Cibler
- LSTM est un type spécial de réseau neuronal récurrent capable de gérer les dépendances à long terme.
- Comprendre l'architecture et le fonctionnement d'un réseau LSTM
introduction
Le réseau de mémoire à long court terme est un RNN avancé, un réseau séquentiel, qui permet à l'information de persister. Est capable de gérer le problème du gradient de disparition auquel RNN est confronté. Un réseau de neurones récurrent est également connu sous le nom de RNN et est utilisé pour la mémoire persistante.
Disons qu'en regardant une vidéo, vous vous souvenez de la scène précédente ou en lisant un livre, vous savez ce qui s'est passé dans le chapitre précédent. de la même manière, Les RNN fonctionnent, mémoriser les informations précédentes et les utiliser pour traiter l'entrée actuelle. Le défaut de RNN est qu'ils ne peuvent pas se souvenir des dépendances à long terme dues au gradient de disparition. Les LSTM sont explicitement conçus pour éviter les problèmes de dépendance à long terme.
Noter: Si vous êtes plus intéressé par l'apprentissage de concepts dans un format audiovisuel, nous avons cet article complet expliqué dans la vidéo ci-dessous. Si ce n'est pas comme ça, tu peux continuer à lire.
Architecture LSTM
A un niveau élevé, LSTM fonctionne un peu comme une cellule RNN. Voici le fonctionnement interne du réseau LSTM. Le LSTM se compose de trois parties, comme indiqué dans l'image ci-dessous et chaque partie remplit une fonction individuelle.
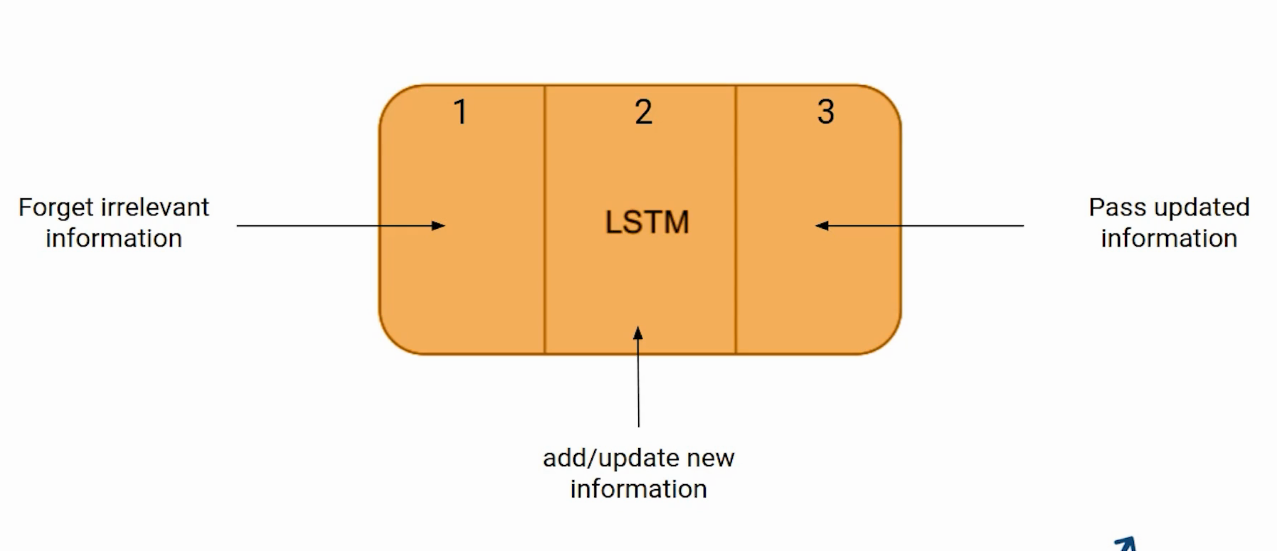
La première partie choisit si les informations provenant de l'horodatage précédent doivent être mémorisées ou si elles ne sont pas pertinentes et peuvent être oubliées. Dans la deuxième partie, la cellule essaie d'apprendre de nouvelles informations à partir de l'entrée de cette cellule. Finalement, dans la troisième partie, la cellule transmet les informations mises à jour de l'horodatage actuel au suivant.
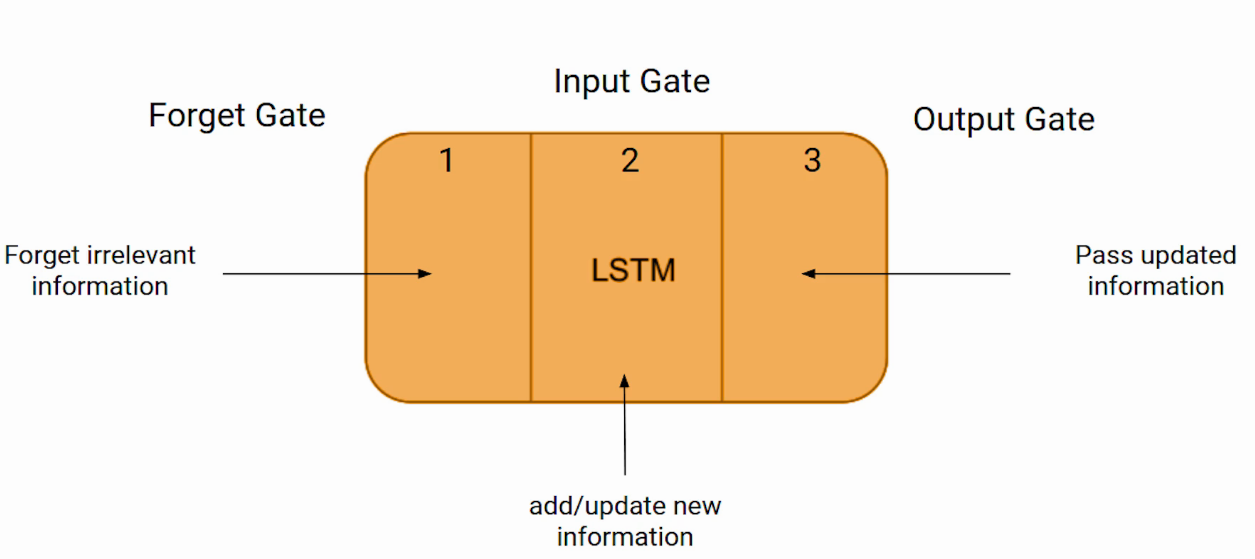
Ces trois parties d'une cellule LSTM sont appelées portes. La première partie s'appelle Oublie la porte, la la deuxième partie est connue sous le nom la porte d'entrée et le dernier est la porte de sortie.
Comme un simple RNN, un LSTM a également un état caché où H (t-1) représente l'état caché de l'horodatage précédent et Ht est l'état caché de l'horodatage actuel. En plus de ça, LSTM a également un état de cellule représenté par C (t-1) y C
Ici, l'état caché est appelé mémoire à court terme et l'état de la cellule est appelé mémoire à long terme. Veuillez vous référer à l'image suivante.
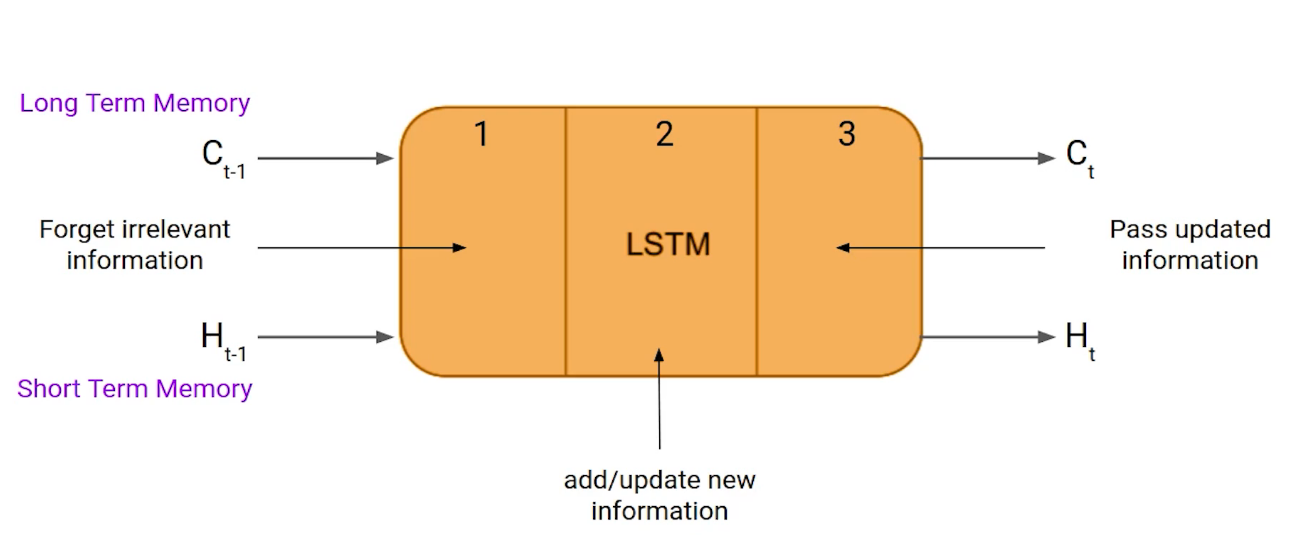
Il est intéressant de noter que l'état de la cellule porte l'information avec tous les horodatages.
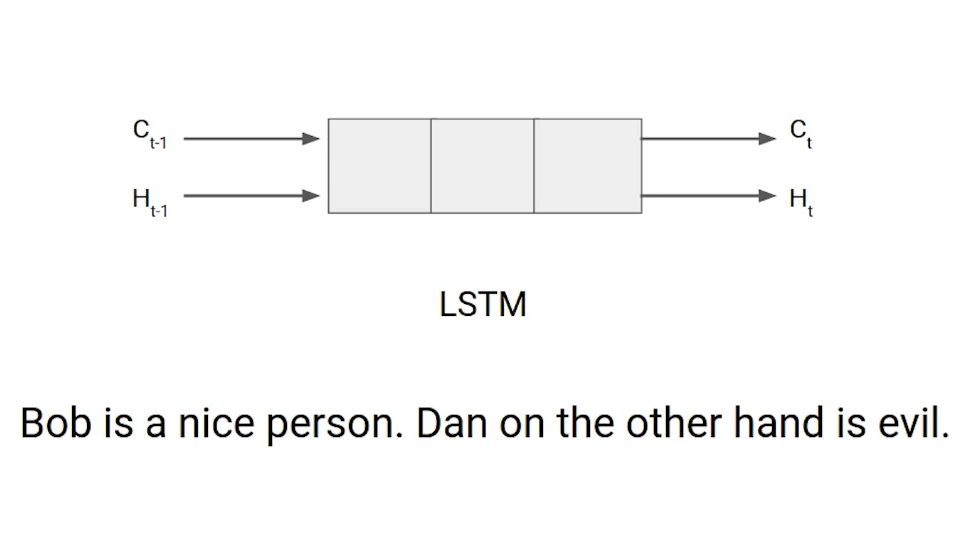
Prenons un exemple pour comprendre comment fonctionne LSTM. Ici, nous avons deux phrases séparées par un point. La première phrase est “Bob est une bonne personne” et la deuxième phrase est “Et, d'un autre côté, c'est mal”. C'est très clair, dans la première phrase on parle de Bob et dès qu'on trouve le point (.) Nous avons commencé à parler de Dan.
En passant de la première phrase à la seconde, notre réseau doit se rendre compte que nous ne parlons plus de Bob. Maintenant notre sujet est Dan. Ici, la porte Forget Network vous permet de l'oublier. Comprenons les rôles que jouent ces portes dans l'architecture LSTM.
Oublier la porte
Dans une cellule du réseau LSTM, la première étape consiste à décider si nous devons conserver l'ancienne information d'horodatage ou l'oublier. Voici l'équation de la porte de l'oubli.
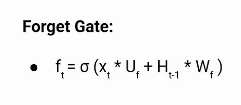
Essayons de comprendre l'équation, ici
- Xt: entrée dans l'horodatage actuel.
- Uf: poids associé à l'entrée
- Ht-1: l'état caché de l'horodatage précédent
- Wf: C'est la matrice de pondération associée à l'état caché.
Ensuite, une fonction sigmoïde lui est appliquée. Cela fera ft être un nombre entre 0 Oui 1. Ce ft est ensuite multiplié par l'état de la cellule de l'horodatage précédent, comme il est montré dans ce qui suit.

Si ft est 0, le réseau oubliera tout et si la valeur de ft est 1, n'oubliera rien. Revenons à notre exemple. La première phrase parlait de Bob et après un point, le net rencontrera Dan, dans un cas idéal, le net devrait oublier Bob.
Porte d'entrée
Prenons un autre exemple
« Bob sait nager. Il m'a dit au téléphone qu'il avait servi dans la marine pendant quatre longues années “.
Ensuite, dans ces deux phrases, on parle de bob. Cependant, les deux fournissent différents types d'informations sur Bob. Dans la première phrase, nous obtenons l'information que vous savez nager. Alors que la deuxième phrase dit qu'il utilise le téléphone et a servi dans la marine pendant quatre ans.
Maintenant, penses-y, sur la base du contexte donné dans la première phrase, quelle information dans la deuxième phrase est critique. Premier, utilisé le téléphone pour conseiller ou servi dans la marine. Dans ce contexte, Peu importe si vous avez utilisé le téléphone ou tout autre moyen de communication pour transmettre les informations. Le fait qu'il était dans la Marine est une information importante et c'est quelque chose que nous voulons que notre modèle se souvienne. C'est la tâche de la porte d'entrée.
Le portail d'entrée permet de quantifier l'importance des nouvelles informations véhiculées par le portail d'entrée. Voici l'équation de la porte d'entrée.
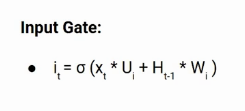 Ici,
Ici,
- Xt: Entrée avec l'horodatage actuel t
- Interface utilisateur: matrice des poids d'entrée
- Ht-1: un état caché dans l'horodatage précédent
- Wi: matrice de poids de l'entrée associée à l'état caché
Encore une fois, nous avons appliqué la fonction sigmoïde. Par conséquent, la valeur de I à l'horodatage t sera comprise entre 0 Oui 1.
Nouvelle information
![]()
À présent, les nouvelles informations qui devaient passer à l'état de la cellule sont fonction d'un état caché à l'horodatage précédent t-1 et de l'entrée x à l'horodatage t. La fonction d'activation ici est tanh. En raison de la fonction tanh, la valeur des nouvelles informations sera comprise entre -1 Oui 1. Si la valeur de Nt est négative, l'information est soustraite de l'état de la cellule et si la valeur est positive, les informations sont ajoutées à l'état de la cellule à la date et à l'heure actuelles.
Cependant, le Nt ne sera pas ajouté directement à l'état de la cellule. Voici l'équation mise à jour

Ici, Ct-1 est l'état de la cellule à l'horodatage actuel et les autres sont les valeurs que nous avons précédemment calculées.
Porte de sortie
Considérez maintenant cette phrase
"Bob a combattu l'ennemi seul et est mort pour son pays. Pour vos cotisations, courageux________. “
Au cours de cette tâche, nous devons compléter la deuxième phrase. À présent, au moment où nous voyons le mot courageux, nous savons que nous parlons d'une personne. Dans la phrase, seul Bob est courageux, on ne peut pas dire que l'ennemi est courageux ou que le pays est courageux. Ensuite, basé sur les attentes actuelles, nous devons donner un mot pertinent pour remplir le blanc. Ce mot est notre sortie et c'est la fonction de notre porte de sortie.
Voici l'équation de la porte de sortie, qui est assez similaire aux deux portes précédentes.
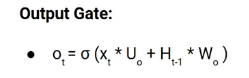
Sa valeur sera également comprise entre 0 Oui 1 grâce à cette fonction sigmoïde. À présent, pour calculer l'état caché actuel, nous utiliserons Ot et tanh à partir de l'état de la cellule mis à jour. Comme indiqué ci-dessous.
![]()
Il s'avère que l'état caché est fonction de la mémoire à long terme (Ct) et la sortie courant. Si vous devez sortir l'horodatage actuel, il suffit d'appliquer l'activation SoftMax dans l'état caché Ht.
![]()
Ici, le jeton avec le score le plus élevé dans la sortie est la prédiction.
C'est le schéma le plus intuitif du réseau LSTM.
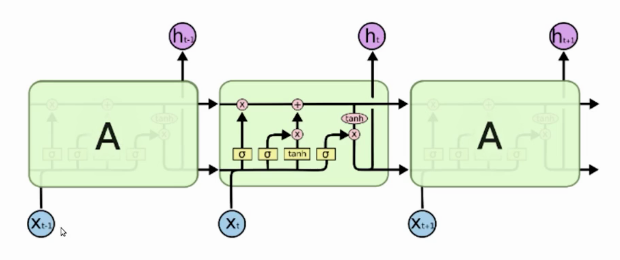
Ce schéma est tiré d'un blog intéressant. J'invite tout le monde à le vérifier. Voici le lien-
Remarques finales
En résumé, dans cet article nous avons vu en détail l'architecture d'un modèle LSTM séquentiel et son fonctionnement.
Si vous cherchez à commencer votre parcours en science des données et que vous voulez tous les sujets sous un même toit, votre recherche s'arrête ici. Jetez un œil à l'IA et au ML BlackBelt certifiés de DataPeaker Plus Programme
Si vous avez des questions, Faites le moi savoir dans la section commentaire!





