Cet article fait référence à l'un des algorithmes de classification ML supervisés:Algorithme KNN (K voisins les plus proches). C'est l'un des algorithmes de classification les plus simples et les plus largement utilisés dans lequel un nouveau point de données est classé en fonction de la similitude dans le groupe spécifique de points de données voisins.. Cela donne un résultat compétitif.
La main d'oeuvre
Pour un point de données donné dans l'ensemble, les algorithmes trouvent les distances entre celui-ci et tous les autres K nombre de points de données dans l'ensemble de données près du point de départ et votes pour la catégorie qui a la fréquence la plus élevée. Généralement, Distance euclidienne está tomando como mesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... de distancia. Donc, le modèle final résultant n'est que les données étiquetées placées dans un espace. Cet algorithme est populairement connu par diverses applications telles que la génétique, prévision, etc. L'algorithme est meilleur lorsque plus de fonctionnalités sont présentes et affiche SVM dans ce cas.
KNN réduisant le surapprentissage est une donnée. D'un autre côté, il faut choisir la meilleure valeur pour K. Ensuite, Comment choisissons-nous K? Nous utilisons généralement la racine carrée du nombre d'échantillons dans l'ensemble de données comme valeur pour K. Une valeur optimale doit être trouvée car une valeur inférieure peut conduire à un surajustement et une valeur plus élevée peut nécessiter une grande complication de calcul dans la distance.. Donc, l'utilisation d'un tracé d'erreur peut aider. Une autre méthode est la méthode du coude. Peut préférer prendre racine, sinon vous pouvez aussi suivre la méthode du coude.
Plongeons-nous dans les différentes étapes K-NN pour classer un nouveau point de données
Paso 1: Sélectionnez la valeur de K voisins (disons k = 5)
Paso 2: Trouver le point de données K (5) le plus proche pour notre nouveau point de données basé sur la distance euclidienne (que nous discuterons plus tard)
Paso 3: Entre ces K points de données, compter les points de données dans chaque catégorie.
Paso 4: Attribuez le nouveau point de données à la catégorie qui a le plus de voisins du nouveau point de données
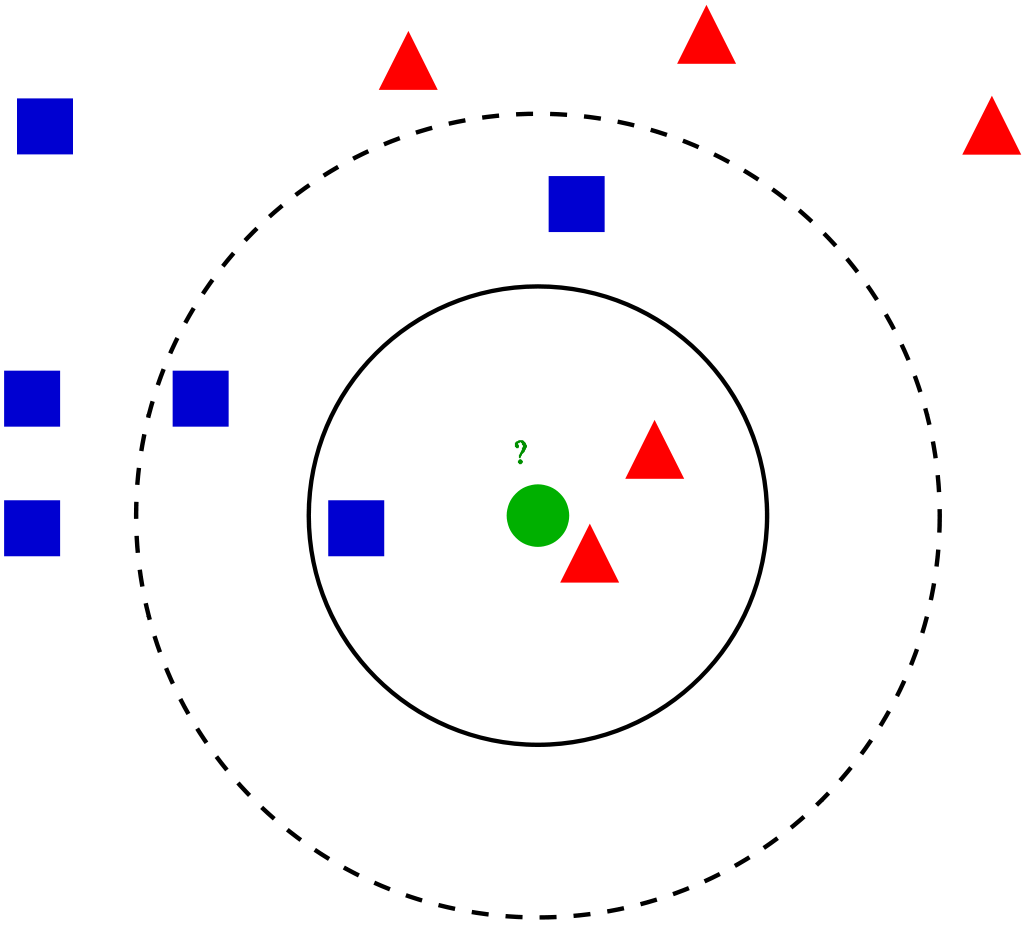
Exemple
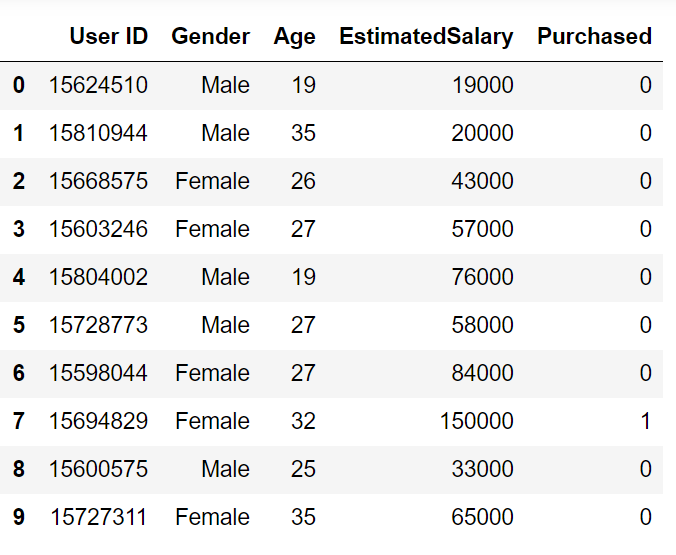
Passons en revue un exemple de problème pour avoir une intuition claire sur la classification K-Nearest Neighbour. Nous utilisons l'ensemble de données publicitaires sur les réseaux sociaux (Descargar). L'ensemble de données contient les détails des utilisateurs sur un site de réseau social pour savoir si un utilisateur achète un produit en cliquant sur l'annonce sur le site en fonction de son salaire, âge et sexe.
Commençons à programmer en important les bibliothèques essentielles
importer numpy en tant que np
importer matplotlib.pyplot en tant que plt
importer des pandas au format pd
importer sklearn
Importez l'ensemble de données et divisez-le en variables indépendantes et dépendantes
ensemble de données = pd.read_csv('Social_Network_Ads.csv')
X = jeu de données.iloc[:, [1, 2, 3]].valeurs
y = jeu de données.iloc[:, -1].valeurs
Puisque notre jeu de données contient des variables de caractères, nous devons l'encoder en utilisant LabelEncoder
de sklearn.preprocessing importer LabelEncoder
le = LabelEncoder()
X[:,0] = le.fit_transform(X[:,0])
Nous effectuons un test de train fractionné sur l'ensemble de données. Nous fournissons une taille d'essai de 0,20, ce qui signifie que notre échantillon d'entraînement contient 320 les ensembles d'apprentissage et l'échantillon de test contiennent 80 ensembles de test
de sklearn.model_selection importer train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Oui, taille_test = 0.20, état_aléatoire = 0)
Ensuite, nous allons effectuer une mise à l'échelle des caractéristiques de l'ensemble d'apprentissage et un test des variables indépendantes pour réduire la taille à des valeurs plus petites.
de sklearn.preprocessing importer StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
Nous devons maintenant créer et entraîner le modèle K Nearest Neighbor avec l'ensemble d'entraînement
de sklearn.neighbors importer KNeighborsClassifier
classificateur = KNeighborsClassifier(n_voisins = 5, métrique="minkowski", p = 2)
classificateur.fit(X_train, y_train)
Nous utilisons 3 paramètres dans la création de modèle. n_neighbors est défini sur 5, ce qui signifie qu'ils sont nécessaires 5 points de voisinage pour classer un point donné. La métrique de distance que nous utilisons est Minkowski, l'équation pour cela est donnée ci-dessous
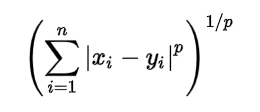
Selon l'équation, nous devons également sélectionner la valeur p.
p = 1, Distance de Manhattan
p = 2, Distance euclidienne
p = infini, Distance de Cheybchev
Dans notre problème, nous choisissons p comme 2 (vous pouvez également choisir la métrique comme « euclidien »)
Notre modèle est créé, maintenant nous devons prédire la sortie pour l'ensemble de test
y_pred = classifier.predict(X_test)
Comparaison de la valeur vraie et prédite:
et tester
déployer([0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1,
0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1,
0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1,
1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1], dtype=int64)
y_pred
déployer([0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1,
0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1,
0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1,
1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1], dtype=int64)
Nous pouvons évaluer notre modèle en utilisant la matrice de confusion et le score de précision en comparant les valeurs de test prédites et réelles
à partir de sklearn.metrics importer confusion_matrix,score_précision
cm = confusion_matrice(y_test, y_pred)
ac = précision_score(y_test,y_pred)
matrice de confusion –
[[64 4] [ 3 29]]
la précision est 0,95
# Importation des bibliothèques
importer numpy en tant que np
importer matplotlib.pyplot en tant que plt
importer des pandas au format pd
# Importation du jeu de données
ensemble de données = pd.read_csv('Social_Network_Ads.csv')
X = jeu de données.iloc[:, [2, 3]].valeurs
y = jeu de données.iloc[:, -1].valeurs
# Diviser l'ensemble de données en l'ensemble d'entraînement et l'ensemble de test
de sklearn.model_selection importer train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Oui, taille_test = 0.20, état_aléatoire = 0)
# Mise à l'échelle des fonctionnalités
de sklearn.preprocessing importer StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# Entraînement du modèle K-NN sur l'ensemble d'entraînement
de sklearn.neighbors importer KNeighborsClassifier
classificateur = KNeighborsClassifier(n_voisins = 5, métrique="minkowski", p = 2)
classificateur.fit(X_train, y_train)
# Prédire les résultats de l'ensemble de test
y_pred = classifier.predict(X_test)
# Faire la matrice de confusion
à partir de sklearn.metrics importer confusion_matrix, score_précision
cm = confusion_matrice(y_test, y_pred)
ac = précision_score(y_test, y_pred)
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





