Matrice de confusion: Pas si déroutant!!
Avez-vous été dans une situation où vous vous attendiez à ce que votre modèle d’apprentissage automatique fonctionne vraiment bien?, mais a donné une précision médiocre? Vous avez fait tout le travail difficile, ensuite, Où le modèle de classification a-t-il mal tourné?? Comment pouvez-vous corriger cela??
Il existe de nombreuses alternatives pour mesurer la performance de votre modèle de classement, Mais aucun n’a résisté à l’épreuve du temps en tant que matrice de confusion.. Cela nous aide à examiner comment notre modèle a fonctionné., Où cela s’est mal passé et nous offre un guide pour corriger notre chemin.

Dans ce billet, Nous explorerons comment une matrice de confusion fournit une vue holistique des performances de votre modèle.. Et contrairement à son nom, Vous vous rendrez compte qu’une matrice de confusion est un concept assez simple mais puissant.. Dévoilons donc le mystère autour de la matrice de la confusion !!

Apprendre les ficelles du métier dans le domaine de l’apprentissage automatique? Ces cours vous aideront à suivre votre chemin:
Voici ce que nous allons couvrir:
- Qu’est-ce qu’une matrice de confusion??
- Vraiment positif
- Vrai négatif
- Faux positif: Erreur de type 1
- Faux négatif – Erreur de type 2
- Pourquoi vous avez besoin d’une matrice de confusion?
- Précision vs récupération
- Score F1
- Matrice de confusion dans Scikit-learn
- Matrice de confusion pour la classification à classes multiples
Qu’est-ce qu’une matrice de confusion??
La question à un million de dollars: Qu'est que c'est, après tout, Une matrice de confusion?
Une matrice de confusion est une matrice N x N utilisée pour examiner les performances d’un modèle de classification., où N est le nombre de classes cibles. La matrice compare les valeurs cibles réelles avec celles prédites par le modèle d’apprentissage automatique. Cela nous donne une vision holistique de la performance de notre modèle de classement et du type d’erreurs qu’il commet..
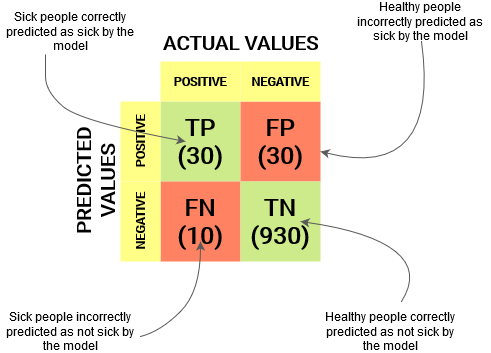
Pour un obstacle de classification binaire, Nous aurions une matrice de 2 X 2 comme indiqué ci-dessous avec 4 valeurs:
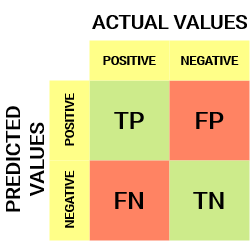
Déchiffrons la matrice:
- La variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... de destino tiene dos valores: Positif O Négatif
- Les Colonnes représentent le valeurs actuelles de la variable cible
- Les Lignes représentent le valeurs prédites de la variable cible
Mais attendez, Qu’est-ce que TP, PF, FN et TN ici? C’est la partie cruciale d’une matrice de confusion.. Comprenons chaque terme ci-dessous.
Comprendre le vrai positif, Le vrai négatif, Le faux positif et le faux négatif dans une matrice de confusion
Vrai positif (PQ)
- La valeur prédite correspond à la valeur réelle
- La valeur réelle était positive et le modèle prédisait une valeur positive.
Vrai négatif (TN)
- La valeur prédite correspond à la valeur réelle
- La valeur réelle était négative et le modèle prédisait une valeur négative.
Faux positif (PF): Erreur de type 1
- La valeur prédite a été faussement prédite
- La valeur réelle était négative, mais le modèle prédisait une valeur positive
- Aussi connu sous le nom de Erreur-type 1
Faux négatif (FN): Erreur de type 2
- La valeur prédite a été faussement prédite
- La valeur réelle était positive, mais le modèle prédisait une valeur négative
- Aussi connu sous le nom de Erreur de type 2
Laissez-moi vous donner un exemple pour mieux connaître cela. Supposons que nous ayons un jeu de données de classification avec 1000 points de données. Nous mettons un classificateur dessus et obtenons la matrice de confusion suivante:
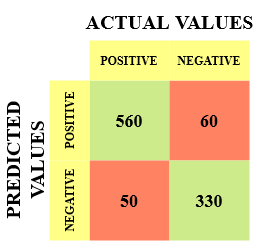
Les différentes valeurs de la matrice de confusion seraient les suivantes ::
- Vrai positif (PQ) = 560; Ce qui signifie que 560 Les points de données de classe positifs ont été correctement classés par le modèle
- Vrai négatif (TN) = 330; Ce qui signifie que 330 Les points de données de classe négative ont été correctement classés par le modèle
- Faux positif (PF) = 60; ce qui signifie que le modèle n’a pas été classé correctement 60 Points de données de classe négative comme appartenant à la classe positive
- Faux négatif (FN) = 50; ce qui signifie que le modèle n’a pas été classé correctement 50 points de données de classe positive comme appartenant à la classe négative
Cela s’est avéré être un classificateur assez décent pour notre ensemble de données compte tenu du nombre relativement plus élevé de valeurs vraies positives et de valeurs vraies négatives..
Mémoriser les erreurs de type 1 et type 2. Les intervieweurs adorent demander la différence entre les deux!! Vous pouvez mieux vous préparer à tout cela à partir de notre Cours d’apprentissage automatique en ligne
Pourquoi nous avons besoin d’une matrice de confusion?
Avant de répondre à cette question, Considérons un obstacle de classification hypothétique.
Supposons que vous vouliez prédire combien de personnes sont infectées par un virus contagieux avant qu’elles ne présentent des symptômes et les isoler de la population en bonne santé. (Est-ce que cela sonne encore quelque chose?? 😷). Les deux valeurs de notre variable cible seraient: Malades et non malades.
À présent, tu dois te demander: Pourquoi avons-nous besoin d’une matrice de confusion alors que nous avons notre ami de tous les temps?: précision? Bon, Voyons où la précision échoue.
Notre ensemble de données est un exemple de Jeu de données déséquilibré. Il y a 947 points de données pour la classe négative et 3 Points de données pour la classe positive. C’est ainsi que nous calculerons la précision: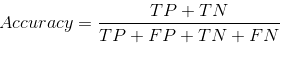
Voyons comment notre modèle a fonctionné:
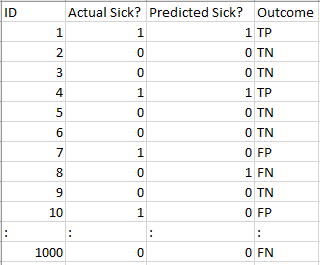
Les valeurs de résultat totales sont les suivantes ::
TP = 30, TN = 930, PF = 30, FN = 10
Ensuite, La précision de notre modèle s’avère être:
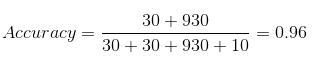
96%! Pas mal!
Mais cela donne une mauvaise idée du résultat.. Penser.
Notre modèle dit « Je peux prédire les personnes malades sur 96% du temps ». Malgré cela, fait le contraire. C’est prédire aux gens qu’ils ne tomberont pas malades avec un 96% Précision pendant que les malades propagent le virus!
Pensez-vous qu’il s’agit d’une mesure correcte pour notre modèle compte tenu de la gravité du problème?? Ne devrions-nous pas mesurer le nombre de cas positifs que nous pouvons prédire correctement pour arrêter la propagation du virus contagieux?? Ou peut-être, Nombre de cas correctement prévus, Combien y a-t-il de cas positifs pour vérifier la fiabilité de notre modèle?
C’est là que l’on retrouve le double concept de précision et de rappel..
Précision vs récupération
La précision nous indique combien de cas correctement prédits se sont avérés vraiment positifs..
Ensuite, Explique comment calculer la précision:
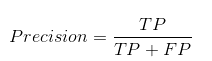
Cela déterminerait si notre modèle est fiable ou non..
Recall nous indique combien de cas positifs réels nous avons pu prédire correctement avec notre modèle.
Et voici comment nous pouvons calculer le rappel:
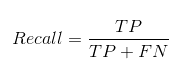
Nous pouvons facilement calculer la précision et le rappel pour notre modèle en reliant les valeurs des questions ci-dessus.:
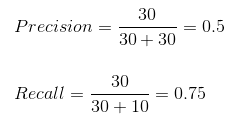
Le 50% des cas correctement prédits se sont avérés positifs. Bien que notre modèle ait réussi à prédire le 75% des points positifs. Impressionnant!
L’exactitude est une mesure utile dans les cas où les faux positifs sont plus préoccupants que les faux négatifs..
La précision est essentielle dans les systèmes de recommandation musicale ou vidéo, Sites Web de commerce électronique, etc. Des résultats incorrects peuvent entraîner une perte de clients et être préjudiciables à l’entreprise.
La récupération est une mesure utile dans les cas où le faux négatif l’emporte sur le faux positif.
Le rappel est essentiel dans les cas médicaux où peu importe si nous donnons une fausse alerte., Mais les vrais cas positifs ne doivent pas passer inaperçus !!
Dans notre exemple, Le rappel serait une meilleure mesure parce que nous ne voulons pas libérer accidentellement une personne infectée et la laisser se mélanger à la population en bonne santé, propageant ainsi le virus contagieux.. Vous pouvez maintenant comprendre pourquoi la précision était une mauvaise mesure pour notre modèle..
Mais il y aura des cas où il n’y aura pas de distinction claire entre la précision et la récupération.. Que devrions-nous faire dans de tels cas?? Nous les combinons!
Score F1
Dans la pratique, Lorsque nous essayons d’augmenter la précision de notre modèle, La récupération ralentit et vice versa. Le score F1 capture les deux tendances en une seule valeur:
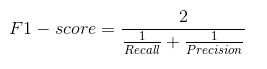
Le score F1 est un moyen harmonique de précision et de récupération, Cela donne donc une idée combinée de ces deux métriques. Maximum lorsque Précision est égal à Rappel.
Mais il y a un hic.. L’interprétabilité du score F1 est médiocre. Cela signifie que nous ne savons pas ce que notre classificateur maximise.: Exactitude ou rappel? Ensuite, Nous l’utilisons en combinaison avec d’autres mesures d’évaluation qui nous donnent une image complète du résultat.
Matrice de confusion utilisant scikit-learn en Python
Vous connaissez déjà la théorie, Maintenant, mettons-le en pratique. Codeons une matrice de confusion avec la bibliothèque Scikit-learn (apprendre) et Python.

Sklearn a deux grandes fonctions: matrice de confusion() Oui classement_rapport ().
- Sklearn matrice de confusion() Renvoie les valeurs de la matrice de confusion.. Malgré cela, Le résultat est légèrement différent de ce que nous avons étudié jusqu’à présent.. Prend les lignes comme valeurs réelles et les colonnes comme valeurs prédites. Le reste du concept reste le même.
- Sklearn classement_rapport () Génère de la précision, Récupération et score F1 pour chaque classe cible. En même temps que ce, Il a également quelques valeurs supplémentaires: micro moyenne, Moyenne macro, Oui moyenne pondérée
Mirco moyen est la précision / Récupération / Score F1 calculé pour toutes les classes.
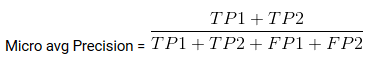
Macro multimédia est la précision moyenne / Je me souviens / Score F1.
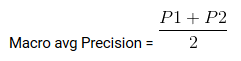
Poids moyen n’est que la moyenne pondérée de la précision / Récupération / Score F1.
Matrice de confusion pour la classification à classes multiples
Comment une matrice de confusion fonctionnerait-elle pour un obstacle de classification multiclasse?? Bon, Ne vous grattez pas la tête!! Nous allons jeter un coup d’œil à cela ici.
Dessinons une matrice de confusion pour un obstacle multi-classe où nous devons prédire si une personne aime Facebook., Instagram ou Snapchat. La matrice de confusion serait une matrice de 3 X 3 Comment ça va:
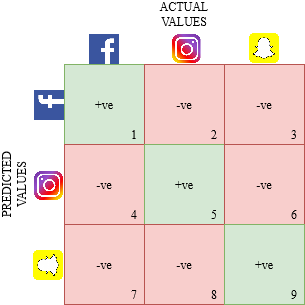
Le vrai positif, vrai négatif, Les faux positifs et les faux négatifs de chaque classe seraient calculés en additionnant les valeurs de cellule comme suit:
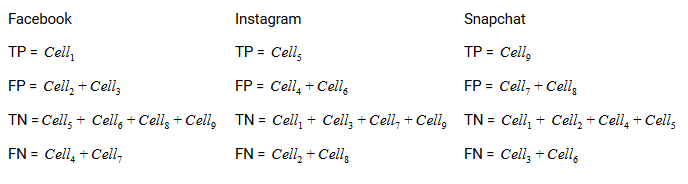
C'est tout! Vous êtes prêt à déchiffrer n’importe quelle matrice de confusion N x N!!
Remarques finales
Et soudain !, La matrice de confusion n’est plus aussi confuse! Cet article devrait vous donner une base solide sur la façon d’interpréter et d’utiliser une matrice de confusion pour classer les algorithmes dans l’apprentissage automatique..
Bientôt, nous publierons un article sur la courbe AUC-ROC et poursuivrons notre discussion là-bas. Jusqu’à la prochaine fois, Ne perdez pas espoir dans votre modèle de classification, Vous utilisez peut-être la mauvaise métrique d’évaluation!!





