introduction
Les algorithmes d'apprentissage automatique sont classés en trois types: enseignement superviséL’apprentissage supervisé est une approche d’apprentissage automatique dans laquelle un modèle est formé à l’aide d’un ensemble de données étiquetées. Chaque entrée du jeu de données est associée à une sortie connue, permettre au modèle d’apprendre à prédire les résultats pour de nouvelles entrées. Cette méthode est largement utilisée dans des applications telles que la classification d’images, Reconnaissance vocale et prédiction de tendances, soulignant son importance dans..., Apprentissage non superviséL’apprentissage non supervisé est une technique d’apprentissage automatique qui permet aux modèles d’identifier des modèles et des structures dans des données sans étiquettes prédéfinies. Grâce à des algorithmes tels que les k-moyennes et l’analyse en composantes principales, Cette approche est utilisée dans une variété d’applications, comme la segmentation de la clientèle, Détection d’anomalies et compression de données. Sa capacité à révéler des informations cachées en fait un outil précieux dans le... y aprendizaje reforzado. Le clustering K-means est une technique d'apprentissage automatique non supervisée. Cuando no se proporciona la variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... de salida o respuesta, cet algorithme est utilisé pour catégoriser les données en différents groupes pour mieux les comprendre. Également connue sous le nom d'approche d'apprentissage automatique basée sur les données, car il regroupe les données en fonction de modèles cachés, connaissances et similitudes dans les données.
Considérez le schéma suivant: si on vous demande de regrouper les personnes sur la photo en différents groupes ou groupes et que vous ne savez rien à leur sujet, va certainement essayer de localiser les qualités, caractéristiques ou attributs physiques que ces personnes partagent. Après avoir observé ces gens, il est conclu qu'ils peuvent être séparés en fonction de leur hauteur et de leur largeur; puisque vous n'avez aucune connaissance préalable de ces personnes. Le clustering K-means effectue un travail à peu près équivalent. Essayez de classer les données en groupes en fonction des similitudes et des modèles cachés. « K » en clustering de K-means fait référence au nombre de clusters que l'algorithme va générer dans les données.
Regroupement K-Means: Comment ça marche?
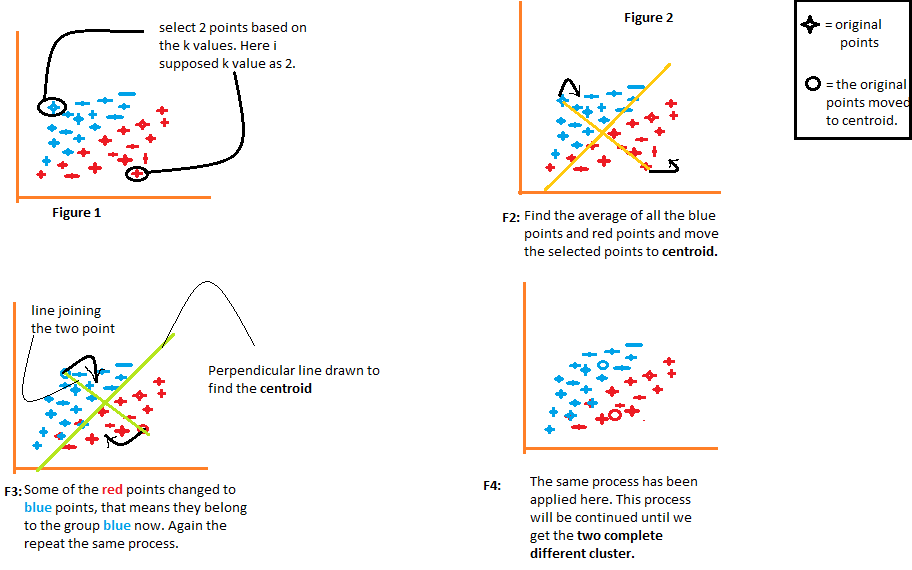
1) L'algorithme choisit arbitrairement le nombre k de centroïdes, como se indica en la chiffre"Chiffre" est un terme utilisé dans divers contextes, De l’art à l’anatomie. Dans le domaine artistique, fait référence à la représentation de formes humaines ou animales dans des sculptures et des peintures. En anatomie, désigne la forme et la structure du corps. En outre, en mathématiques, "chiffre" Il est lié aux formes géométriques. Sa polyvalence en fait un concept fondamental dans de multiples disciplines.... 1 du schéma suivant. Où k est le nombre de clusters que l'algorithme créerait. Disons que nous voulons que l'algorithme crée deux groupes à partir des données, nous allons donc définir la valeur de k à 2.
2) Ensuite, regroupez les données en deux parties en utilisant les distances calculées à partir des deux centroïdes., comme illustré sur la figure 2. La distance de chaque point des deux centroïdes est calculée individuellement et plus tard, elle sera ajoutée au groupe de ce centroïde avec lequel la distance est calculée. plus court.
L'algorithme trace également une ligne joignant les centroïdes et une ligne perpendiculaire qui essaie de regrouper les données en deux groupes.
3) Une fois que tous les points de données sont regroupés en fonction de leurs distances minimales par rapport aux centroïdes correspondants, l'algorithme calcule la moyenne de chaque groupe. Ensuite, les valeurs moyennes et centroïdes de chaque groupe sont comparées. Si la valeur centroïde diffère de la moyenne, alors le centre de gravité se déplace vers la valeur moyenne du groupe. Tant le centroïde « rouge » comme lui « bleu » sont relocalisés à la moyenne du groupe sur la figure 3 du schéma suivant.
Regroupez les données à l'aide de ces centroïdes mis à jour. En raison du changement de position des centroïdes, certains points de données peuvent maintenant être déplacés dans l'autre groupe.
4) Encore, calcule la moyenne et la compare avec le centroïde des groupes nouvellement générés. Si les deux sont différents, le centre de gravité sera relocalisé à la moyenne du groupe. Ce processus de calcul de la moyenne et de comparaison avec le centroïde est répété jusqu'à ce que les valeurs du centroïde et de la moyenne soient égales. (valeur centroïde = moyenne du groupe). Este es el punto en el que el algoritmo ha segmentado los datos en grupos ‘K’ (2 dans ce cas).
Comment savoir quelle est la valeur optimale de k?
La première étape consiste à fournir une valeur pour k. Chaque étape suivante exécutée par l'algorithme dépend entièrement de la valeur spécifiée de k. Cette valeur de k aide l'algorithme à déterminer le nombre de clusters à générer. Cela souligne l'importance de fournir la valeur précise de k. Ici, une méthode connue sous le nom de « méthode du coude » pour déterminer la valeur correcte de k. Este es un gráfico de ‘Número de conglomerados K’ face à « Total dans la somme du carré ». Les valeurs discrètes de k sont tracées sur l'axe des x, tandis que les sommes des carrés des groupes sont tracées sur l'axe des y.
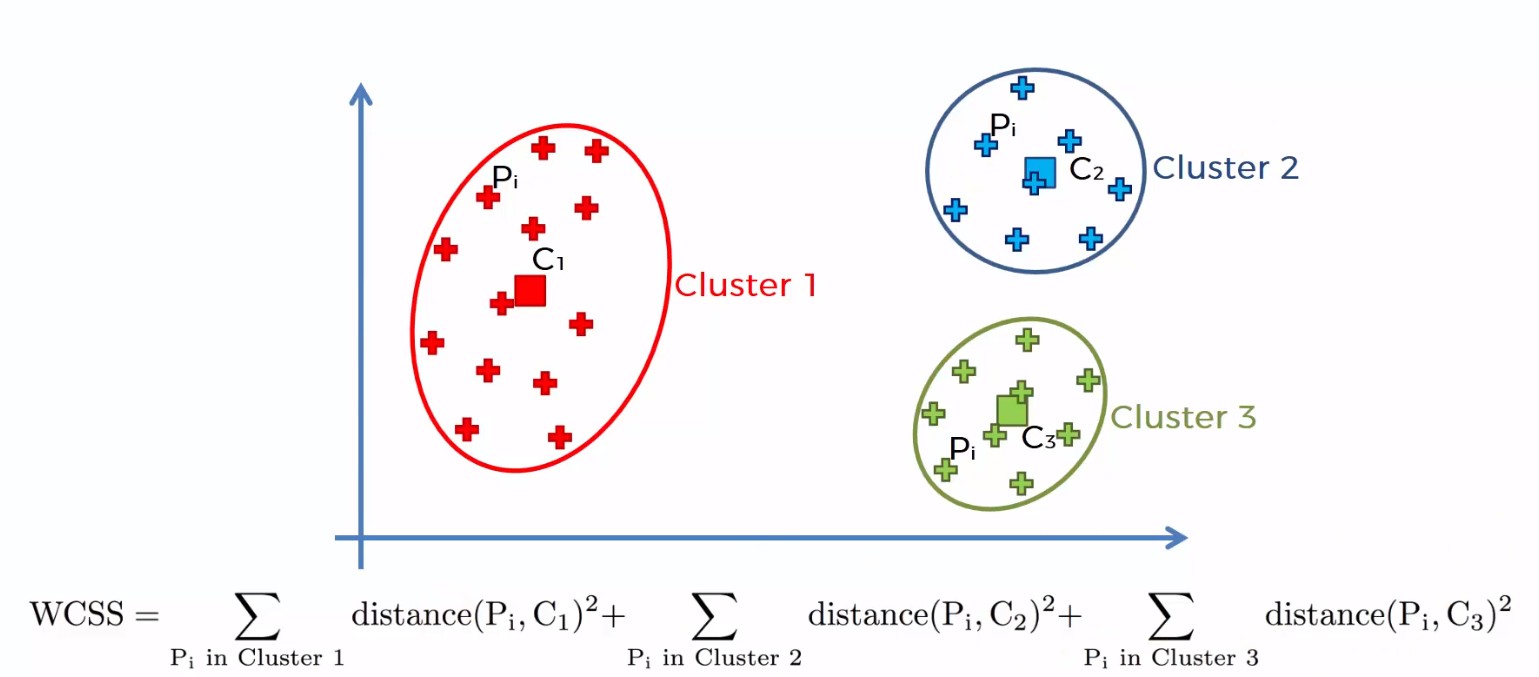
La somme des distances au carré entre les points individuels et le centroïde dans chaque groupe, suivi de la somme des distances au carré pour tous les clusters, Il est appelé "Somme des carrés dans le cluster". Vous pourrez comprendre cela à l'aide des étapes suivantes.
1) Calculer la distance entre le centre de gravité et chaque point du groupe, carré, puis ajoutez les distances au carré pour tous les points du groupe.
2) Calculer la somme des distances au carré des groupes restants de la même manière.
3) Finalement, additionner toutes les sommes des groupes pour obtenir la valeur de la "Somme du carré dans le groupe" comme le montre la figure suivante.
Le « total dans la somme du carré » comienza a disminuir a mesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... que aumenta el valor de k. Le graphique entre le nombre de clusters et le total dans la somme des carrés est illustré dans la figure suivante. Le nombre optimal de clusters, ou la valeur correcte de k, est le point auquel la valeur commence à diminuer lentement; c'est ce qu'on appelle le « pointe du coude », et le point du coude dans le graphique suivant est k = 4. Le « Méthode du coude » il est nommé pour la similitude du graphique avec le coude, et le sweet spot pour « k » est le point du coude .
Avantages du clustering k-means
1) Les données balisées ne sont pas obligatoires. Étant donné que de nombreuses données du monde réel ne sont pas étiquetées, par conséquent, sont fréquemment utilisés dans une variété d'énoncés de problèmes du monde réel.
2) Il est facile à mettre en œuvre.
3) Peut gérer des quantités massives de données.
4) Quand les données sont volumineuses, travailler plus vite que le regroupement hiérarchique (pour k petits).
Inconvénients du clustering K-means
1) La valeur de K doit être sélectionnée manuellement à l'aide de la « méthode du coude ».
2) La présence de valeurs aberrantes aurait un impact négatif sur le regroupement. Par conséquent, les valeurs aberrantes doivent être supprimées avant d'utiliser le groupement k-means.
3) Les groupes ne se croisent pas; un point ne peut appartenir qu'à un seul groupe à la fois. En raison de l'absence de chevauchement, certains points sont placés dans de mauvais groupes.
Regroupement des K-moyennes avec R
- Nous allons importer les bibliothèques suivantes dans notre travail.
une bibliothèque (intercalation)
une bibliothèque (ggplot2)
une bibliothèque (dépliant)
- Nous allons travailler avec les données de l'iris, contenant trois classes: « Iris-soyeux », « Iris-versicolor » e « Iris-virginica ».
Les données <- lire.csv ("iris.csv", en-tête = T)
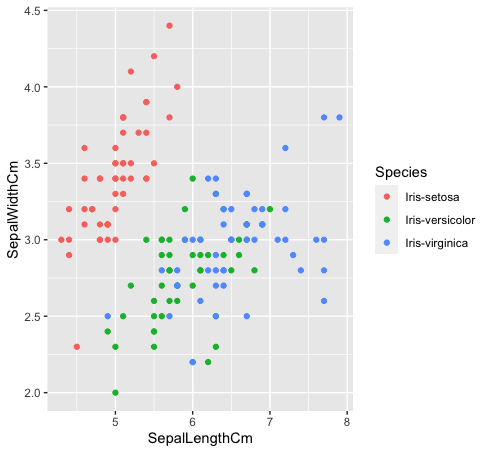
- Voyons comment ces trois classes sont liées les unes aux autres. Les espèces « Iris-versicolor » (vert) e « Iris-verginica » (bleu) ne sont pas linéairement séparables. Comme vous pouvez le voir dans le graphique ci-dessous, ils s'entremêlent.
Les données%>% ggplot (aes (SépaleLongueurCm, SepalLargeurCm, couleur = Espèce)) +
geom_point ()
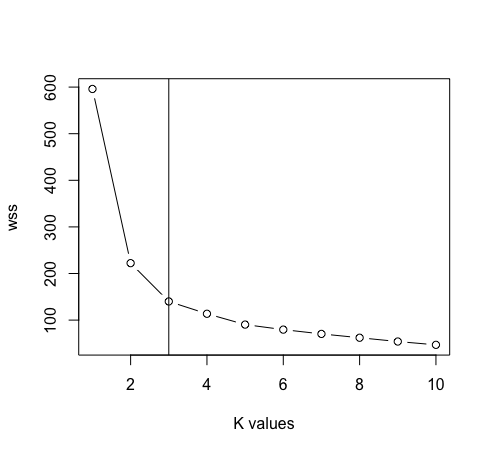
- Après avoir supprimé la colonne des espèces des données. Nous allons maintenant utiliser le graphique de la méthode du coude entre « Somme des carrés dans le cluster » Oui « Valeurs K » pour déterminer la valeur appropriée de k. K = 3 est la meilleure valeur pour k dans ce cas (Noter: il y a 3 classes dans les données d'iris d'origine, qui garantit la précision de la valeur de k).
Les données <- Les données[, -5]
maximum <- 10
écaille <- escalader (Les données)
wss <- sève (1: maximum, une fonction (k) {kméens (écaille, k, nstart = 50, iter.max = 15) $ tot.withinss})
terrain (1: max, wss, taper = « b », xlab = « k valeurs »)
abline (v = 3)
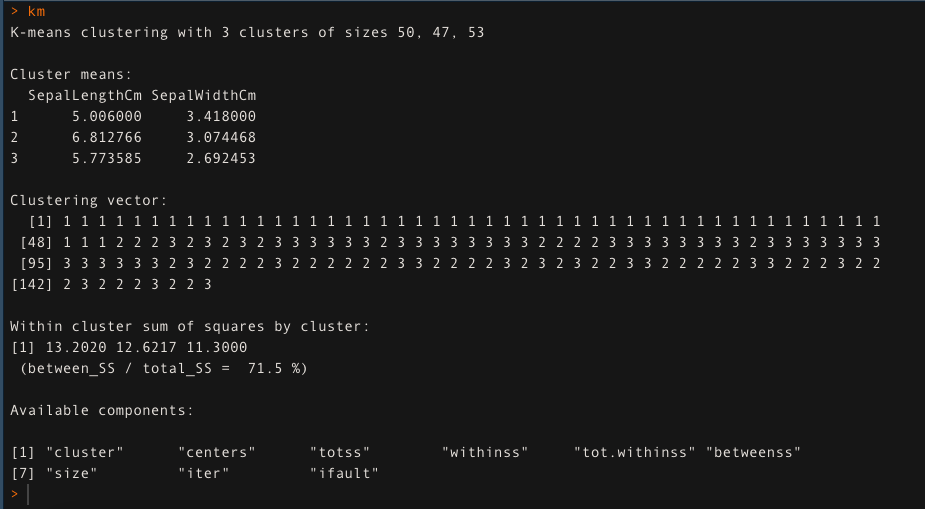
- Pour k = 3, aplique el algoritmo de regroupementLe "regroupement" Il s’agit d’un concept qui fait référence à l’organisation d’éléments ou d’individus en groupes ayant des caractéristiques ou des objectifs communs. Ce procédé est utilisé dans diverses disciplines, y compris la psychologie, Éducation et biologie, faciliter l’analyse et la compréhension de comportements ou de phénomènes. Dans le domaine de l’éducation, par exemple, Le regroupement peut améliorer l’interaction et l’apprentissage entre les élèves en encourageant le travail.. de K-medias. L'approche de clustering K-means explique la 71,5% de la variabilité des données dans ce cas.
km <- kmédias (Les données[,1:2], k = 3, iter.max = 50)
km
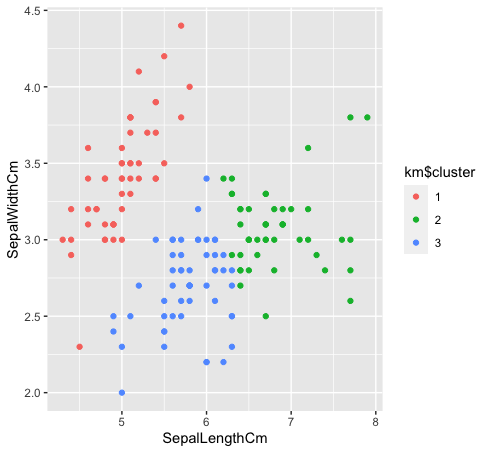
- Voyons comment les trois classes sont regroupées en regroupant les k-moyennes. Le clustering K-means ne créera pas de clusters qui se chevauchent, comme nous le savons tous. Puisque l'espèce « vert » Oui « bleu » ne sont pas linéairement séparables dans les données d'origine, le regroupement des k-moyennes n'a pas pu le capturer car il a des groupes réduits.
km $ grappe <- comme.facteur (km $ grappe)
Les données%>% ggplot (aes (SépaleLongueurCm, SepalLargeurCm, couleur = km $ grappe)) +
geom_point ()
Un article de ~
Shivam Sharma.
Les médias présentés dans cet article sur l'algorithme de regroupement K-Means ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





