Cet article a été publié dans le cadre du Blogathon sur la science des données.
Qu'est-ce qu'un modèle statistique?
“Le mannequinat est un art, ainsi qu'une science, et vise à trouver un bon modèle approximatif … comme base d'inférence statistique” – Burnham & Anderson
Un modèle statistique est un type de modèle mathématique qui fait partie du hypothèses effectué pour décrire le processus de génération de données.
Concentrons-nous sur les deux termes mis en évidence ci-dessus:
- Type de modèle mathématique? Le modèle statistique n'est pas déterministe contrairement à d'autres modèles mathématiques où les variables ont des valeurs spécifiques. Les variables dans les modèles statistiques sont stochastiques, c'est-à-dire, ont des distributions de probabilité.
- Hypothèses? Mais, Comment ces hypothèses nous aident-elles à comprendre les propriétés ou les caractéristiques des vraies données ?? En peu de mots, ces hypothèses facilitent le calcul de la probabilité d'un événement.
Cotisation un exemple pour mieux comprendre le rôle des hypothèses statistiques dans la modélisation des données:
Hypothèse 1: En supposant que nous ayons 2 dés justes et que chaque face a la même probabilité d'apparaître, c'est-à-dire, 1/6. À présent, nous pouvons calculer la probabilité que deux dés montrent 5 Quoi 1/6 * 1/6. Comment pouvons-nous calculer la probabilité de chaque événement, constitue un modèle statistique.
Hypothèse 2: Les dés sont pondérés et tout ce que nous savons, c'est que la probabilité de la face 5 il est 1/8, ce qui facilite le calcul de la probabilité que les deux dés montrent 5 Quoi 1/8 * 1/8. Mais nous ne connaissons pas la probabilité d'autres visages, nous ne pouvons donc pas calculer la probabilité de chaque événement. Pourtant, cette hypothèse ne constitue pas un modèle statistique.
Pourquoi avons-nous besoin d'une modélisation statistique?
Le modèle statistique joue un rôle fondamental dans la réalisation d'inférences statistiques qui aident à faire des propositions sur les propriétés et caractéristiques inconnues de la population, comme indiqué ci-dessous.:
1) Estimation:
C'est l'idée centrale derrière l'apprentissage automatique, c'est-à-dire, trouver le nombre qui peut estimer les paramètres de distribution.
Notez que l'estimateur est une variable aléatoire elle-même, tandis qu'une estimation est un numéro unique qui nous donne une idée de la répartition du processus de génération de données. Par exemple, la moyenne et le sigma de la distribution gaussienne
2) Intervalle de confiance:
Donnez une barre d'erreur autour du numéro d'estimation unique, c'est-à-dire, une plage de valeurs pour indiquer la confiance dans l'estimation obtenue sur la base de plusieurs échantillons. Par exemple, l'estimation A est calculée à partir de 100 échantillons et a un intervalle de confiance plus large, tandis que l'estimation B est calculée à partir de 10000 échantillons et, donc, a un intervalle de confiance plus étroit.
3) Tests d'hypothèses
C'est une déclaration de recherche de preuves statistiques. Comprenons mieux la nécessité d'une modélisation statistique à l'aide d'un exemple ci-dessous.

L'objectif est de comprendre la distribution sous-jacente pour calculer la probabilité qu'un chercheur sélectionné au hasard aurait écrit, Disons, 3 articles de recherche.
On a une variable aléatoire discrète avec 8 (9-1) paramètres à apprendre, c'est-à-dire, probabilité 0,1,2 .. Travail d'enquête. Au fur et à mesure que le nombre de paramètres à estimer augmente, il en va de même de la nécessité d'avoir autant d'observations, mais ce n'est pas le but de la modélisation des données.
Ensuite, on peut réduire le nombre d'inconnues de 8 paramètres à seulement 1 paramètre lambda, en supposant simplement que les données suivent la distribution de Poisson.
Notre hypothèse selon laquelle les données suivent la distribution de Poisson pourrait être une simplification par rapport au processus de génération de données réel, mais c'est une bonne approximation.
Types d'hypothèses de modélisation:
Maintenant que nous comprenons l'importance de la modélisation statistique, comprenons le les types hypothèses de modélisation:
1) Paramétrique: Suppose un ensemble fini de paramètres qui capturent tout ce qui concerne les données. Si nous connaissons le paramètre θ qui incarne très bien le processus de génération de données, puis les prédictions (X) sont indépendants des données observées (ré)
2) en paramétrique: Supposons qu'aucun ensemble fini de paramètres ne puisse définir la distribution des données. La complexité du modèle est illimitée et croît avec la quantité de données
3) Semiparamétrique: C'est un modèle hybride dont les hypothèses se situent entre les approches paramétriques et non paramétriques. Il se compose des composants: de construction (paramétrique) et variation aléatoire (en paramétrique). Le modèle de risque proportionnel de Cox est un exemple populaire d'hypothèses semi-paramétriques.
Définition d'un modèle statistique: (S, P)
S: Supposons que nous ayons une collection de copies N iid comme X1, X2, X3… Xn à travers une expérience statistique (est le processus de génération ou de collecte de données). Tous ceux Les variables aléatoires peuvent être mesurées dans un espace échantillon noté S.
PAG: C'est lui ensemble de distributions de probabilité dans S A contenant la distribution qui est une représentation approximative de notre distribution réelle.
Intériorisons le concept de espace d'échantillon avant de comprendre comment un modèle statistique pourrait être représenté pour ces distributions.
1) Bernoulli: {0,1}
2) Gaussiano: (-??, + ??)
Ensuite, maintenant nous avons vu quelques exemples de l'espace échantillon de certaines des familles de la distribution, Voyons maintenant comment se définit un modèle statistique:
1) Bernoulli: ({0,1}, (Ber (p)) p∈ (0,1))
2) Gaussiano: ((-??, + ??), (N (??, 0.3)) R)
Bon, modèles spécifiés et mal spécifiés:
Quelle est la spécification du modèle? Selon Wikipédia définition:
Modèle Spécification consiste à sélectionner une forme fonctionnelle adaptée au modèle. Par exemple, dé “revenu personnel” (Oui) avec “années de scolarité” (s) Oui “expérience sur le tas” (X), nous pourrions spécifier une relation fonctionnelle y = f (s, X)} comme suit:
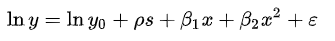
Modèle de spécification incorrect: Vous est-il déjà arrivé que le modèle converge correctement sur des données simulées, mais au moment où les données réelles arrivent, sa robustesse se dégrade et ne converge plus? Bon, cela pourrait se produire normalement si le modèle que vous avez développé ne correspond pas aux données, ce que l'on appelle généralement le modèle de mauvaise spécification. Cela pourrait être dû au fait que la classe de distribution supposée pour la modélisation ne contient pas la distribution de probabilité inconnue p à partir de laquelle l'échantillon est tiré, c'est-à-dire, le vrai processus de génération de données.

La source: Auteur
J'espère que cet article vous a permis de comprendre ce qu'est un modèle statistique, pourquoi nous avons besoin de tels modèles, quel rôle jouent les hypothèses et comment ces hypothèses peuvent-elles décider de la qualité de notre modèle.
*Le processus de diffusion / la génération de données réelles ou réelles mentionnées tout au long de cet article implique qu'il existe une distribution de probabilité induite par le processus qui génère les données observées.
Les références:
https://mc-stan.org/docs/2_22/stan-users-guide/well-specified-models.html
http://mlss.tuebingen.mpg.de/2015/slides/ghahramani/gp-neural-nets15.pdf
https://courses.edx.org/courses/course-v1:MITx+18.6501x+3T2019/course/





