Vue d'ensemble
- Comprenda el significado de particionar y agrupar en RucheHive es una plataforma de redes sociales descentralizada que permite a sus usuarios compartir contenido y conectar con otros sin la intervención de una autoridad central. Utiliza tecnología blockchain para garantizar la seguridad y la propiedad de los datos. A diferencia de otras redes sociales, Hive permite a los usuarios monetizar su contenido a través de recompensas en criptomonedas, lo que fomenta la creación y el intercambio activo de información.... en détail.
- Nous verrons, comment créer des partitions et des cubes sur la ruche.
introduction
Vous avez peut-être vu une encyclopédie dans votre bibliothèque scolaire ou universitaire. C'est un ensemble de livres qui vous donnera des informations sur presque tout. Savez-vous quel est le meilleur de l'encyclopédie?

Oui, tu l'as bien deviné. Les mots sont classés par ordre alphabétique. Par exemple, a un mot en tête « Pyramides ». Vous irez directement chercher le livre avec le titre "P". Tu n'as pas à chercher ça dans d'autres livres. Pouvez-vous imaginer à quel point la tâche de rechercher un seul livre serait difficile s'ils étaient rangés dans le désordre?
Ici, stocker les mots par ordre alphabétique représente l'indexation, pero el uso de una ubicación diferente para las palabras que comienzan con el mismo carácter se conoce como regroupementLe "regroupement" Il s’agit d’un concept qui fait référence à l’organisation d’éléments ou d’individus en groupes ayant des caractéristiques ou des objectifs communs. Ce procédé est utilisé dans diverses disciplines, y compris la psychologie, Éducation et biologie, faciliter l’analyse et la compréhension de comportements ou de phénomènes. Dans le domaine de l’éducation, par exemple, Le regroupement peut améliorer l’interaction et l’apprentissage entre les élèves en encourageant le travail...
Il existe des types similaires de techniques de stockage, en tant que partitions et groupements, dans Ruche Apache afin que nous puissions obtenir des résultats plus rapides pour les requêtes de recherche. Dans cet article, nous verrons ce qu'est la partition et le regroupement, et quand utiliser qui.
Table des matières
- Qu'est-ce que le partitionnement?
- Quand utiliser le partitionnement?
- Qu'est-ce que le regroupement?
- Quand utiliser le regroupement?
Qu'est-ce que le partitionnement?
Apache Hive nous permet d'organiser la table en plusieurs partitions où nous pouvons regrouper le même type de données. Utilisé pour répartir la charge horizontalement. Comprenons avec un exemple:
Supposons que nous devions créer un tableau dans la ruche contenant les détails du produit pour une entreprise de commerce électronique de mode. Il a les colonnes suivantes:
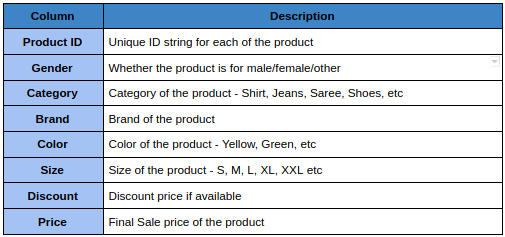
À présent, le premier filtre que la plupart des clients utilisent est Sexe, puis sélectionnez des catégories comme Chemise, sa taille et sa couleur. Voyons comment créer les partitions pour cet exemple.
CRÉER TABLE produits ( chaîne product_id,
chaîne de marque,
chaîne de taille,
flotteur,
prix flottant )
PARTITIONNÉ PAR (chaîne de genre,
chaîne de catégorie,
chaîne de couleur);
À présent, la ruche stockera les données dans la structure de répertoire comme:
/user/hive/warehouse/mytable/gender=male/category=shoes/color=black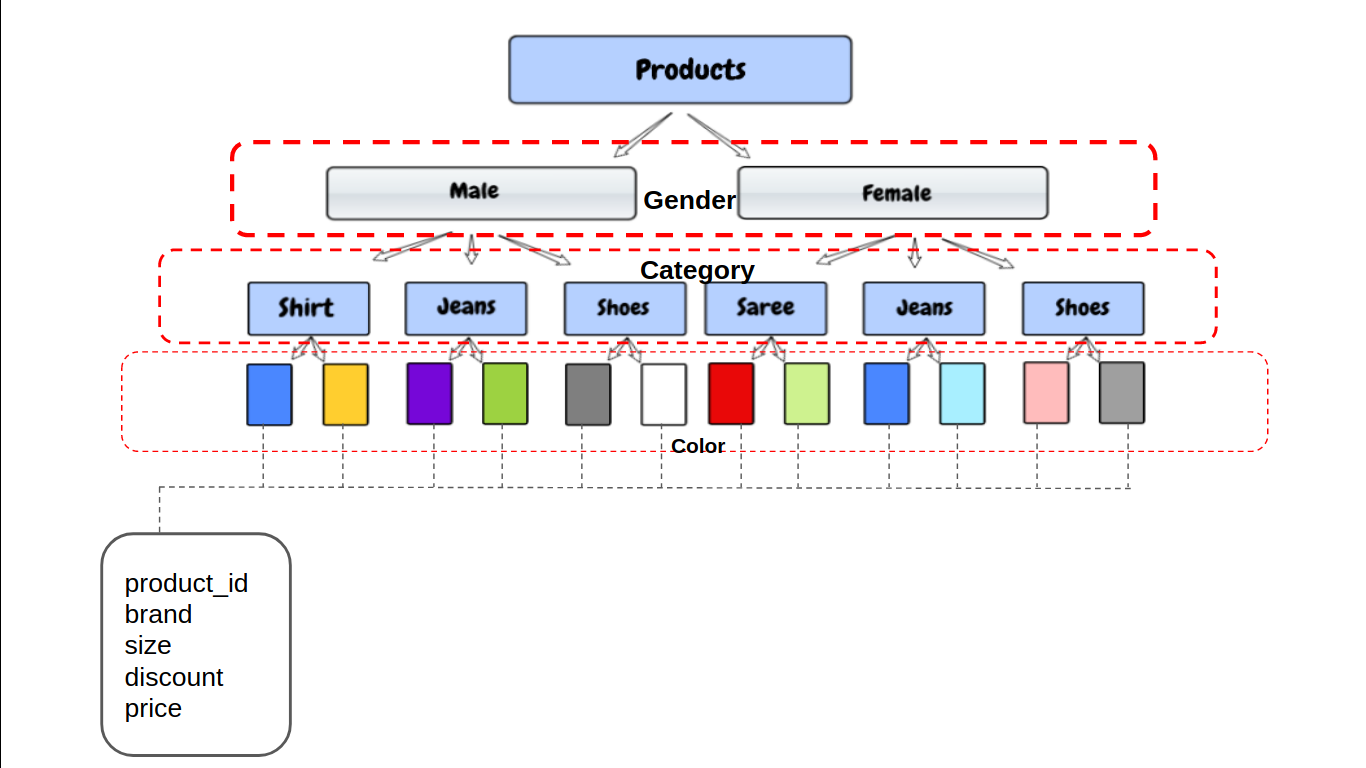
Le partitionnement des données nous offre des avantages en termes de performances et nous aide également à organiser les données. À présent, Voyons quand utiliser la partition dans Hive.
Quand utiliser le partitionnement?
- Lorsque la colonne avec une requête de recherche élevée a une faible cardinalité. Par exemple, si vous créez une partition avec le nom du pays, un maximum de 195 partitions et la ruche pourra gérer autant de répertoires.
- D'un autre côté, ne pas partitionner les colonnes avec une cardinalité très élevée. Par exemple, Identifiant du produit, l'horodatage et le prix car cela créera des millions de répertoires qui seront impossibles à gérer pour la ruche.
- Il est efficace lorsque le volume de données sur chaque partition n'est pas très élevé. Par exemple, si vous avez les données de la compagnie aérienne et que vous souhaitez calculer le nombre total de vols en une journée. Dans ce cas, le résultat prendra plus de temps à calculer sur la partition « Dubai », car il possède l'un des aéroports les plus fréquentés au monde, tandis que pour un pays comme « Albanie » renverra les résultats plus rapidement.
Qu'est-ce que le regroupement?
Dans l'exemple ci-dessus, on sait qu'on ne peut pas partitionner sur le prix de la colonne car son type de données est float et il y a une infinité de prix uniques possibles.
Hive devra générer un répertoire distinct pour chacun des prix uniques et il serait très difficile pour Hive de les gérer. Au lieu de cela, nous pouvons définir manuellement le nombre de dépôts que nous voulons pour ces colonnes.
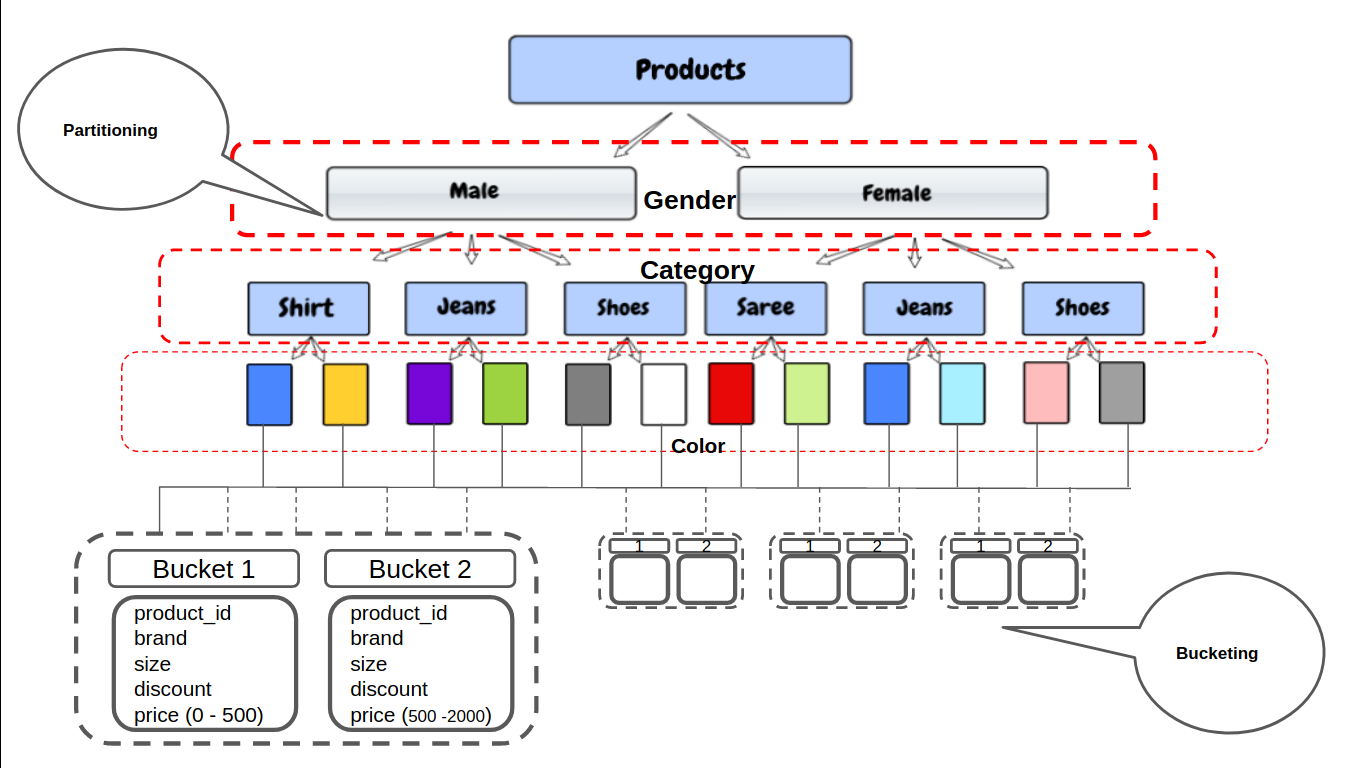
En regroupement, les partitions peuvent être subdivisées en groupes en fonction de la fonction de hachage d'une colonne. Fournit une structure supplémentaire aux données qui peuvent être utilisées pour des requêtes plus efficaces.
CRÉER TABLE produits ( chaîne product_id,
chaîne de marque,
chaîne de taille,
flotteur,
prix flottant )
PARTITIONNÉ PAR (chaîne de genre,
chaîne de catégorie,
chaîne de couleur)
CLUSTER PAR (le prix) DANS 50 GODETS;
À présent, ne sera créé que 50 dépôts quel que soit le nombre de valeurs uniques dans la colonne des prix. Par exemple, dans le premier cube, tous les produits avec un prix [ 0 – 500 ] L'Iran, et dans le groupe de produits suivant avec un prix [ 500 – 200 ] etc.
Quand utiliser le regroupement?
- Nous ne pouvons pas diviser en une colonne avec une cardinalité très élevée. Trop de partitions entraîneront plusieurs fichiers Hadoop, lo que aumentará la carga en el mismo nœudNodo est une plateforme digitale qui facilite la mise en relation entre les professionnels et les entreprises à la recherche de talents. Grâce à un système intuitif, Permet aux utilisateurs de créer des profils, Partager des expériences et accéder à des opportunités d’emploi. L’accent mis sur la collaboration et le réseautage fait de Nodo un outil précieux pour ceux qui souhaitent élargir leur réseau professionnel et trouver des projets qui correspondent à leurs compétences et à leurs objectifs...., puisqu'il doit transporter les métadonnées de chacune des partitions.
- Si certaines combinaisons du côté carte sont impliquées dans vos requêtes, les tables groupées sont une bonne option. La jointure côté carte est un processus où deux tables sont jointes en utilisant la fonction de carte seule sans aucune fonction réduite. Je vous recommande de lire cet article pour mieux comprendre les combinaisons du côté de la carte: Le côté de la carte rejoint Hive
Remarques finales
Dans cet article, nous avons vu ce qu'est la partition et le regroupement, comment les créer et quels sont leurs avantages et inconvénients.
Je vous recommande fortement de consulter les ressources suivantes pour en savoir plus sur Apache Hive:
Si vous avez des questions concernant cet article, Laissez-moi savoir dans la section commentaire ci-dessous.





