introduction
Python es uno de los lenguajes más queridos en el mundo de la ciencia de datos y el aprendizaje automático. Es fácil de aprender y proporciona un montón de bibliotecas y paquetes y tiene una buena comunidad de desarrolladores. Las bibliotecas y paquetes de Python son un grupo de módulos que nos hace la vida más fácil. Il y a plus de 137,000 bibliotecas de Python y 198,826 paquetes de Python preparados para facilitar la experiencia de programación ordinaria de los ingenieros. Estas bibliotecas y paquetes están planificados para una variedad de arreglos avanzados.
Como entusiasta de la ciencia de datos, he visto personas que siempre hablan de algunas bibliotecas famosas como pandas de manipulación de datos y NumPy, para visualización de datos matplotlib, marin, plotly y muchas más, para modelar scikit-learn, TensorFlow, etc. En este artículo No voy a cubrir estas bibliotecas porque ya hay toneladas de blogs disponibles, consulte mi artículo sobre las bibliotecas de Python más utilizadas aquí. Pero en su artículo, voy a cubrir algunas gemas ocultas de bibliotecas de Python que son desconocidas para el mundo de la ciencia de datos. Estas son algunas bibliotecas importantes que puede consultar en 2021.

Estas bibliotecas incluyen funcionalidades como manejar valores perdidos de una manera organizada, manejar emojis, convertir números en ints y floats, herramientas de inteligencia de visualización, modelado de series de tiempo y muchos más. Cubre una amplia gama de temas, desde el procesamiento del lenguaje natural hasta la visualización de datos y las series de tiempo. Alors commençons.
Table des matières
- Missingo
- Emot
- Bamboolib
- ppscore
- AutoViz
- Numerador
- PyFlux
- Texto Flash
Missingo
Los conjuntos de datos del mundo real generalmente contienen muchos valores faltantes y nulos. Cela peut être dû à un certain nombre de raisons, como la fuga de datos, los datos no están disponibles, etc. Parfois, es muy irritante lidiar con este tipo de datos desordenados. Estos datos desordenados requieren una atención especial antes de introducirlos en los algoritmos de aprendizaje automático, ya que estos algoritmos no manejan los valores perdidos.
Necesitamos un mejor enfoque para manejar estos valores perdidos. Aquí viene la magia de la biblioteca de Python llamada disparu. Nos ayuda a to lidiar con los valores perdidos con la ayuda de visualizaciones de datos de una manera mucho mejor. Esto se basa en matplotlib. A partir d'avril 2021, tiene cuatro tipos de gráficos para comprender la distribución de los datos faltantes, a savoir, le graphique à barres. carte de chaleur, matriz y dendrograma. Alors commençons.
Installation
pip install missingo
Importando la biblioteca
import missingo as msns
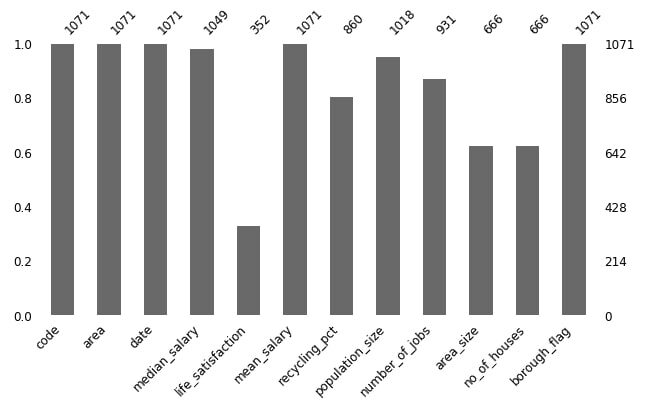
En el gráfico de barras a continuación, puede ver el número de valores perdidos en cada columna:
Pour plus d'informations, consulter la documentation officielle: Relier
Emot
Los emojis son muy comunes en los chats. Cuando se trata de tareas de procesamiento del lenguaje natural, es muy tedioso tratar con emojis. Aquí viene una biblioteca muy útil para deshacerse de los emoticonos de los datos de texto. Es una famosa biblioteca de Python que es muy útil cuando tenemos que lidiar con Emoji y Emoticonos. Funciona bien con Python 2 et Python 3. Toma una cadena como entrada y devuelve una lista del diccionario. Alors commençons.
Installation
pip install emot
Importando la biblioteca
import emot
Code
import emot text = "I love python 👨 :-)" emot.emoji(texte) [{'valeur': '👨', 'moyenne': ':man:', 'emplacement': [14, 14], 'drapeau': Vrai}] emot.emoticons(texte) {'valeur': [':-)'], 'emplacement': [[16, 19]], 'moyenne': ['Happy face smiley'], 'drapeau': Vrai}

Pour plus d'informations, consulter la documentation officielle: Relier
Bamboolib
Analizar y visualizar la información es la interacción más significativa y que requiere más tiempo. Necesitamos dedicar mucho tiempo a investigar inequívocamente cuál es el problema aquí y qué está intentando decir. Utilizamos varios tipos de bibliotecas de Python para visualizar los ejemplos y rarezas en el conjunto de datos para sentirnos cómodos con el conjunto de datos.
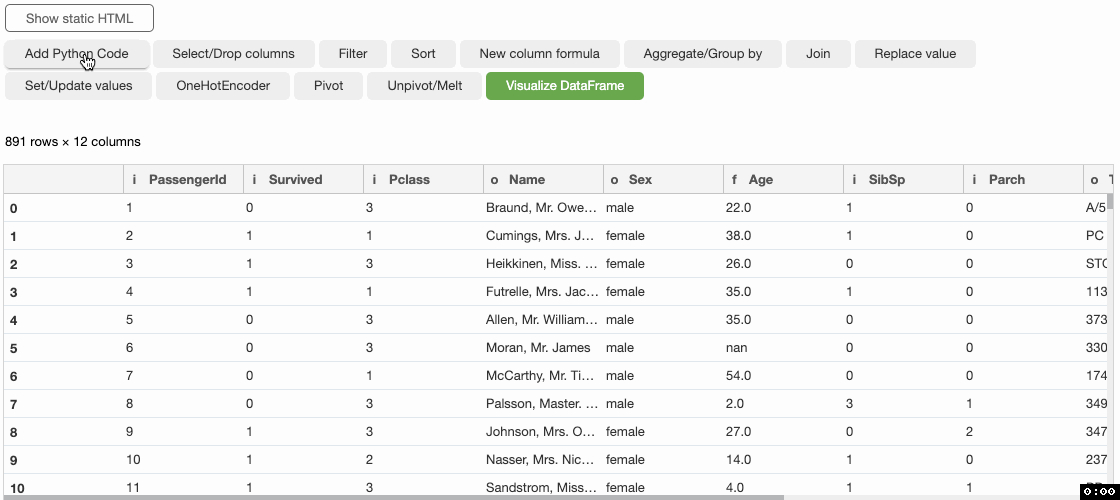
Bamboolib es GUI para pandas DataFrames que permite a cualquiera trabajar con python en Jupyter Notebook o JupyterLab. Bamboolib es una biblioteca profundamente inteligente y de amplio apoyo para examinar, imaginar y controlar información.
En réalité, incluso una persona sin una base de programación puede utilizarlo para extraer fragmentos de conocimiento de la información, car no necesita experiencia en codificación. Bamboolib no es de código abierto, lo que implica que debe comprar bamboolib para utilizarlo, pero ofrece un formulario preliminar gratuito de 14 días para que pueda investigarlo por completo y percibir cómo puede ser muy valioso para usted.
Installation
pip install bamboolib
Importando la biblioteca
import bamboolib

Pour plus d'informations, consulter la documentation officielle: Relier
Ppscore
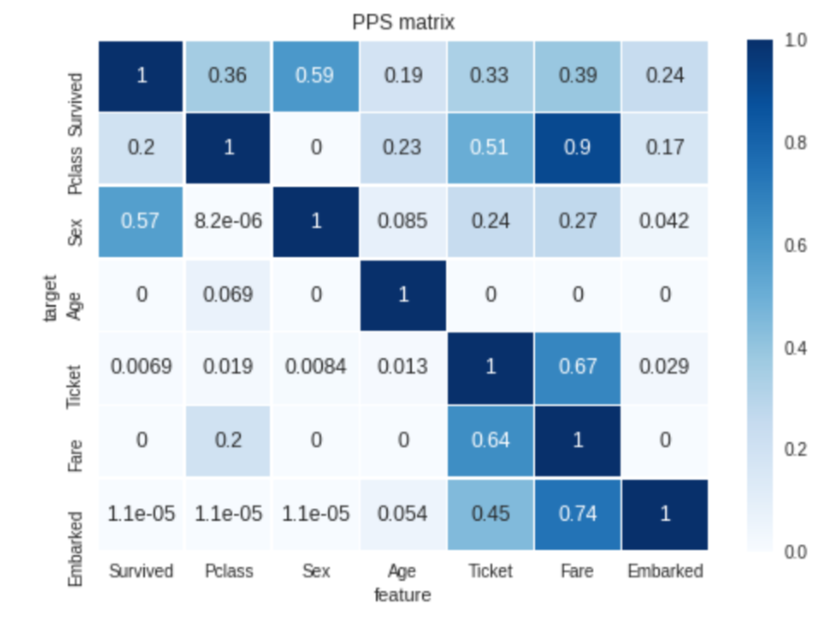
Completo de ppscore es Predictive Power Score. Esta biblioteca de Python está hecha por desarrolladores de bamboolib. El Predictive Power Score es una alternativa a la matriz de correlación. Esta puntuación es asimétrica y puede detectar las relaciones lineales o no lineales entre dos columnas dans notre jeu de données. Así que comencemos con esta biblioteca.
Installation
pip install ppscore
Importando la biblioteca
import ppscore
Pour plus d'informations, consulter la documentation officielle: Relier
AutoViz
Es la biblioteca de Python más subestimada que se ha utilizado à realizar análisis de datos exploratorios. Esta biblioteca visualiza automáticamente cualquier tipo de conjunto de datos, incluidos también grandes conjuntos de datos. Hermosa Las visualizaciones se pueden dibujar con un solo código.. Solo debes proporcionar tu archivo de datos (SMS, JSON ou CSV) y automáticamente lo visualizará. Simplemente cargue sus datos y AutoViz le proporcionará automáticamente los gráficos correctos que le ayudarán a obtener información en cuestión de segundos. Alors commençons.

Installation
pip installer autoviz
Importando la biblioteca
import autoviz
Pour plus d'informations, consulter la documentation officielle: Relier
Numerador
Es un módulo de Python muy interesante para el procesamiento de texto. Ce convierte los números del lenguaje natural en flotantes e ints. Este es un módulo muy útil en tareas de procesamiento de lenguaje natural. À
Exemple, si convierte ‘cuarenta y dos’ dans 42, ‘mil millones y uno’ dans 1000000001
etc. Alors, commençons.
Installation
pip install numerizer
Importando la biblioteca
from numerizer import numerize
Code
numerize(‘forty-two’) '42' numerize('one billion and one') '1000000001'
Pour plus d'informations, consulter la documentation officielle: Relier
PyFlux
La investigación de series de tiempo es posiblemente el problema más frecuentemente experimentado en el área de aprendizaje automático. PyFlux es una biblioteca de código abierto en Python que funcionó inequívocamente para trabajar con problemas de series de tiempo. La biblioteca tiene un grupo brillante de modelos de disposición de tiempo actuales que incluyen, pero no se restringen a los modelos ARIMA, GARCH y VAR. Donc, PyFlux ofrece una forma probabilística de lidiar con la visualización de la disposición del tiempo. Alors commençons.
Installation
pip install pyflux
Importando la biblioteca
import pyflux
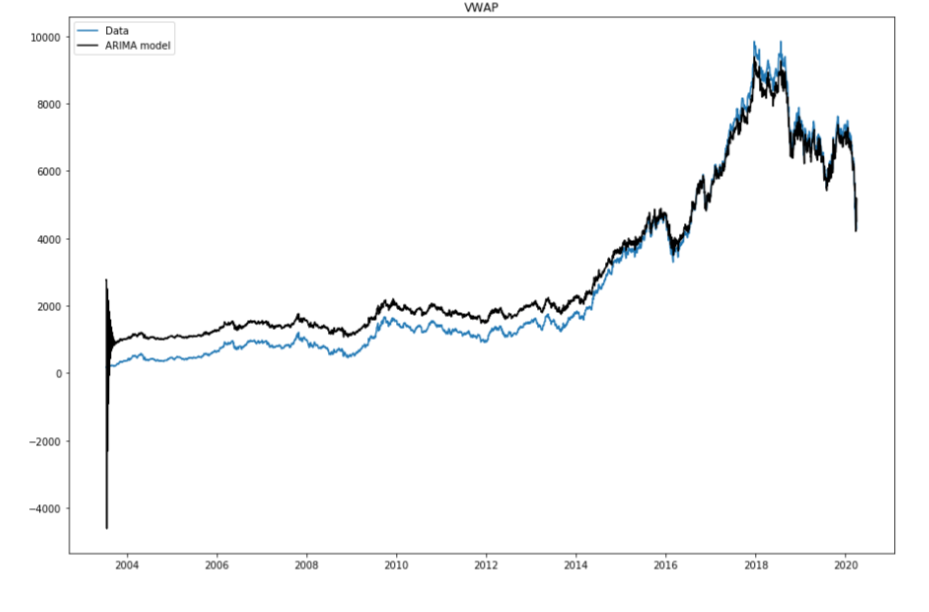
Pour plus d'informations, consulter la documentation officielle: Relier
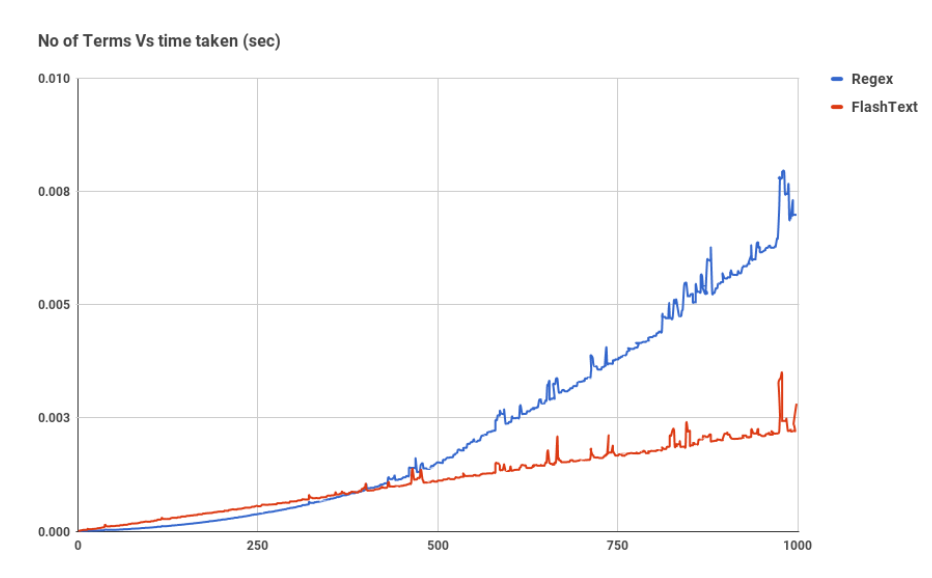
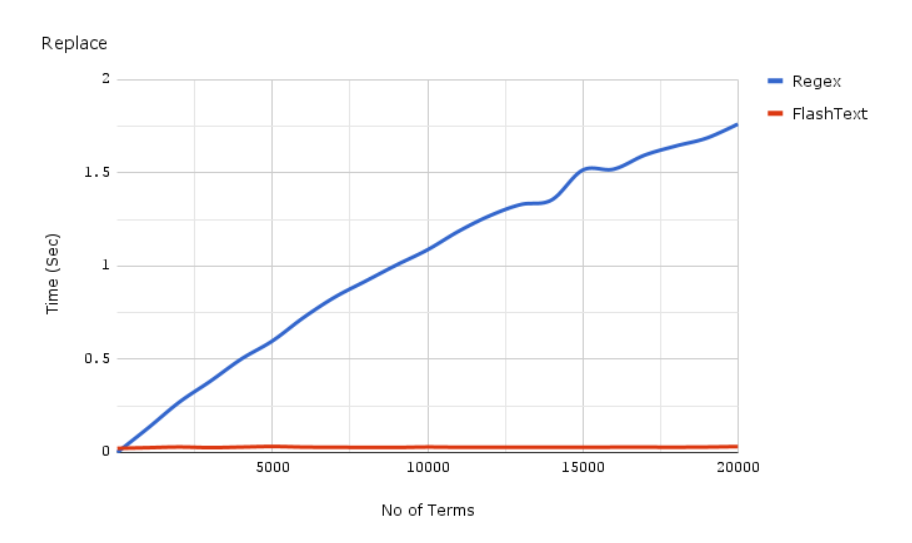
FlashText
FlashText es una biblioteca de Python hecha explícitamente buscar en la sustitución de las palabras en un registro. Actuellement, el funcionamiento de FlashText es que requiere una palabra o un resumen de palabras y una cadena. Las palabras que FlashText llama palabras clave se examinan o reemplazan en la cadena.
Permítanos ver información sobre el funcionamiento de FlashText. En el momento en que las palabras clave se pasan a FlashText para buscar o suplantar, se guardan como una estructura de datos Trie que es productiva en las asignaciones de recuperación. Alors commençons.
Installation
pip install flashtext
Importando la biblioteca
import flashtext
Buscando:
Remplacement:
Pour plus d'informations, consulter la documentation officielle: Relier
Note finale
Vous pouvez consulter mes articles ici: Des articles
Merci d'avoir lu cet article et de votre patience.. Laissez-moi dans la section commentaire sur les commentaires. Partagez cet article, cela me donnera la motivation d'écrire plus de blogs pour la communauté de la science des données.
Identification de l'e-mail: gakshay1210@ gmail.com
Suivez-moi sur LinkedIn: LinkedIn
Los medios que se muestran en este artículo sobre los paquetes de Python no son propiedad de DataPeaker y se utilizan a discreción del autor.





