existe différents types d’estimateurs, tels que l’impartialité et la cohérence, qui sont choisis en fonction du contexte et de l’objectif de l’étude. Son utilisation correcte est essentielle dans la recherche scientifique, enquêtes et analyses de données....:
Un estimateur est un algorithme qui peut être monté sur un DataFrame pour produire un transformateur. Techniquement, un estimateur met en œuvre une méthode d’ajustement (), qui accepte un DataFrame et produit un Modèle, qui est un transformateur. Par exemple, un algorithme d’apprentissage tel que LogisticRegression est un estimateur, et appel fit () entraîne un LogisticRegressionModel, qui est un modèle et, pour cela, un transformateur.
Transformer.transform () et Estimator.fit () sont apatrides. Dans le futur, Les algorithmes avec état peuvent être compatibles avec d’autres concepts.
Chaque instance d’un transformateur ou d’un estimateur a un ID unique, que es útil para especificar paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... (décrit ci-dessous).
-
Caractérisation
La caractérisation comprend l’extraction, transformation, diminution de la dimensionnalité et de la sélection des caractéristiques.
- L’extraction de fonctionnalités consiste à extraire des fonctionnalités à partir de données brutes.
- La transformation des fonctionnalités inclut la mise à l’échelle, renouveler ou modifier des fonctionnalités
- La sélection des fonctionnalités implique le choix d’un sous-ensemble de fonctionnalités indispensables parmi un grand ensemble de fonctionnalités.
-
Tuyaux:
Un pipeline enchaîne plusieurs transformateurs et estimateurs pour spécifier un flux de travail AA. Il fournit également des outils pour construire, parcourir et régler les pipelines ML.
En apprentissage automatique, il est courant d’exécuter une séquence d’algorithmes pour traiter et apprendre des données. MLlib representa un flujo de trabajo como PipelinePipeline es un término que se utiliza en diversos contextos, principalmente en tecnología y gestión de proyectos. Se refiere a un conjunto de procesos o etapas que permiten el flujo continuo de trabajo desde la concepción de una idea hasta su implementación final. En el ámbito del desarrollo de software, par exemple, un pipeline puede incluir la programación, pruebas y despliegue, garantizando así una mayor eficiencia y calidad en los..., qui est une séquence d’étapes de pipeline (Transformateurs et estimateurs) à exécuter dans un ordre spécifique. Nous utiliserons ce flux de travail simple comme exemple d’exécution dans cette section.
Exemple: l’exemple de pipeline illustré ci-dessous effectue le prétraitement des données dans un ordre spécifique comme suit:
1. Aplicar el método String Indexer para hallar el indiceLe "Indice" C’est un outil fondamental dans les livres et les documents, qui vous permet de localiser rapidement les informations souhaitées. Généralement, Il est présenté au début d’une œuvre et organise les contenus de manière hiérarchique, y compris les chapitres et les sections. Sa préparation correcte facilite la navigation et améliore la compréhension du matériau, ce qui en fait une ressource incontournable tant pour les étudiants que pour les professionnels dans divers domaines.... de las columnas categóricas
2. Appliquer le codage OneHot pour les colonnes catégorielles
3. Appliquer l’indexeur de chaîne pour la colonne « étiqueter » de variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... Sortie
4. VectorAssembler s’applique à la fois aux colonnes catégorielles et aux colonnes numériques. VectorAssembler est un transformateur qui combine une liste donnée de colonnes en une seule colonne vectorielle.
Le flux de travail du pipeline exécutera la modélisation des données dans l’ordre spécifique ci-dessus.
à partir de pyspark.ml.feature importer OneHotEncoderEstimator, StringIndexer, VectorAssembler
categoricalColumns = [« emploi », « conjugal », « éducation », 'par défaut', « logement », « prêt »] étapes = [] pour categoricalCol dans categoricalColumns: stringIndexer = StringIndexer(inputCol = categoricalCol, outputCol = categoricalCol + 'Indexeur') encoder = OneHotEncoderEstimator(inputCols=[stringIndexer.getOutputCol()], outputCols=[catégoriqueCol + "Vec"]) étapes += [stringIndexer, encodeur] label_stringIdx = StringIndexer(inputCol="dépôt", outputCol="étiqueter") étapes += [label_stringIdx] numericColumns = ['âge', « équilibre », « durée »] assembleurInputs = [c + "Vec" pour c dans categoricalColumns] + numericColumns Vassembler = VectorAssembler(inputCols = assembleurInputs, outputCol="caractéristiques") étapes += [Vassembler]from pyspark.ml import Pipeline pipeline = Pipeline(étapes = étapes) pipelineModel = pipeline.fit(df) df = pipelineModel.transform(df) selectedCols = ['étiqueter', 'caractéristiques'] + cols df = df.select(sélectionnéCols)
Trame de données
Los marcos de datos proporcionan una API más fácil de utilizar que los RDD. L’API basée sur DataFrame pour MLlib fournit une API cohérente dans tous les algorithmes ML et dans plusieurs langues. Les infrastructures de données facilitent les pipelines d’apprentissage automatique pratiques, en particulier les transformations de fonctionnalités.
from pyspark.sql import SparkSession spark = SparkSession.builder.appName('mlearnsample').obtenirOuCréer() df = spark.read.csv(« loan_bank.csv », en-tête = Vrai, inferSchema = Vrai) df.printSchema() -
Persistance:
La persistance permet d’enregistrer et de charger des algorithmes, modèles et pipelines. Cela permet de réduire le temps et les efforts, puisque le modèle est persistant, peut être chargé / réutiliser à tout moment si nécessaire.
from pyspark.ml.classification import LogisticRegression lr = LogisticRegression(caractéristiquesCol="caractéristiques", labelCol="étiqueter") lrModel = lr.fit(former)à partir de pyspark.ml.evaluation importer BinaryClassificationEvaluator
évaluateur = BinaryClassificationEvaluator ()
imprimer (‘Test Area Under ROC’, évaluateur.évaluer (prédictions))
prédictions = lrModel.transform(test) prédictions.select('âge', 'étiqueter', 'rawPrediction', 'prédiction').spectacle() -
Utilitaires:
Utilitaires pour l’algèbre linéaire, statistiques et traitement des données. Exemple: mllib.linalg sont les utilitaires MLlib pour l’algèbre linéaire.
Matériel de référence:
https://spark.apache.org/docs/latest/ml-guide.html
Remarques finales
Spark MLlib est nécessaire s’il s’agit de Big Data et de machine learning. Dans ce billet, a appris les détails de Spark MLlib, cadres de données et pipelines. Dans le futur article, nous travaillerons sur du code pratique pour implémenter des pipelines et construire des modèles de données à l’aide de MLlib.





