Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
Il existe de nombreuses façons de comparer du texte en Python. Cependant, nous cherchons souvent un moyen facile de comparer du texte. La comparaison de texte est requise à diverses fins d'analyse de texte et de traitement du langage naturel.
L'un des moyens les plus simples de comparer du texte en Python est d'utiliser la bibliothèque fuzzy-wuzzy. Ici, nous obtenons un score de 100, selon la similitude des chaînes. Essentiellement, on nous donne l'indice de similarité. La bibliothèque utilise la distance de Levenshtein pour calculer la différence entre deux chaînes.

Distance de Levenshtein
La distance de Levenshtein est une métrique de chaîne pour calculer la différence entre deux chaînes différentes. Le mathématicien soviétique Vladimir Levenshtein a formulé cette méthode et porte son nom..
La distance de Levenshtein entre deux cordes une, b (de longueur {| une | Oui | b | respectivement) Est donné par lev (une, b) où
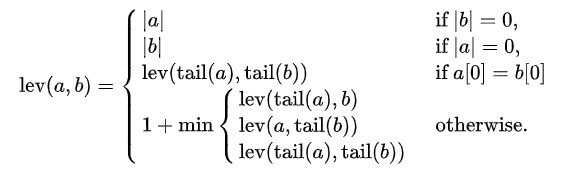
où il Cola d'une corde X est une chaîne de tout sauf le premier caractère de X, Oui X[m] c'est lui Norde caractère de chaîne X en commençant par le personnage 0.
(La source: https://en.wikipedia.org/wiki/Levenshtein_distance)
FuzzyWuzzy
Fuzzy Wuzzy est une bibliothèque open source développée et publiée par SeatGeek. Vous pouvez lire son blog original ici. Mise en œuvre simple et scoring unique (sur 100) metic rend intéressant l'utilisation de FuzzyWuzzy pour la comparaison de texte et a de nombreuses applications.
Installation:
pip installer fuzzywuzzy
pip installer python-Levenshtein
Ce sont les exigences qui doivent être installées.
Commençons maintenant par le code en important les bibliothèques nécessaires.
à partir de l'importation fuzzywuzzy duvet à partir de l'importation fuzzywuzzy traiter
Les importations nécessaires sont effectuées.
#comparaison de chaînes #exactement le même texte duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapport(« Londres est une grande ville., « Londres est une grande ville.)
Départ: 100
Puisque les deux chaînes sont exactement les mêmes ici, on obtient le résultat 100, indiquant des chaînes identiques.
#comparaison de chaînes #pas le même texte duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapport(« Londres est une grande ville., « Londres est une très grande ville.)
Départ: 89
Comment les cordes sont différentes maintenant, le score est 89. Ensuite, nous regardons le travail flou flou.
#faisons maintenant la conversion des cas a1 = "Programme Python" a2 = "PROGRAMME PYTHON" Rapport = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapport(a1.inférieur(),a2.inférieur()) imprimer(Rapport)
Départ: 100
Ici, dans ce cas, bien que les deux chaînes différentes aient eu des cas différents, les deux ont été convertis en minuscules et le score a été 100.
Correspondance de sous-chaîne
À présent, souvent plusieurs cas de correspondance de texte peuvent survenir où nous devons comparer deux chaînes différentes où l'une pourrait être une sous-chaîne de l'autre. Par exemple, nous testons un résumé de texte et nous devons vérifier ses performances. Ensuite, le texte résumé sera une sous-chaîne de la chaîne d'origine. FuzzyWuzzy a des fonctions puissantes pour traiter ces cas.
#fonctions fuzzywuzzy pour travailler avec la correspondance de sous-chaîne b1 = "Le groupe Samsung est un conglomérat multinational sud-coréen dont le siège est à Samsung Town, Séoul." b2 = "Samsung Group est une société sud-coréenne basée à Séoul" Rapport = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapport(b1.inférieur(),b2.inférieur()) Ratio_partiel = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">rapport_partiel(b1.inférieur(),b2.inférieur()) imprimer("Rapport:",Rapport) imprimer("Ratio partiel:",Ratio_partiel)
Production:
Rapport: 64 Ratio partiel: 74
Ici, nous pouvons voir que le score pour la fonction Raison partielle est plus élevé. Cela indique qu'il est capable de reconnaître le fait que la chaîne b2 a des mots de b1.
Ratio de classement des jetons
Mais la méthode de comparaison de sous-chaînes ci-dessus n'est pas infaillible. Souvent, les mots sont mélangés et ne suivent pas un ordre. de la même manière, en cas de condamnations similaires, l'ordre des mots est différent ou mélangé. Dans ce cas, nous utilisons une fonction différente.
c1 = "Téléphone intelligent Samsung Galaxy" c2 = "Téléphone intelligent Samsung Galaxy" Rapport = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapport(c1.inférieur(),c2.inférieur()) Ratio_partiel = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">rapport_partiel(c1.inférieur(),c2.inférieur()) Token_Sort_Ratio = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">jeton_sort_ratio(c1.inférieur(),c2.inférieur()) imprimer("Rapport:",Rapport) imprimer("Ratio partiel:",Ratio_partiel) imprimer("Ratio de tri des jetons:",Token_Sort_Ratio)
Production:
Rapport: 56 Ratio partiel: 60 Ratio de tri des jetons: 100
Ensuite, ici, dans ce cas, nous pouvons voir que les chaînes ne sont que des versions mélangées les unes des autres. Et les deux chaînes montrent le même sentiment et mentionnent également la même entité. La fonction fuzz standard montre que le score entre eux est 56. Et la fonction Token Sort Ratio montre que la similitude est 100.
Ensuite, il est clair que dans certaines situations ou applications, l'index de classement des jetons sera plus utile.
Ratio de jeu de jetons
Mais, maintenant si les deux chaînes ont des longueurs différentes. Les fonctions de relation de classification de jetons peuvent ne pas bien fonctionner dans cette situation. Pour cela, nous avons la fonction Token Set Ratio.
d1 = "Windows est construit par Microsoft Corporation" d2 = "Microsoft Windows" Rapport = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapport(d1.inférieur(),d2.inférieur()) Ratio_partiel = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">rapport_partiel(d1.inférieur(),d2.inférieur()) Token_Sort_Ratio = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">jeton_sort_ratio(d1.inférieur(),d2.inférieur()) Token_Set_Ratio = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">jeton_set_ratio(d1.inférieur(),d2.inférieur()) imprimer("Rapport:",Rapport) imprimer("Ratio partiel:",Ratio_partiel) imprimer("Ratio de tri des jetons:",Token_Sort_Ratio) imprimer("Ratio d'ensemble de jetons:",Token_Set_Ratio)
Production:
Rapport: 41 Ratio partiel: 65 Ratio de tri des jetons: 59 Ratio d'ensemble de jetons: 100
Ah! La note de 100. Bon, la raison en est que la chaîne d2 les composants sont pleinement présents dans la chaîne d1.
À présent, modifions légèrement la chaîne d2.
d1 = "Windows est construit par Microsoft Corporation" d2 = "Microsoft Windows 10" Rapport = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapport(d1.inférieur(),d2.inférieur()) Ratio_partiel = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">rapport_partiel(d1.inférieur(),d2.inférieur()) Token_Sort_Ratio = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">jeton_sort_ratio(d1.inférieur(),d2.inférieur()) Token_Set_Ratio = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">jeton_set_ratio(d1.inférieur(),d2.inférieur()) imprimer("Rapport:",Rapport) imprimer("Ratio partiel:",Ratio_partiel) imprimer("Ratio de tri des jetons:",Token_Sort_Ratio) imprimer("Ratio d'ensemble de jetons:",Token_Set_Ratio)
Pour, modifier légèrement le texte d2 on voit que le score est réduit à 92. C'est parce que le texte "10“Non présent dans la chaîne d1.
WRatio ()
Cette fonctionnalité permet de gérer la capitalisation, minuscule et quelques autres paramètres.
#fuzz.WRatio() imprimer("Légère évolution des cas:",duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio('Ferrari LaFerrari', 'FerrarI LAFerrari'))
Production:
Légère évolution des cas: 100
Essayons de supprimer un espace.
#fuzz.WRatio() imprimer("Légèrement changement d'étuis et un espace supprimé:",duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio('Ferrari LaFerrari', 'FerrarILAFerrari'))
Production:
Légèrement changement d'étuis et un espace supprimé: 97
Essayons quelques signes de ponctuation.
#gérer des ponctuations aléatoires g1='Microsoft Windows est bon, mais prend lof de ram!!!' g2='Microsoft Windows est bon mais prend beaucoup de RAM?' imprimer(duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio(g1,g2 ))
Départ: 99
Donc, nous pouvons voir que FuzzyWuzzy a beaucoup de fonctions intéressantes qui peuvent être utilisées pour effectuer des tâches de comparaison de texte intéressantes.
Quelques applications adaptées:
FuzzyWuzzy peut avoir des applications intéressantes.
Peut être utilisé pour évaluer des résumés de texte plus longs et juger de leur similitude. Cela peut être utilisé pour mesurer la performance des résumés de texte.
Selon la similitude des textes, peut également être utilisé pour identifier l'authenticité d'un texte, Article, Nouvelles, livre, etc. Souvent, on trouve plusieurs textes / données incorrectes. Souvent, impossible de vérifier toutes les données textuelles. Utiliser la similitude de texte, le recoupement de plusieurs textes peut être effectué.
FuzzyWuzzy peut aussi être utile pour sélectionner le meilleur texte similaire parmi plusieurs textes. Ensuite, Les applications de FuzzyWuzzy sont nombreuses.
La similarité de texte est une mesure importante qui peut être utilisée à diverses fins de PNL et d'analyse de texte.. La chose intéressante à propos de FuzzyWuzzy est que les similitudes sont données comme un score de 100. Cela permet un score relatif et génère également une nouvelle caractéristique / données pouvant être utilisées à des fins analytiques / ML.
Similitude sommaire:
#utilisations de fuzzy wuzzy #similitude résumée Texte de saisie="L'analyse de texte implique l'utilisation de données textuelles non structurées, les transformer en données structurées exploitables. L'analyse de texte est une application intéressante du traitement du langage naturel. Text Analytics a divers processus, y compris le nettoyage du texte, suppression des mots vides, calcul de la fréquence des mots, et beaucoup plus. L'analyse de texte a pris beaucoup d'importance ces jours-ci. Alors que des millions de personnes s'engagent sur des plateformes en ligne et communiquent entre elles, une grande quantité de données textuelles est générée. Les données textuelles peuvent être des blogs, publications sur les réseaux sociaux, tweets, avis sur les produits, enquêtes, forums de discussion, et beaucoup plus. Ces énormes quantités de données créent d'énormes données textuelles que les organisations peuvent utiliser. La plupart des données textuelles disponibles sont non structurées et dispersées. L'analyse de texte est utilisée pour collecter et traiter cette grande quantité d'informations afin d'obtenir des informations. L'analyse de texte sert de base à de nombreuses tâches avancées de PNL telles que la classification, Catégorisation, Analyse des sentiments, et beaucoup plus. Text Analytics est utilisé pour comprendre les modèles et les tendances des données textuelles. Mots clés, les sujets, et les fonctionnalités importantes de Text sont trouvées à l'aide de Text Analytics. Il existe de nombreux aspects plus intéressants de l'analyse de texte, Passons maintenant à notre ensemble de données de CV. L'ensemble de données contient du texte provenant de divers types de CV et peut être utilisé pour comprendre ce que les gens utilisent principalement dans les CV. Resume Text Analytics est souvent utilisé par les recruteurs pour comprendre le profil des candidats et filtrer les candidatures. Recruter pour des emplois est devenu une tâche difficile de nos jours, avec un grand nombre de candidats à l'emploi. Les responsables des ressources humaines utilisent souvent divers outils de traitement de texte et de lecture de fichiers pour comprendre les curriculum vitae envoyés. Ici, nous travaillons avec un exemple d'ensemble de données de CV, qui contient le texte du curriculum vitae et la catégorie de curriculum vitae. Nous allons lire les données, nettoyez-le et essayez d'obtenir des informations à partir des données."
Ce qui précède est le texte original.
texte_sortie="L'analyse de texte implique l'utilisation de données textuelles non structurées, les transformer en données structurées exploitables. L'analyse de texte est une application intéressante du traitement du langage naturel. Text Analytics a divers processus, y compris le nettoyage du texte, suppression des mots vides, calcul de la fréquence des mots, et beaucoup plus. Text Analytics est utilisé pour comprendre les modèles et les tendances des données textuelles. Mots clés, les sujets, et les fonctionnalités importantes de Text sont trouvées à l'aide de Text Analytics. Il existe de nombreux aspects plus intéressants de l'analyse de texte, Passons maintenant à notre ensemble de données de CV. L'ensemble de données contient du texte provenant de divers types de CV et peut être utilisé pour comprendre ce que les gens utilisent principalement dans les CV."
Rapport = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapport(Texte de saisie.inférieur(),texte_sortie.inférieur()) Ratio_partiel = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">rapport_partiel(Texte de saisie.inférieur(),texte_sortie.inférieur()) Token_Sort_Ratio = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">jeton_sort_ratio(Texte de saisie.inférieur(),texte_sortie.inférieur()) Token_Set_Ratio = duvet.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">jeton_set_ratio(Texte de saisie.inférieur(),texte_sortie.inférieur()) imprimer("Rapport:",Rapport) imprimer("Ratio partiel:",Ratio_partiel) imprimer("Ratio de tri des jetons:",Token_Sort_Ratio) imprimer("Ratio d'ensemble de jetons:",Token_Set_Ratio)
Production:
Rapport: 54 Ratio partiel: 79 Ratio de tri des jetons: 54 Ratio d'ensemble de jetons: 100
On voit les différents scores. La relation partielle montre qu'ils sont assez similaires, ce qui devrait être le cas. En outre, la proportion de l'ensemble de jetons est 100, ce qui est évident puisque le résumé est entièrement tiré du texte original.
Meilleure correspondance de chaîne possible:
Utilisons la bibliothèque de processus pour trouver la meilleure correspondance de chaîne possible entre une liste de chaînes.
#choisir la correspondance de chaîne possible #utilisation de la bibliothèque de processus mettre en doute = 'Débordement de pile' les choix = [« Frais généraux de stock », « Pile débordante », 'S. Débordement',"Débordement de la pile"] imprimer("Liste des ratios: ") imprimer(traiter.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.process.extract'}, '*')">extrait(mettre en doute, les choix)) imprimer("Meilleur choix: ",traiter.<un onclick="parent.postMessage({'référent':'.fuzzywuzzy.process.extractOne'}, '*')">extraireUn(mettre en doute, les choix))
Production:
Liste des ratios:
[('Stoack Overflow', 97), (« Pile débordante », 90), ('S. Débordement', 85), (« Frais généraux de stock », 64)]
Meilleur choix: ('Stoack Overflow', 97)
Donc, les scores de similarité et la meilleure correspondance sont donnés.
Derniers mots
La bibliothèque FuzzyWuzzy s'appuie sur la bibliothèque difflib. Et python-Levenshtein utilisé pour optimiser la vitesse. On peut donc comprendre que FuzzyWuzzy est l'un des meilleurs moyens de comparer des chaînes en Python.
Vérifiez le code dans Kaggle ici.
Sur moi:
Prateek Majumder
Science des données et analyse | Spécialiste du marketing numérique | Référencement | Création de contenu
Connectez-vous avec moi sur Linkedin.
Mes autres articles sur DataPeaker: Relier.
Merci.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





