Vue d'ensemble
- Les bases de données relationnelles sont omniprésentes, mais que se passe-t-il lorsque vous devez faire évoluer votre infrastructure?
- Nous discuterons du rôle que Spark SQL joue dans cette situation et comprendrons pourquoi c'est un outil si utile pour l'apprentissage.
- Ce tutoriel montre également comment Spark SQL fonctionne à l'aide d'une étude de cas Python
introduction
Presque toutes les organisations utilisent des bases de données relationnelles pour diverses tâches, de la gestion et du suivi d'une grande quantité d'informations à l'organisation et au traitement des transactions. C'est l'un des premiers concepts qu'on nous a appris à l'école de programmation.
Et soyons reconnaissants pour cela, car il s'agit d'un équipement crucial dans l'ensemble des compétences d'un data scientist !! Vous ne pouvez pas vous en sortir sans savoir comment fonctionnent les bases de données. C'est un aspect clé de tout apprentissage automatique projet.
Langage de requêtes structurées (SQL) est facilement le langage le plus populaire en matière de bases de données. Contrairement aux autres langages de programmation, est facile à apprendre et nous aide à démarrer notre processus d'extraction de données. Pour la plupart des emplois en science des données, La maîtrise de SQL est plus élevée que la plupart des autres langages de programmation.

Mais il y a un défi majeur avec SQL: aura du mal à le faire fonctionner lorsqu'il traitera d'énormes ensembles de données. C'est là que Spark SQL prend le devant et comble l'écart.. J'en parlerai davantage dans la section suivante..
Ce didacticiel pratique vous présentera le monde de Spark SQL, Comment ça marche, quelles sont les différentes fonctionnalités qu'il offre et comment pouvez-vous l'implémenter en utilisant python. Nous parlerons également d'un concept important que vous rencontrerez souvent dans les interviews.: l'optimiseur de catalyseur.
Commençons!
Noter: Si vous êtes complètement nouveau dans le monde SQL, Je recommande fortement le cours suivant:
Table des matières
- Défis liés à la mise à l'échelle des bases de données relationnelles
- Présentation de Spark SQL
- Fonctionnalités Spark SQL
- Comment Spark SQL exécute une requête?
- Qu'est-ce qu'un optimiseur de catalyseur?
- Exécuter des commandes SQL avec Spark
- Utilisation d'Apache Spark à grande échelle
Défis liés à la mise à l'échelle des bases de données relationnelles
La question est pourquoi devrais-je apprendre Spark SQL? J'ai mentionné cela brièvement avant, mais regardons ça un peu plus en détail maintenant.
Bases de données relationnelles pour un grand projet (apprentissage automatique) contiennent des centaines voire des milliers de tables et la plupart des caractéristiques d'une table sont mappées à d'autres caractéristiques d'autres tables. Ces bases de données sont conçues pour fonctionner uniquement sur une seule machine afin de maintenir les règles de mappage des tables et d'éviter les problèmes de calcul distribué..
Cela devient souvent un problème pour les organisations lorsqu'elles souhaitent évoluer avec cette conception.. Cela nécessiterait un matériel plus complexe et plus coûteux avec une capacité de traitement et de stockage nettement supérieure. Comme vous pouvez l'imaginer, La mise à niveau d'un matériel plus simple vers un matériel plus complexe peut être un grand défi.
Une organisation peut avoir besoin de mettre son site Web hors ligne pendant un certain temps pour apporter les modifications nécessaires. Au cours de cette période, perdraient des affaires avec de nouveaux clients qu'ils auraient potentiellement pu acquérir.
En outre, à mesure que le volume de données augmente, les organisations ont du mal à gérer cette énorme quantité de données à l'aide de bases de données relationnelles traditionnelles. C'est là que Spark SQL entre en scène..
Présentation de Spark SQL
““
~
Les frameworks Hadoop et MapReduce existent depuis longtemps dans l'analyse de Big Data. Mais ces trames nécessitent beaucoup d'opérations de lecture et d'écriture sur un disque dur, ce qui les rend très coûteux en temps et en vitesse.
Apache Spark est le framework de traitement de données le plus efficace dans les entreprises aujourd'hui. Il est vrai que le coût de Spark est élevé car il nécessite beaucoup de RAM pour le calcul en mémoire, mais c'est toujours un favori parmi les data scientists et les ingénieurs big data.
Dans l'écosystème Spark, nous avons les composants suivants:
- MLlib: Il s'agit de la bibliothèque d'apprentissage automatique évolutive de Spark qui fournit des algorithmes de haute qualité pour la régression, regroupement, classification, etc. Vous pouvez commencer à créer des pipelines d'apprentissage automatique à l'aide de la MLlib de Spark en utilisant cet article: Comment créer des pipelines d'apprentissage automatique à l'aide de PySpark?
- Diffusion Spark: Nous générons actuellement des données à un rythme et à une échelle sans précédent. Comment nous assurons-nous que notre pipeline d'apprentissage automatique continue de produire des résultats dès que les données sont générées et collectées? Apprenez à utiliser un modèle d'apprentissage automatique pour faire des prédictions sur la transmission de données avec PySpark?
- GraphX: C'est une API Spark pour les graphiques, un moteur graphique réseau qui prend en charge le calcul graphique parallèle.
- Spark SQL: Il s'agit d'un framework distribué pour le traitement de données structurées fourni par Spark
On sait que les bases de données relationnelles stockent également les relations entre les différentes variables ainsi que les différentes tables et sont conçues de manière à pouvoir traiter des requêtes complexes..
Spark SQL est une combinaison étonnante de traitement relationnel et de programmation Spark fonctionnelle.. Prend en charge plusieurs sources de données et rend les requêtes SQL possibles, résultant en un outil très puissant pour analyser des données structurées à grande échelle.
Fonctionnalités Spark SQL
Spark SQL a une tonne de fonctionnalités impressionnantes, mais je voulais souligner quelques touches que vous utiliserez beaucoup dans votre fonction:
- Interroger les données de structure dans les programmes Spark: La plupart d'entre vous connaissent peut-être déjà SQL. Donc, vous n'avez pas besoin d'apprendre à définir une fonction complexe en Python ou Scala pour utiliser Spark. Vous pouvez utiliser exactement la même requête pour obtenir les résultats de vos plus grands ensembles de données !!
- Compatible avec Hive: Pas de SQL seul, mais vous pouvez également exécuter les mêmes requêtes Hive avec Spark SQL Engine. Permet une compatibilité totale avec les requêtes Hive actuelles.
- Une façon d'accéder aux données: Dans les projets typiques au niveau de l'entreprise, n'a pas de source de données commune. À sa place, doit gérer divers types de fichiers et de bases de données. Spark SQL prend en charge presque tous les types de fichiers et vous offre un moyen commun d'accéder à une variété de sources de données, comme Ruche, euro, Parquet, JSON et JDBC
- Performances et évolutivité: Lorsque vous travaillez avec de grands ensembles de données, il y a des chances que des erreurs se produisent entre le moment où la requête est exécutée. Spark SQL prend en charge la tolérance aux pannes totale à mi-requête, donc nous pouvons travailler même avec un millier de nœuds simultanément
- Fonctions définies par l'utilisateur: UDF est une fonctionnalité Spark SQL qui définit de nouvelles fonctions basées sur des colonnes qui étendent le vocabulaire Spark SQL pour transformer des ensembles de données
Comment Spark SQL exécute une requête?
Comment fonctionne Spark SQL, essentiellement? Comprenons le processus dans cette section.
- Une analyse: Premier, quand tu consultes quelque chose, Spark SQL trouve la relation à calculer. Il est calculé à l'aide d'un arbre de syntaxe abstrait (AST) où vous vérifiez l'utilisation correcte des éléments utilisés pour définir la requête, puis créez un plan logique pour exécuter la requête.

- Optimisation logique: Dans cette prochaine étape, l'optimisation basée sur des règles est appliquée au plan logique. Utiliser des techniques comme:
- Filtrez les données à l'avance si la requête contient un où clause
- Utiliser l'index disponible sur les tables, car il peut améliorer les performances, Oui
- Même en s'assurant que les différentes sources de données sont réunies dans l'ordre le plus efficace.
- Planification physique: Dans cette étape, un ou plusieurs plans physiques sont formés à l'aide du plan logique. Spark SQL sélectionne ensuite le plan qui pourra exécuter la requête de la manière la plus efficace, c'est-à-dire, utilisant moins de ressources de calcul.
- Code GÉNÉRATION: Dans la dernière étape, Spark SQL génère du code. Il s'agit de générer un bytecode Java à exécuter sur chaque machine. Catalyst utilise une fonction spéciale du langage Scala appelée “Quasiquotes” pour faciliter la génération de code.

Qu'est-ce qu'un optimiseur de catalyseur?
L'optimisation signifie la mise à jour du système ou du flux de travail existant de manière à ce qu'il fonctionne plus efficacement, en utilisant moins de ressources. Un optimiseur connu sous le nom de Optimiseur de catalyseur est implémenté dans Spark SQL qui prend en charge techniques d'optimisation basées sur les règles et les coûts.
Dans l'optimisation basée sur des règles, nous avons défini un ensemble de règles qui détermineront comment la requête sera exécutée. Il réécrira la requête existante d'une meilleure manière pour améliorer les performances.
Par exemple, disons qu'il y a un index disponible sur la table. Alors, l'index sera utilisé pour l'exécution des requêtes selon les règles et filtres O sera appliqué en premier sur les données initiales si possible (au lieu de les appliquer en dernier).
En outre, il y a des cas où l'utilisation d'un index ralentit une requête. Nous savons qu'il n'est pas toujours possible pour un ensemble défini de règles de toujours prendre de bonnes décisions, vérité?
Voici le problème: l'optimisation basée sur des règles ne prend pas en compte la distribution des données. C'est là que nous nous tournons vers un optimiseur basé sur les coûts. Utiliser des statistiques sur la table, vos index et la distribution de vos données pour prendre de meilleures décisions.
Exécuter des commandes SQL avec Spark
Le temps de coder!
J'ai créé un ensemble de données aléatoires de 25 millions de lignes. Vous pouvez télécharger l'ensemble de données complet ici. Nous avons un fichier texte avec des valeurs séparées par des virgules. Ensuite, premier, nous importerons les bibliothèques requises, nous allons lire l'ensemble de données et voir comment Spark partitionnera les données en partitions:
![]()
Ici,
- La première valeur de chaque ligne est l'âge de la personne (qui doit être un nombre entier)
- La deuxième valeur est le groupe sanguin de la personne (qui doit être une chaîne)
- Les troisième et quatrième valeurs sont la ville et le genre (les deux sont des chaînes), Oui
- La valeur finale est un identifiant (qui est de type entier)
Nous allons mapper les données de chaque ligne sur un type de données et un nom spécifiques à l'aide de lignes Spark:
![]()

Ensuite, nous allons créer un bloc de données en utilisant les lignes analysées. Notre objectif est de trouver les décomptes des valeurs de la variable genre en utilisant un simple par groupe fonction dans le bloc de données:

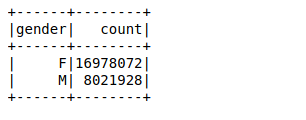

Il a fallu environ 26 ms pour calculer le nombre de valeurs de 25 millions de lignes à l'aide d'une fonction groupby dans le bloc de données. Vous pouvez calculer le temps en utilisant %%conditions météorologiques dans la cellule privée de son carnet Jupyter.
À présent, nous allons effectuer la même requête en utilisant Spark SQL et voir si cela améliore les performances ou non.
Premier, vous devez enregistrer le bloc de données en tant que table temporaire à l'aide de la fonction registreTempTable. Cela crée une table en mémoire qui ne s'étend qu'au cluster dans lequel elle a été créée. La durée de vie de cette table temporaire est limitée à une seule session. Il est stocké à l'aide Format de colonne en mémoire Hive qui est hautement optimisé pour les données relationnelles.
En outre, Vous n'avez même pas besoin d'écrire des fonctions complexes pour obtenir des résultats si vous êtes à l'aise avec SQL !! Ici, il vous suffit de passer la même requête SQL pour obtenir les résultats souhaités sur des données plus volumineuses:
![]()
Cela n'a pris qu'environ 18 ms calculer le nombre de valeurs. C'est beaucoup plus rapide que même une trame de données Spark.
Ensuite, nous allons effectuer une autre requête SQL pour calculer l'âge moyen dans une ville:
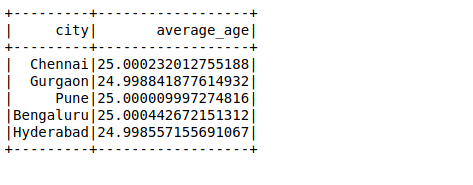
Cas d'utilisation d'Apache Spark à grande échelle
Nous savons que Facebook a plus de 2000 millions d'utilisateurs actifs mensuels et avec plus de données, faire face à des défis tout aussi complexes. Pour une seule requête, besoin d'analyser des dizaines de téraoctets de données en une seule requête. Facebook pense que Spark a mûri au point où nous pourrions le comparer à Hive pour un certain nombre de cas d'utilisation de traitement par lots..
Permettez-moi d'illustrer cela en utilisant une étude de cas de Facebook lui-même.. Une de ses tâches était de préparer les caractéristiques pour le classement des entités que Facebook utilise dans ses différents services en ligne. Précédemment, utilisé l'infrastructure basée sur Hive, qui nécessitait beaucoup de ressources et était difficile à maintenir, car le pipeline a été divisé en centaines d'emplois Hive. Ensuite, ils ont construit un pipeline plus rapide et plus gérable avec Spark. Vous pouvez lire sa tournée complète ici.
Ils ont comparé les résultats de Spark vs Hive Pipeline. Voici un tableau comparatif en terme de latence (temps écoulé d'un bout à l'autre du travail) ce qui montre clairement que Spark est beaucoup plus rapide que Hive.

Remarques finales
Nous avons couvert l'idée de base derrière Spark SQL dans cet article et avons également appris à l'utiliser à notre avantage.. Nous avons également pris un grand ensemble de données et appliqué notre apprentissage en Python.
Spark SQL est relativement inconnu de nombreux aspirants à la science des données, mais cela vous sera utile dans votre rôle dans l'industrie ou même dans les entretiens. C'est un ajout assez important aux yeux du responsable du recrutement..
Partagez vos pensées et suggestions dans la section commentaires ci-dessous..





