introduction
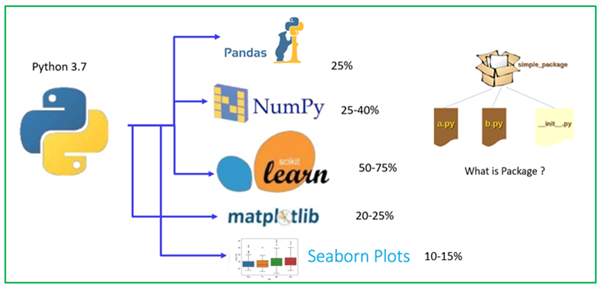
Surtout les bibliothèques Python pour la science des données, les modèles d'apprentissage automatique sont très intéressants, facile à comprendre et absolument que vous pouvez appliquer immédiatement et ressentir les informations des données et réaliser / visualiser la nature du jeu de données.
Même des algorithmes complexes peuvent être implémentés en deux ou trois lignes de code, tous les principaux concepts mathématiques sont intégrés dans les packages pour le point de vue de la mise en œuvre.
Bien sûr, c'est quelque chose de différent et d'intéressant que les autres bibliothèques de programmation que j'ai vues jusqu'à présent, C'est la principale raison pour laquelle Python joue un rôle vital dans l'espace de l'IA avec cette simplicité et cette robustesse !! Je crois que oui! Je me suis rendu compte, J'ai bien compris et j'ai apprécié.
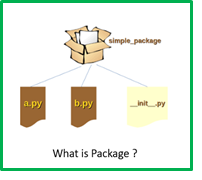
Qu'est-ce qu'un paquet en Python? UNE emballer est une collection de Piton modules et assemblages dans un seul paquet. Une fois que vous avez importé dans les cellules de votre bloc-notes, peut commencer à utiliser les cours, méthodes, les attributs, etc., mais avant ça, vous devriez avoir besoin et utiliser le package et l'importer dans votre archive / emballer.
Examinons les principaux packages Python pour la science des données et l'apprentissage automatique.
- Pandas
- NumPy
- Apprendre Scikit
- Matplotlib
- Seaborn
Pandas

Utilisé principalement pour les manipulations et opérations de données structurées. Pandas offre de puissantes capacités de traitement de données, Je n'ai jamais vu des fonctionnalités aussi merveilleuses dans mon parcours informatique. Fournit des performances élevées, facile à utiliser et appliqué dans les structures de données et pour analyser les données.
Comment pourriez-vous installer la bibliothèque Pandas? c'est très simple, exécutez la commande suivante sur votre Jupiter Notebook.
!pip installer des pandas
La bibliothèque Pandas s'installera avec succès !! Suivant? jouer avec cette bibliothèque.
La syntaxe pour importer Scikit dans votre Notebook
importer des pandas au format pd
Ensuite, votre ordinateur portable est prêt à extraire toutes les fonctions des pandas. faisons des choses ici.
Les pandas ont les capacités suivantes.
UNE) Série et DataFrame
Les principaux composants des pandas sont Série Oui Trame de données. Jetons un coup d'œil rapide à cela.. La série n'est rien de plus qu'un dictionnaire et une collection de séries, nous pourrions construire le bloc de données en fusionnant des séries, jetez un oeil à l'exemple suivant. tu comprendrais mieux.
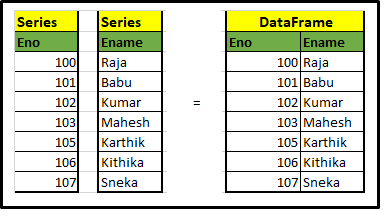
Le code crée des séries et des blocs de données
importer des pandas au format pd
Éno=[100, 101,102, 103, 104,105]
Nom d'utilisateur= ['Raja', 'Babou', 'Kumar','Karthik','Rajesh','xxxxx']
Eno_Series = pd.Series(Là)
Empname_Series = pd.Series(Nom d'utilisateur)
df = { 'Eno': Eno_Série, 'Empnom': Nom_Emp_Série }
employé = pd.DataFrame(Cadre)
employé

B. Charger des données dans un objet de bloc de données
cereal_df = pd.read_csv("céréales.csv")
cereal_df.head(5)

C. Supprimer la colonne de l'objet de bloc de données
cereal_df.drop(["taper"], axe = 1, en place = vrai)
cereal_df.head(5)

ré. Sélectionnez les lignes de l'objet de bloc de données
cereal_df_filtered = cereal_df[céréales_df['évaluation'] >= 68] cereal_df_filtered.head()
E. Colonne de groupe dans le bloc de données
cereal_df_groupby = cereal_df.groupby('étagère')
#imprimer les premières entrées cereal_df_groupby.first()

F. Extraire une ligne du bloc de données
# retourner la valeur result = cereal_df.loc[0,'Nom'] résultat
Jusqu'à maintenant, nous avons discuté des multiples fonctionnalités de la bibliothèque pandas. Il y en a beaucoup plus.
NumPy
NumPy est considéré comme l'une des bibliothèques d'apprentissage automatique les plus populaires en Python, la meilleure et la plus importante caractéristique de NumPy est l'interface et les manipulations de tableaux.
Peur des mathématiques lors de la mise en œuvre de votre modèle de science des données / apprentissage automatique? Ne t'inquiète pas, NumPy rend les implémentations mathématiques complexes des fonctions très simples. Mais n'oubliez pas de comprendre les exigences et d'utiliser le package en conséquence.
La syntaxe pour importer NumPy dans votre Notebook
importer numpy en tant que np
Décomposons quelques choses ici, comment NumPy fonctionne comme par magie avec des données données.
UNE. Formation de matrice simple à l'aide de NumPy (1-ré, 2-Jour 3D)
importer numpy en tant que np
Tableaux #1-D
arr1 = np.tableau([1, 2, 3, 4, 5])
imprimer("1-Tableau D")
imprimer(arr1)
imprimer("====================")
#2-tableaux D
imprimer("2-Tableau D")
arr2 = np.tableau([[1, 2, 3], [4, 5, 6]])
imprimer(arr2)
imprimer("====================")
#3-tableaux D
imprimer("3-Tableau D")
arr3 = np.tableau([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]])
imprimer(arr3)
imprimer("====================")
Production
1-Tableau D [1 2 3 4 5] ==================== Tableau 2D [[1 2 3] [4 5 6]] ==================== Tableau 3D [[[1 2 3] [4 5 6]] [[1 2 3] [4 5 6]]] ====================
B. Array Slicing usando NumPy
#Trancher en python signifie prendre des éléments d'une plage d'index donnée [début:fin-1] /[début:finir:étape].
arr = np.tableau([1, 2, 3, 4, 5, 6, 7])
imprimer("Tranchage à l'index 1 à 5")
imprimer(arr[1:5])
Production
Tranchage à l'index 1 à 5 [2 3 4 5]
arr = np.tableau([1, 2, 3, 4, 5, 6, 7]) imprimer(arr[4:]) Sortir [5 6 7]
Nous avons également le tranchage négatif :). C'est si simple, nous n'avons qu'à mentionner [-X:-Oui],
Pourquoi n'essayes-tu pas le tien?
C. Mise en forme et remodelage matriciel à l'aide de NumPy
arr = np.tableau([[1, 2, 3, 4], [5, 6, 7, 8]])
imprimer("================================")
imprimer("Forme du tableau")
imprimer(arr.forme)
imprimer("================================")
Sortir
================================
Forme du tableau
(2, 4)
================================
arr = np.tableau([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
imprimer("Avant de remodeler le tableau")
imprimer(arr)
imprimer("================================")
newarr = arr.remodeler(4, 3)
imprimer("Après remodeler le tableau")
imprimer(nouveau)
imprimer("================================")
sortir
Avant de remodeler le tableau
[ 1 2 3 4 5 6 7 8 9 10 11 12]
================================
Après remodeler le tableau
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
================================
ré. Division de tableau à l'aide de NumPy
arr = np.tableau([1, 2, 3, 4, 5, 6])
imprimer("Diviser les tableaux NumPy en 3 Tableaux")
imprimer("================================")
newarr = np.array_split(arr, 3)
imprimer(nouveau[0])
imprimer(nouveau[1])
imprimer(nouveau[2])
imprimer("================================")
sortir
Diviser les tableaux NumPy en 3 Tableaux
================================
[1 2]
[3 4]
[5 6]
Tableau E.Sorting à l'aide de NumPy
arr = np.tableau(['banane', 'cerise', 'Pomme'])
imprimer("Diviser les tableaux NumPy en 3 Tableaux")
imprimer("================================")
imprimer(np.sort(arr))
imprimer("================================")
sortir
Diviser les tableaux NumPy en 3 Tableaux
================================
['pomme' 'banane' 'cerise']
================================
Si vous avez commencé à jouer avec des données en utilisant NumPy....
Certainement, a besoin de plus en plus de temps … comprendre les notions, tous sont
extrêmement organisé dans ce paquet. croyez-moi!
Apprendre Scikit

Scikit La bibliothèque Learn est l'une des bibliothèques les plus riches de la famille Python, contient un grand nombre d'algorithmes d'apprentissage automatique et d'autres bibliothèques clés liées aux performances. Python Scikit-learn permet aux utilisateurs d'effectuer diverses tâches d'apprentissage automatique spécifiques. Travailler, devrait fonctionner avec les bibliothèques SciPy et NumPy, c'est quelque chose d'interne, de toute façon, Garde le en mémoire. Quelques algorithmes ici pour vos avis.
- Régression
- Classification
- Regroupement
- Sélection du modèle
- Réduction de la dimensionnalité
La syntaxe pour importer Scikit dans votre Notebook
à partir de sklearn.linear_model importer LinearRegression de sklearn.model_selection importer train_test_split
Paquets d'affichage Python
Bibliothèques Matplotlib et Seaborn

Python fournit des fonctions graphiques 2D avec la bibliothèque Matplotlib. c'est très simple et facile à comprendre. vous pouvez y parvenir avec 1 O 2 lignes. Même la visualisation 3D est là aussi.
La syntaxe pour importer Scikit dans votre notebook
importer matplotlib.pyplot en tant que plt importer seaborn comme sns
J'espère que vous avez travaillé sur divers graphiques dans une feuille de calcul Excel et d'autres outils de BI. Mais en python, les packages de visualisation internes fournissent des graphiques et des tableaux de très haute qualité.
Matplotlib et Seaborn
Matplotlib est l'un des packages de visualisation principaux et de base, qui fournit des histogrammes (Niveau de fréquence), Graphique à barres (Tracé univarié et bivarié), Nuage de points (Regroupement), etc.,
Bibliothèque de visualisation de données riche et luxueuse de Seaborn. Fournit une interface de haut niveau pour dessiner des graphiques statistiques attrayants et informatifs. Boîtes à moustaches (Diffusion des données avec des quartiles différents), Complots de violon (Diffusion des données Oui Densité de probabilité), Diagramme à barres (Comparaisons entre caractéristiques catégorielles), Carte de chaleur (Cartographie des caractéristiques en termes de représentation matricielle), Mot nuage (Représentation visuelle des données textuelles)
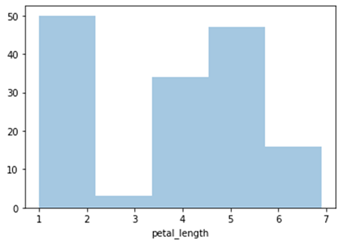
Seaborn – Histogramme
importer seaborn en tant que qn
de matplotlib importer pyplot en tant que plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],kde = Faux)
plt.show()
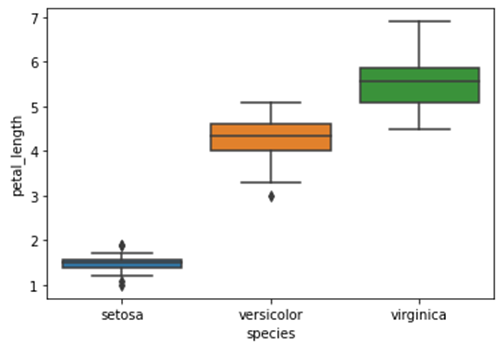
Seaborn – Box plot
df = sb.load_dataset('iris')
sb.boxplot(x = "espèce", y = "longueur_pétale", données = df)
plt.show()
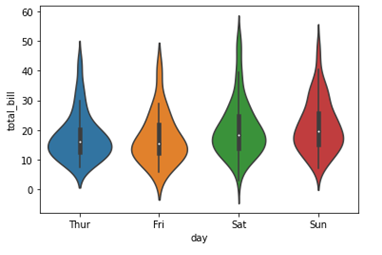
Seaborn – intrigue pour violon
sdf = sb.load_dataset('des astuces')
sb.violinplot(x = "journée", y = "Facture totale", données=df)
plt.show()
Ensuite, Toutes ces bibliothèques nous aident à construire un bon modèle et à jouer avec les données !!
Mais souviens-toi toujours, avant d'utiliser les packages induvial, vous devez comprendre le besoin et les exigences du package, puis l'importer dans votre archive / emballer et jouer avec.

J'espère que vous avez maintenant le sentiment et un certain niveau de détail sur les packages Python pour la science des données. Nous verrons des concepts plus détaillés dans les prochains jours !! Merci pour ton temps!
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





