Booster l'algorithme en machine learning
Impulsion peut être appelé un ensemble d'algorithmes dont la fonction principale est de transformer les élèves faibles en élèves forts. Ils sont devenus courants Industrie de la science des données parce qu'ils ont été dans le communauté d'apprentissage automatique pendant des années. L'impulsion a d'abord été saisie par Freund et Schapire dans l'année 1997 avec son Algoritmo AdaBoost, et depuis lors, l'impulsion a été une technique prédominante pour résoudre problèmes de classification binaire.
Pourquoi les algorithmes de boost sont-ils si populaires ??
Pour savoir ça, en termes plus simples. booster les algorithmes peut surpasser des algorithmes plus simples comme Forêt aléatoire, arbres de décision ou régression logistique. C'est l'une des principales raisons de l'augmentation de la promotion d'algorithmes par de nombreux concurrents de l'apprentissage automatique en raison du fait que les algorithmes d'impulsion sont puissants.. Même comme ça, peut s'améliorer précision de la prédiction de votre modèle par un nombre considérable de facteurs. De nombreux concurrents de l'apprentissage automatique utilisent un seul algorithme de boost ou plusieurs algorithmes de boost pour résoudre les problèmes respectifs.
Algorithme d'impulsion expliqué
Impulsion combiner des élèves faibles pour former un élève fort, où un apprenant faible définit un classificateur légèrement corrélé avec la classification réelle. Contrairement à un élève faible, un apprenant fort est un classificateur associé aux bonnes catégories.
Pour savoir ça, prenons un scénario:
Supposons que vous construisiez un Modèle de forêt aléatoire ce qui vous donne une précision de 75% dans l'ensemble de données de validation et, ensuite, décider de tester un autre modèle sur le même ensemble de données. Supposons que vous essayez linéaire modèle de régression et kNN sur le même jeu de données de validation, et maintenant votre modèle vous donne une précision de 69% Oui 92%, respectivement. Il est clair que les trois modèles fonctionnent de manières absolument différentes et fournissent des résultats absolument différents sur le même ensemble de données..
As-tu déjà pensé, au lieu d'utiliser simplement l'un de ces modèles, et si nous utilisions une combinaison de tous ces modèles pour faire les prédictions finales?
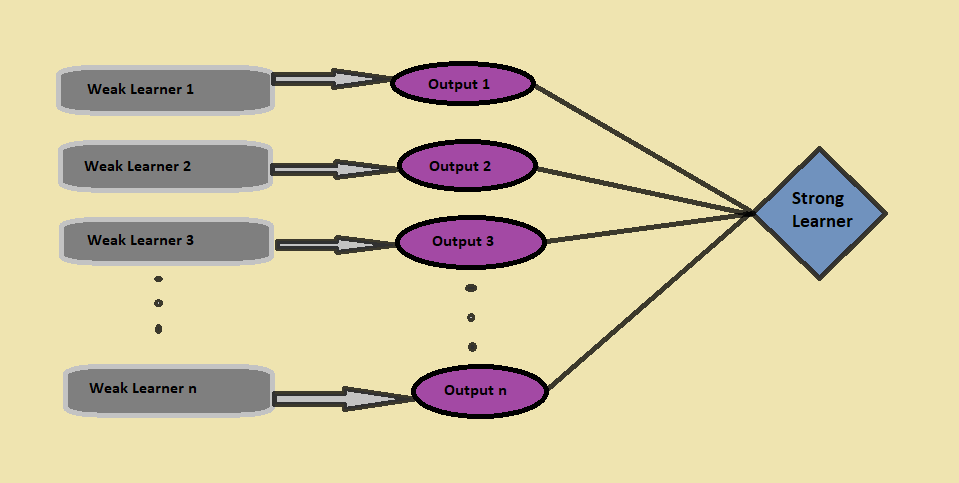
Nous allons capturer plus d'informations à partir des données en prenant la moyenne des prédictions de ces modèles.; Équivalent, l'algorithme boost combine plusieurs modèles plus simples (aussi appelés élèves faibles) pour générer le résultat final (aussi appelé élève fort).
Maintenant, penseriez-vous à la façon d'identifier les élèves faibles?
Identifier les élèves faibles, nous utilisons algorithmes d'apprentissage automatique avec une distribution différente pour chaque itération et pour chaque algorithme, génère une nouvelle règle de prédiction faible. Après plusieurs itérations, l'algorithme boost combine tous les apprenants vulnérables pour former une règle de prédiction à chaîne unique.
Une autre chose essentielle à laquelle faire attention ici est, ‘¿Cómo determinamos una distribución distinto para cada ronda?’
Il y a trois étapes que nous devons considérer pour sélectionner la bonne distribution:
- L'élève faible considère toutes les distributions et attribue ensuite un poids égal à chaque observation, après
- Si l'erreur est générée par la prévision du premier algorithme d'apprentissage faible, plus d'attention est accordée à l'erreur de prédiction des observations. L'algorithme d'apprentissage faible suivant s'applique.
- Finalement, répéter la deuxième étape jusqu'à ce que l'algorithme d'apprentissage de base atteigne sa limite ou que la précision souhaitée soit atteinte.
Enfin, comme conséquence, l'algorithme boost combine toutes les sorties des élèves faibles. Se présente avec un élève plus fort et plus puissant, ce qui améliore finalement la précision de la prévision du modèle (como se ve en la chiffre"Chiffre" est un terme utilisé dans divers contextes, De l’art à l’anatomie. Dans le domaine artistique, fait référence à la représentation de formes humaines ou animales dans des sculptures et des peintures. En anatomie, désigne la forme et la structure du corps. En outre, en mathématiques, "chiffre" Il est lié aux formes géométriques. Sa polyvalence en fait un concept fondamental dans de multiples disciplines.... antérieur).
En boostant, au lieu de simplement combiner les classificateurs isolés, utilise le mécanisme d'augmentation des poids des points de données mal classés dans les classificateurs ci-dessus.
Types d'algorithmes d'impulsions
Il est temps de discuter maintenant de certains des types essentiels d'algorithmes de quantité de mouvement.
1. Aumento de penteLe gradient est un terme utilisé dans divers domaines, comme les mathématiques et l’informatique, pour décrire une variation continue de valeurs. En mathématiques, fait référence au taux de variation d’une fonction, pendant la conception graphique, S’applique à la transition de couleur. Ce concept est essentiel pour comprendre des phénomènes tels que l’optimisation dans les algorithmes et la représentation visuelle des données, permettant une meilleure interprétation et analyse dans...
Dans le augmentation de la pente algorithme, nous entraînons plusieurs modèles séquentiellement, et pour chaque nouveau modèle, el modelo minimiza gradualmente la Fonction de perteLa fonction de perte est un outil fondamental de l’apprentissage automatique qui quantifie l’écart entre les prédictions du modèle et les valeurs réelles. Son but est de guider le processus de formation en minimisant cette différence, permettant ainsi au modèle d’apprendre plus efficacement. Il existe différents types de fonctions de perte, tels que l’erreur quadratique moyenne et l’entropie croisée, chacun adapté à différentes tâches et... usando el método Gradient Descent. Les Algorithme d'augmentation d'arbre de gradient vous acceptez arbres de décision comme le faible mince parce que les nœuds d'un arbre de décision considèrent une branche de caractéristiques différente pour choisir la meilleure division, ce qui signifie que tous les arbres ne sont pas les mêmes. Pour cela, peut capturer différentes sorties de données tout le temps.
L'algorithme d'augmentation d'arbre de gradient est construit séquentiellement car, pour chaque nouvel arbre, le modèle considère les erreurs du dernier arbre, et la décision de chaque arbre successif est basée sur les erreurs commises par l'arbre précédent.
Les algorithmes de Gradient Boosting sont principalement utilisés pour les problèmes de classification et de régression.
Code Python:
de sklearn.ensemble importar GradientBoostingClassifier #Pour le classement
de sklearn.ensemble importer GradientBoostingRegressor #Pour la régression
cl = GradientBoostingClassifier (n_estimateurs = 100, taux_apprentissage = 1.0, profondeur_max = 1)
cl.fit (Xtrain, ytrain)
où:
n_estimateurs Le paramètre est utilisé pour contrôler le nombre d'élèves faibles,
taux d'apprentissage Le paramètre contrôle la contribution de tous les élèves vulnérables dans le résultat final,
Profondeur maximale Le paramètre est pour la profondeur maximale des estimateurs de régression individuels pour limiter le nombre de nœuds dans l'arbre.
2. AdaBoost (renforcement adaptatif)
L'algorithme AdaBoost, court pour Conduite adaptative, est une technique de boost dans l'apprentissage automatique qui est utilisée comme Définir la méthode. Dans Conduite adaptative, tous les poids sont réaffectés à chaque instance où des poids plus élevés sont affectés à des modèles mal classés, et correspond à la séquence d'élèves faibles à différents poids.
Adaboost commence avec faire des prédictions sur l'ensemble de données d'origine en langage clair, puis donner le même poids à chaque observation. Si la prévision faite avec le premier élève est incorrecte, attribue le pertinence plus élevée pour l'énoncé mal prédit et la procédure itérative. Continuez à ajouter de nouveaux étudiants jusqu'à ce que la limite du modèle soit atteinte.
Podemos utilizar cualquier algoritmo de aprendizaje automático con Adaboost como estudiantes débiles si acepta pesos en el conjunto de datos de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... y se utiliza tanto para problemas de regresión como de clasificación.
Code Python:
de sklearn.ensemble importer AdaBoostClassifier #Pour la classification
de sklearn.ensemble importer AdaBoostRegressor #Pour la régression
depuis sklearn.tree importer DecisionTreeClassifier
dtree = DecisionTreeClassifier ()
cl = AdaBoostClassifier (n_estimateurs = 100, base_estimator = dtree, taux_apprentissage = 1)
cl.fit (xtrain, ytrain)
où:
n_estimateurs et le paramètre learning_rate a le même objectif que dans le cas de l'algorithme Gradient Boosting,
base_estimateur Le paramètre permet de spécifier différents algorithmes d'apprentissage automatique.
3. XGBoost
L'algorithme XGBoost, abreviatura de Extreme Gradient Boosting, C'est simplement une version impromptue du algorithme d'augmentation de gradient, et la procédure de travail des deux est presque la même. Un point crucial dans XGBoost c'est ça Implementa procesamiento paralelo a nivel de nœudNodo est une plateforme digitale qui facilite la mise en relation entre les professionnels et les entreprises à la recherche de talents. Grâce à un système intuitif, Permet aux utilisateurs de créer des profils, Partager des expériences et accéder à des opportunités d’emploi. L’accent mis sur la collaboration et le réseautage fait de Nodo un outil précieux pour ceux qui souhaitent élargir leur réseau professionnel et trouver des projets qui correspondent à leurs compétences et à leurs objectifs...., le rendant plus puissant et plus rapide que l'algorithme d'augmentation de gradient.. XGBoost réduit le surapprentissage et améliore les performances globales a través de la inclusión de varias técnicas de régularisationLa régularisation est un processus administratif qui vise à formaliser la situation de personnes ou d’entités qui opèrent en dehors du cadre légal. Cette procédure est essentielle pour garantir les droits et les devoirs, ainsi que pour promouvoir l’inclusion sociale et économique. Dans de nombreux pays, La régularisation est appliquée dans les contextes migratoires, Droit du travail et fiscalité, permettre aux personnes en situation irrégulière d’accéder à des prestations et de se protéger d’éventuelles sanctions.... a través de el establecimiento de los hiperparámetros del algoritmo XGBoost.
Un point important auquel il faut prêter attention XGBoost c'est ça vous n'avez pas à vous soucier des valeurs manquantes dans l'ensemble de données car, tout au long de la procédure de formation, le modèle lui-même apprend où ajuster les valeurs manquantes, En d'autres termes, le nœud gauche ou le nœud droit.
XGBoost est principalement utilisé pour les problèmes de tri, mais peut être utilisé pour des problèmes de régression.
Code Python:
importer xgboost en tant que xgb
xgb_model = xgb.XGBClassifier (taux_apprentissage = 0,001, profondeur_max = 1, n_estimateurs_100)
xbg_model.fit (x_train, y_train)
NOTES FINALES
Cet article a examiné les algorithmes d'impulsion dans l'apprentissage automatique, a expliqué ce que sont les algorithmes de boost et les types d'algorithmes de boost: Adaboost, Amélioration du gradient et XGBoost. Además miramos sus respectivos códigos y paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... de Python involucrados.
Si vous avez des doutes, vous pouvez me joindre sur mon LinkedIn @Mrinalwalia.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





