Cet article a été publié dans le cadre du Blogathon sur la science des données
Vue d'ensemble
- Apprendre le concept de base de l'exploration de données
- Comprendre les applications de l'exploration de données
Conditions préalables
- Compréhension de base de Python
- Connaissance de base de la base de données
Bienvenue Les gars!
Ici, je vais vous donner une brève compréhension des bases du Data Mining. Sabemos que en todas partes hay datos en varios formatos que se almacenarán en una base de donnéesUne base de données est un ensemble organisé d’informations qui vous permet de stocker, Gérez et récupérez efficacement les données. Utilisé dans diverses applications, Des systèmes d’entreprise aux plateformes en ligne, Les bases de données peuvent être relationnelles ou non relationnelles. Une bonne conception est essentielle pour optimiser les performances et garantir l’intégrité de l’information, facilitant ainsi la prise de décision éclairée dans différents contextes..... Selon l'échelle de données, nous pouvons choisir une base de données appropriée. Ensuite, il existe des bases de données populaires que nous connaissons, en tant que PostgreSQL, NoSQL, MongoDB, Microsoft SQL Server et bien d'autres.
Dans cet article, vous vous ferez une idée du data mining.
Alors continuons …
Qu'est-ce que l'exploration de données?
« Traitement de l'information », qui extrait les données. En mots simples, se définit comme trouver des informations cachées (information) de la base de données, extraire des modèles de données.
Il existe différents algorithmes pour différentes tâches. La fonction de ces algorithmes est d'ajuster le modèle. Ces algorithmes identifient les caractéristiques des données. Il y a 2 types de modèles.
1) Modèle prédictif
2) Modèle descriptif
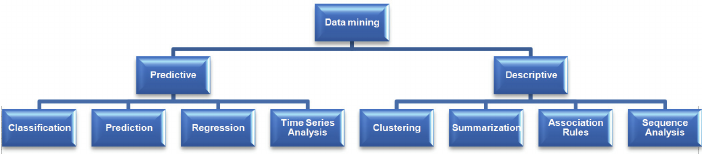
Tâches d'exploration de données de base
Dans cette section, nous allons voir certaines des fonctions / tâches minières.
1) Classification
Este término viene bajo enseignement superviséL’apprentissage supervisé est une approche d’apprentissage automatique dans laquelle un modèle est formé à l’aide d’un ensemble de données étiquetées. Chaque entrée du jeu de données est associée à une sortie connue, permettre au modèle d’apprendre à prédire les résultats pour de nouvelles entrées. Cette méthode est largement utilisée dans des applications telles que la classification d’images, Reconnaissance vocale et prédiction de tendances, soulignant son importance dans.... Les algorithmes de classification nécessitent que les classes soient définies en fonction de variables. Les caractéristiques des données définissent à quelle classe elles appartiennent. La reconnaissance des formes est l'un des types de problèmes de classification dans lesquels l'entrée (Modèle) est classé en différentes classes en fonction de leur similarité de classe définie.
2) Prédiction
Dans la vie réelle, on voit souvent les choses prédire / valeurs futures / ou autrement basé sur des données passées et des données présentes. La prédiction est aussi un type de tâche de classification. Selon le type de candidature, par exemple, prédire les crues dont les variables dépendantes sont le niveau d'eau de la rivière, son humidité, échelle de pluie, etc. sont les attributs.
3) Régression
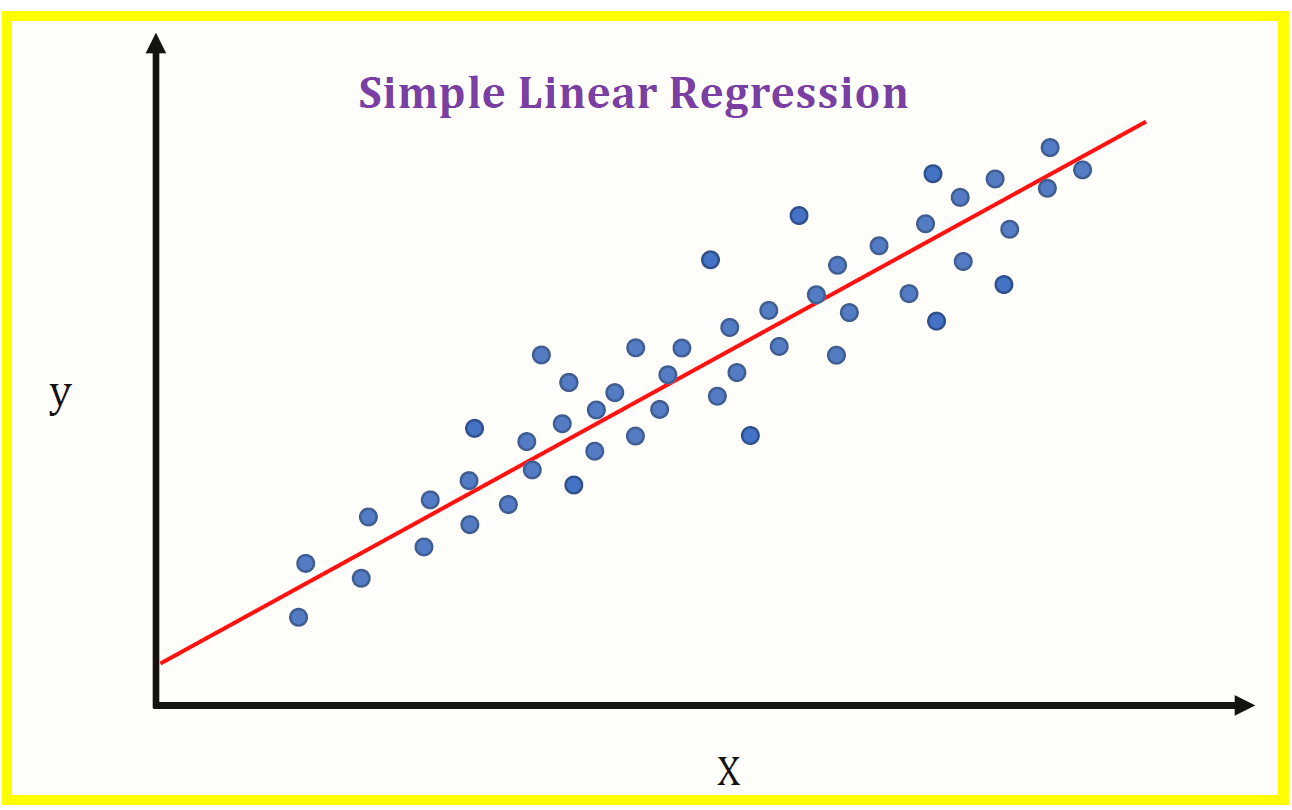
La régression est une technique statistique utilisée pour déterminer la relation entre les variables (X) et les variables dépendantes (Oui). Il existe peu de types de régression comme linéaire, Logistique, etc. La régression linéaire est utilisée sur des valeurs continues (0,1,1,5,… .et ainsi de suite) et la régression logistique est utilisée lorsqu'il y a une possibilité de seulement deux événements au fur et à mesure qu'ils se produisent / échec, vrai / faux, Oui / non, etc.
4) Analyse des séries chronologiques
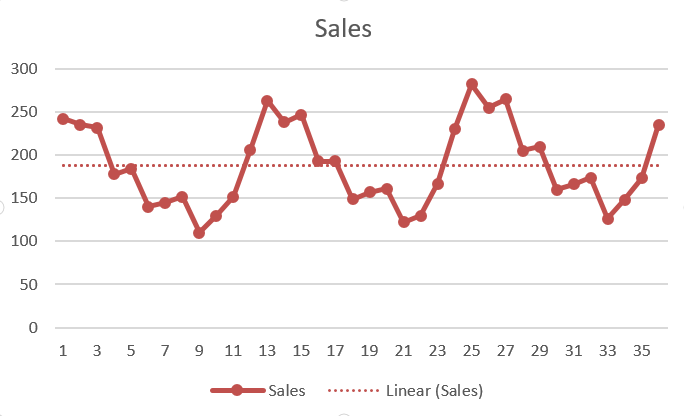
Dans l'analyse des séries chronologiques, ongle variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... cambia su valor según el tiempo. Cela signifie que l'analyse passe par des modèles d'identification des données sur une période de temps. Peut être une variation saisonnière, variation irrégulière, tendance séculaire et fluctuation cyclique. Par exemple, pluie annuelle, prix du sac, etc.
5) Regroupement
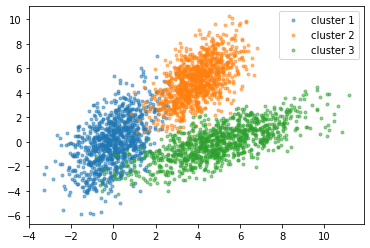
Le regroupement est le même que le classement, c'est-à-dire, regrouper les données. Le clustering est inclus dans l'apprentissage automatique non supervisé. Il s'agit d'un processus de division des données en groupes en fonction de types de données similaires.
6) résumé
Le résumé n'est rien de plus qu'une caractérisation ou une généralisation. Récupérer des informations significatives à partir des données. Il offre également un résumé des variables numériques en tant que moyenne, mode, médianLa médiane est une mesure statistique qui représente la valeur centrale d’un ensemble de données ordonnées. Pour le calculer, Les données sont organisées de la plus basse à la plus élevée et le numéro au milieu est identifié. S’il y a un nombre pair d’observations, La moyenne des deux valeurs fondamentales est calculée. Cet indicateur est particulièrement utile dans les distributions asymétriques, puisqu’il n’est pas affecté par les valeurs extrêmes...., etc.
7) Règles d'association
C'est la tâche principale du Data Mining. Aide à trouver des modèles appropriés et des connaissances significatives à partir de la base de données. La règle d'association est un modèle qui extrait des types d'associations à partir de données. Par exemple, Analyse du panier de marché où les règles d'association sont appliquées à la base de données pour savoir quels articles le client achète ensemble.
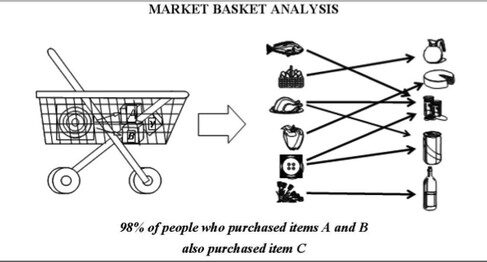
8) Découverte de séquence
Aussi appelée analyse séquentielle. Il est utilisé pour découvrir ou trouver le modèle séquentiel dans les données.
Le modèle séquentiel signifie le modèle qui est purement basé sur une séquence de temps. Ces modèles sont similaires aux règles d'association trouvées dans la base de données ou les événements sont liés mais leur relation est basée uniquement sur le « Temps ».
Jusque là, nous avons vu toutes les fonctions ou tâches de base du Data Mining. Passons à en savoir plus sur l'exploration de données …
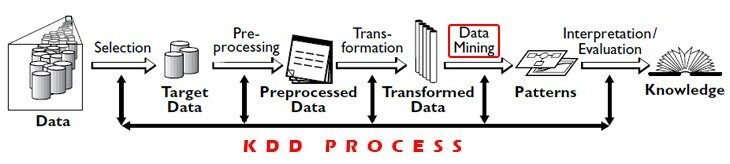
Exploration de données VS KDD (découverte de connaissances dans la base de données)
Traitement de l'information: Processus d'utilisation d'algorithmes pour extraire des informations et des modèles significatifs dérivés du processus KDD. C'est une étape impliquée dans KDD.
KDD: Il s'agit d'un processus important d'identification de modèles et d'informations significatives dans les données.. L'entrée donnée à ce processus sont les données et la sortie fournit des informations utiles à partir des données.
Le processus KDD consiste à 5 Pas:
1) Sélection: Besoin d'obtenir des données de diverses sources de données, base de données.
2) Prétraitement: Ce processus de nettoyage des données en termes de mauvaises données, valeurs manquantes, données erronées.
3) Transformation: Les données provenant de diverses sources doivent être converties et encodées dans un format pour le prétraitement.
4) Exploration de données: Dans ce processus, des algorithmes sont appliqués aux données transformées pour obtenir la sortie ou les résultats souhaités.
5) Interprétation / évaluation: Vous devez faire des visualisations pour présenter les résultats de l'exploration de données qui sont très importants.
Applications d'exploration de données
1) Commerce électronique
Le e-commerce est une de ses applications dans la vraie vie. Les entreprises de commerce électronique sont comme Amazon, Flipkart, Myntra, etc. Ils utilisent des techniques d'exploration de données pour voir la fonctionnalité de chaque produit de telle sorte que "quel produit est le plus vu par le client aussi ce que l'autre a aimé".
2) vendre au détail
C'est une autre application d'exploration de données du marché de détail. Les détaillants trouvent le modèle de « fraîcheur, la fréquence, monétaire (en termes de monnaie) ». Les détaillants suivent les ventes et les transactions de produits.
3) Éducation
L'éducation est un domaine émergent et tendance aujourd'hui. Il s'agit de la découverte de connaissances à partir de données éducatives. L'objectif principal de cette application est d'étudier ou d'identifier le comportement de l'élève en termes d'apprentissage futur, étudier les effets, connaissances d'apprentissage avancées, etc. Ces techniques d'exploration de données sont utilisées par les institutions pour prendre des décisions précises et également prédire des résultats appropriés..
Outils d'exploration de données
– COUTEAUX
-WEKA
-ORANGE
Algorithmes d'exploration de données
- Regroupement des bas K
- Machines à vecteurs de soutien
- A priori
- KNN
- Bayes ingénieux
- PANIER et bien d'autres …
Ce sont des algorithmes.
* Maintenant, je vais vous donner des informations sur les bibliothèques requises ci-dessous.
– A priori:
d'apyori import apriori
– Regroupement des bas K:
from kneed import KneeLocator
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler– Machines à vecteurs de soutien:
de sklearn importer svm
-Naïf Bayes:
de sklearn.naive_bayes importer GaussianNB
-AUTO:
depuis sklearn.tree importer DecisionTreeRegressor
-KNN:
fromsklearn.neighborsimportKNeighborsClassifier
Voici donc quelques bibliothèques qui doivent être installées pendant l'exécution de l'algorithme.
conclusion
j'espère que vous avez aimé mon article. Si vous avez une requête, vous pouvez laisser des commentaires ci-dessous. Merci!
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





