introduction
Les scientifiques des données sont une race d'animaux paresseux !! Nous détestons la pratique de faire tout travail répétable manuellement. Nous tremblons de peur à la simple pensée de faire des tâches manuelles fastidieuses et lorsque nous sommes confrontés à un, nous essayons de l'automatiser pour que le monde devienne un meilleur endroit.
Nous avons organisé des réunions en Inde ces derniers mois et nous voulions voir ce que faisaient certaines des meilleures réunions du monde.. Pour un être humain normal, cela signifierait parcourir les pages de réunion et trouver ces informations manuellement.
Pas pour un data scientist!
Que sont les réunions?
Meetup peut être mieux compris comme un rassemblement auto-organisé de personnes pour atteindre un objectif prédéfini. Meetup.com est le plus grand réseau de groupe local au monde. La mission de Meetup est « revitaliser la communauté locale et aider les gens du monde entier à s'organiser ».
Le processus de recherche de réunion peut prendre beaucoup de temps (je préfère le dire). Il y a plusieurs limitations attachées (que j'ai expliqué dans la section suivante). Mais, Comment un data scientist effectuerait-il cette tâche pour gagner du temps? Bien sûr, s'efforcerait d'automatiser ce processus!
Dans cet article, Je vais vous présenter l'approche d'un data scientist pour localiser des groupes de réunion à l'aide de Python. Prenant ceci comme référence, vous pouvez trouver des groupes situés dans n'importe quel coin de la terre. Vous pouvez également ajouter votre propre couche d'analyse pour découvrir des idées sympas.
Inscrivez-vous au Data Hackathon 3.X: gagnez un coupon Amazon d'une valeur 10.000 roupies (~ 200 Dollars)
Le défi avec la mise au point manuelle
Disons que vous voulez découvrir et rejoindre certaines des meilleures réunions de votre région.. Évidemment, vous pouvez faire cette tâche manuellement, mais il y a des défis auxquels vous faites face:
- Il pourrait y avoir plusieurs groupes avec des noms et des objectifs similaires. Il devient difficile de trouver les bons juste en lisant les noms.
- Disons que vous recherchez des réunions en science des données, vous devrez naviguer manuellement dans chacun des groupes, ver varios paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... para juzgar su calidad (par exemple, fréquence des réunions, adhésion, avis moyen, etc.) puis prendre la décision de rejoindre le groupe ou non, Cela me semble beaucoup de travail!
- En outre, si vous avez des exigences spécifiques, comme si vous vouliez voir des groupes présents dans plusieurs villes, vous finirez par parcourir les groupes de chaque ville manuellement; Je rétrécis déjà à la pensée.
Supposons que vous vous trouviez dans une localité avec plus de 200 groupes dans votre domaine d'intérêt. Comment trouveriez-vous le meilleur?

La solution du data scientist
Dans cet article, j'en ai identifié plusieurs Rencontres Python des villes en Inde, EE. UU., Royaume-Uni, Hong Kong, TW y Australie. Voici les étapes que je vais effectuer:
- Obtenez des informations sur meetup.com en utilisant l'API qu'ils ont fournie.
- Déplacez les données vers un DataFrame et
- Analysez-le et rejoignez les bons groupes
Ces étapes sont assez faciles à réaliser. Ensuite, Je liste les étapes pour les exécuter. Comme mentionné précédemment, ce n'est que le début des possibilités qui s'ouvrent. Vous pouvez utiliser ces informations pour acquérir une mine de connaissances sur diverses communautés à travers le monde..
Paso 0: importer des bibliothèques
Voici la liste des bibliothèques que j'ai utilisées pour coder ce projet.
importer l'urllib importer json importer des pandas au format pd importer matplotlib.pyplot en tant que plt de geopy.geocodeurs importer Nominatim
Voici un aperçu rapide de ces bibliothèques:
- urllib: Ce module fournit une interface de haut niveau pour obtenir des données du World Wide Web.
- json (Notation d'objet de script Java): la biblioteca jsonJSON, o Notation d’objet JavaScript, Il s’agit d’un format d’échange de données léger, facile à lire et à écrire pour les humains, et facile à analyser et à générer pour les machines. Il est couramment utilisé dans les applications Web pour envoyer et recevoir des informations entre un serveur et un client. Sa structure est basée sur des paires clé-valeur, ce qui le rend polyvalent et largement adopté dans le développement de logiciels.. puede analizar JSON a partir de cadenas o archivos. La bibliothèque analyse JSON dans un dictionnaire ou une liste Python.
- pandas: Utilisé pour les manipulations et opérations de données structurées. Beaucoup utilisé pour la préparation et le traitement des données.
- matplotlib: Utilisé pour tracer une grande variété de graphiques, depuis histogrammesLes histogrammes sont des représentations graphiques qui montrent la distribution d’un ensemble de données. Ils sont construits en divisant la plage de valeurs en intervalles, O "Bacs", et compter la quantité de données tombées dans chaque intervalle. Cette visualisation vous permet d’identifier des modèles, Tendances et variabilité des données, faciliter l’analyse statistique et la prise de décision éclairée dans diverses disciplines.... hasta gráficos de líneas y gráficos de calor.
- géocodeurs: Bibliothèque de géocodage simple et cohérente écrite en Python.
Paso 1: utiliser l'API pour lire les données au format JSON
Vous pouvez obtenir des données de n'importe quel site Web de différentes manières:
- Suivez les pages Web à l'aide d'une combinaison de bibliothèques telles que BeautifulSoup et Scrapy. Trouvez les tendances sous-jacentes en html à l'aide d'expressions régulières pour extraire les données requises.
- Si le site Web fournit une API (Interface de programmation d'applications), l'utiliser pour obtenir les données. Vous pouvez comprendre cela comme un intermédiaire entre un programmeur et une application. Ce courtier accepte les demandes et, si cette demande est autorisée, renvoie les données.
- Des outils comme import.io peuvent également vous aider à le faire.
Pour les sites Web qui fournissent une API, est généralement le meilleur moyen d'obtenir l'information. La première méthode mentionnée ci-dessus est susceptible de modifier la mise en page d'une page et, parfois, ça peut être très compliqué. Heureusement, Meetup.com propose plusieurs API pour accéder aux données requises. Utiliser cette API, nous pouvons accéder à des informations sur divers groupes.
Pour accéder à la solution automatisée basée sur l'API, il nous faudrait du courage pour sig_id Oui signer (différent pour différents utilisateurs). Suivez les étapes ci-dessous pour accéder à ces.
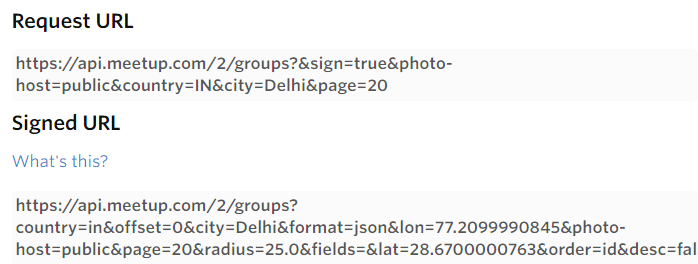
Paso 2: Générer une liste d'URL signées pour toutes les villes données
À présent, nous devrions demander une URL signée pour chaque recherche (dans notre cas, ville + thème) et la sortie de ces URL signées fournira les informations détaillées sur les groupes correspondants:
- Créer une liste de toutes les villes
- Créez un objet pour accéder à la longitude et la latitude de la ville.
- Accédez à la ville à partir de la liste donnée et générez la latitude et la longitude en utilisant « géolocalisateur « objet
- Générer une chaîne d'URL avec les attributs requis comme format de données (json), radio (nombre de kilomètres du centre-ville, 50), thème (Python), Latitude et longitude
- Répétez cette étape pour chaque ville et ajoutez toutes les URL dans une liste
lieux = [ "san francisco", "Californie", "Boston ", "New York" , "Pennsylvanie", "Colorado", "Seattle", "Washington","les anges", "San Diego", "houston", "austin", "Kansas", "Delhi", "chennai", "bangalore", "Mumbai" , "Sydney","Melbourne", "Perth", "Adélaïde", "Brisbane", "Launceston", "Newcastle" , "Pékin", "shanghai", "Suzhou", "Shenzhen","Canton","Dongguan", "Taipei", "Chengdu", "Hong Kong"] URL = [] #listes d'URL rayon = 50.0 #ajouter le rayon en miles data_format = "json" sujet = "Python" #ajoutez votre choix de sujet ici sig_id = "########" # initialiser avec votre identifiant de signe, vérifier l'échantillon de clé signée signe = "##############" # initialiser avec votre signe, vérifier l'échantillon de clé signée
pour placer dans des endroits:
location = geolocator.geocode(endroit)
urls.append("https://api.meetup.com/2/groups?décalage=0&format=" + format_données + "&lon=" + str(emplacement.longitude) + "&sujet=" + sujet + "&photo-host=public&page=500&rayon=" + str(rayon)+"&champs=&années =" + str(emplacement.latitude) + "&commande=identifiant&desc = faux&sig_id=" +sig_id + "&signe =" + signer)
Paso 3: lire les données de l'url et accéder aux fonctions pertinentes dans un DataFrame
À présent, nous avons une liste d'urls pour toutes les villes. Ensuite, nous utiliserons la bibliothèque urllib pour lire les données au format JSON. Alors, nous allons lire les données dans une liste avant de les convertir en DataFrame.
ville,pays,évaluation,Nom,membres = [],[],[],[],[] pour l'url dans les URL: réponse = urllib.urlopen(URL) données = json.charges(réponse.lire()) données = données["résultats"] #données accessibles de la clé de résultats uniquement pour i dans les données : ville.append(je['ville']) pays.append(je['pays']) note.append(je['évaluation']) nom.append(je['Nom']) membres.append(je['membres']) df = pd.DataFrame([ville,pays,évaluation,Nom,membres]).T df.columns=['ville','pays','évaluation','Nom','membres']
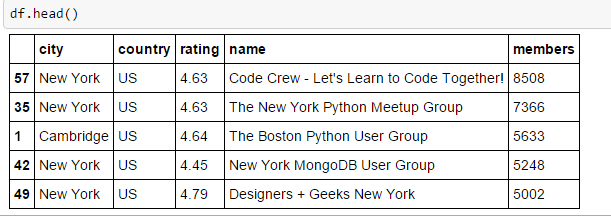
Paso 4: comparer les groupes Meetup dans différentes villes
Il est temps d'analyser les données maintenant et de trouver les bons groupes en fonction de diverses métriques, comme le nombre de membres, Les diplômes, la ville et les autres. Voici quelques constatations de base, que j'ai généré pour des groupes de pythons dans différentes villes de l'Inde, EE. UU., Royaume-Uni, Hong Kong, TW y Australie.
Pour en savoir plus sur ces codes Python, Vous pouvez lire des articles sur l'exploration et la visualisation des données à l'aide de Python
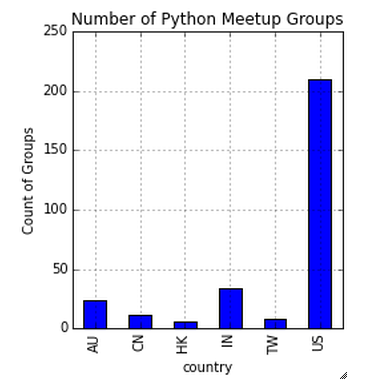
Nombre de groupes Python dans six pays
freq = df.groupby('pays').ville.compte()
fig = plt.figure(taille de la figue=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Pays')
ax1.set_ylabel(« Nombre de groupes »)
ax1.set_title("Nombre de groupes Meetup Python")
freq.plot(genre='bar')  Ci-dessus, vous pouvez remarquer que les États-Unis sont le leader des groupes de rencontre python. Ces statistiques peuvent également nous aider à estimer la pénétration du python dans l'industrie américaine de la science des données par rapport aux autres.
Ci-dessus, vous pouvez remarquer que les États-Unis sont le leader des groupes de rencontre python. Ces statistiques peuvent également nous aider à estimer la pénétration du python dans l'industrie américaine de la science des données par rapport aux autres.
 Ci-dessus, vous pouvez remarquer que les États-Unis sont le leader des groupes de rencontre python. Ces statistiques peuvent également nous aider à estimer la pénétration du python dans l'industrie américaine de la science des données par rapport aux autres.
Ci-dessus, vous pouvez remarquer que les États-Unis sont le leader des groupes de rencontre python. Ces statistiques peuvent également nous aider à estimer la pénétration du python dans l'industrie américaine de la science des données par rapport aux autres.Taille moyenne des groupes dans tous les pays
freq = df.groupby('pays').somme.membres()/df.groupby('pays').nombre.de.membres()
fig = plt.figure(taille de la figue=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Pays')
ax1.set_ylabel(« Membres moyens dans chaque groupe »)
ax1.set_title("Groupes de rencontre Python")
freq.plot(genre='bar')
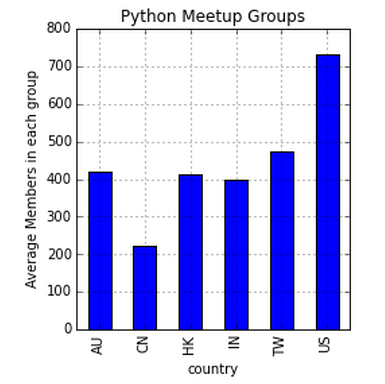
Une fois de plus, EE. UU. Apparaît comme le leader en nombre moyen de membres dans chaque groupe, tandis que le CN a la moyenne la plus basse.
Note moyenne des groupes dans tous les pays
freq = df.groupby('pays').cote.somme()/df.groupby('pays').note.compte()
fig = plt.figure(taille de la figue=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Pays')
ax1.set_ylabel('Note moyenne')
ax1.set_title("Groupes de rencontre Python")
freq.plot(genre='bar')
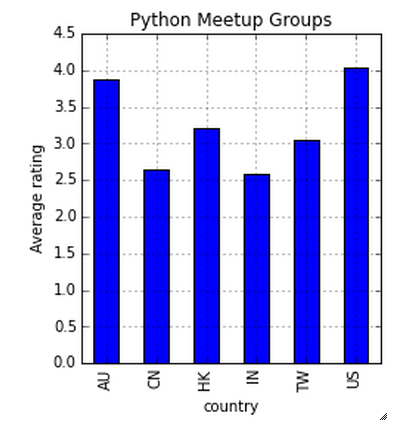 UA et EE. UU. Ils ont une note moyenne similaire (~ 4) dans tous les groupes.
UA et EE. UU. Ils ont une note moyenne similaire (~ 4) dans tous les groupes.
Les 2 meilleurs groupes de chaque pays
df=df.sort(['pays','membres'], ascendant=[Faux,Faux])
df.groupby('pays').diriger(2)
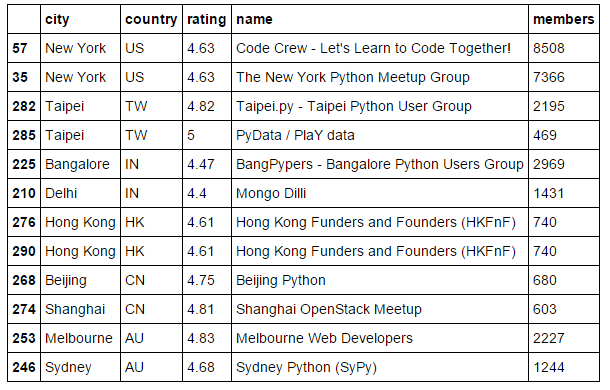
Il est temps d'identifier les deux principaux groupes dans chaque pays en fonction du nombre de membres. Vous pouvez également identifier les groupes en fonction de la notation. Ici, j'ai fait une analyse de base pour illustrer cette approche. Vous pouvez également accéder à d'autres API pour trouver des informations telles que les événements à venir, nombre d'événements, durée des événements et autres, puis fusionner toutes les informations pertinentes en fonction de group_id (ou valeur clé).
Code final
Voici le code final de cet exercice, vous pouvez jouer avec en mettant votre clé sig_id et sig et rechercher plusieurs résultats de différents sujets dans différentes villes. Je l'ai également téléchargé dans GitHub.
importer l'urllib importer json importer des pandas au format pd importer matplotlib.pyplot en tant que plt de geopy.geocodeurs importer Nominatim
géolocalisateur = Par nom() #créer un objet
lieux = [ "san francisco", "Californie", "Boston ", "New York" , "Pennsylvanie", "Colorado", "Seattle", "Washington","les anges", "San Diego", "houston", "austin", "Kansas", "Delhi", "chennai", "bangalore", "Mumbai" , "Sydney","Melbourne", "Perth", "Adélaïde", "Brisbane", "Launceston", "Newcastle" , "Pékin", "shanghai", "Suzhou", "Shenzhen","Canton","Dongguan", "Taipei", "Chengdu", "Hong Kong"]
# connectez-vous sur meetup.com. si vous n'avez pas de compte, alors veuillez vous inscrire # Allez sur https://secure.meetup.com/meetup_api/console/?chemin=/2/groupes # Dans des sujets comme "Python", entrez le sujet de votre choix. et cliquez sur afficher la réponse # copier la clé signée. dans la clé roussie, copier les sig_id et sig et initialiser les variables sig_id et sig # exemple de clé signée : "https://api.meetup.com/2/groups?décalage=0&format=json&sujet=python&photo-host=public&page=20&rayon=25,0&champs=&commande=identifiant&desc = faux&sig_id=******&sig = *******************"
URL = [] #listes d'URL rayon = 50.0 #ajouter le rayon en miles data_format = "json" #vous pouvez ajouter un autre format comme XML sujet = "Python" #ajoutez votre choix de sujet ici
sig_id = "186640998" # initialiser avec votre identifiant de signe, vérifier l'échantillon de clé signée signe = "6dba1b76011927d40a45fcbd5147b3363ff2af92" # initialiser avec votre signe, vérifier l'échantillon de clé signée
pour placer dans des endroits:
location = geolocator.geocode(endroit)
urls.append("https://api.meetup.com/2/groups?décalage=0&format=" + format_données + "&lon=" + str(emplacement.longitude) + "&sujet=" + sujet + "&photo-host=public&page=500&rayon=" + str(rayon)+"&champs=&années =" + str(emplacement.latitude) + "&commande=identifiant&desc = faux&sig_id=" +sig_id + "&signe =" + signer)
ville,pays,évaluation,Nom,membres = [],[],[],[],[] pour l'url dans les URL: réponse = urllib.urlopen(URL) données = json.charges(réponse.lire()) données = données["résultats"] pour i dans les données : ville.append(je['ville']) pays.append(je['pays']) note.append(je['évaluation']) nom.append(je['Nom']) membres.append(je['membres']) df = pd.DataFrame([ville,pays,évaluation,Nom,membres]).T df.columns=['ville','pays','évaluation','Nom','membres'] df.sort(['membres','évaluation'], ascendant=[Faux, Faux])
freq = df.groupby('pays').ville.compte()
fig = plt.figure(taille de la figue=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Pays')
ax1.set_ylabel(« Nombre de groupes »)
ax1.set_title("Nombre de groupes Meetup Python")
freq.plot(genre='bar')
freq = df.groupby('pays').somme.membres()/df.groupby('pays').nombre.de.membres()
ax1.set_xlabel('Pays')
ax1.set_ylabel(« Membres moyens dans chaque groupe »)
ax1.set_title("Groupes de rencontre Python")
freq.plot(genre='bar')
freq = df.groupby('pays').cote.somme()/df.groupby('pays').note.compte()
ax1.set_xlabel('Pays')
ax1.set_ylabel('Note moyenne')
ax1.set_title("Groupes de rencontre Python")
freq.plot(genre='bar')
df=df.sort(['pays','membres'], ascendant=[Faux,Faux])
df.groupby('pays').diriger(2)
Remarques finales
Dans cet article, Nous analysons l'application Python pour automatiser un processus manuel et le niveau de précision pour trouver les bons groupes Meetup. Nous utilisons l'API pour accéder aux informations du Web et les transférer vers un DataFrame. Ensuite, nous analysons ces informations pour générer des informations pratiques.
Nous pouvons rendre cette application plus intelligente en ajoutant des informations supplémentaires comme les événements à venir, nombre d'événements, RSVP et diverses autres mesures. Vous pouvez également utiliser ces données pour obtenir des informations intéressantes sur la communauté et les personnes. Par exemple, Le RSVP au taux de participation pour examiner l'entonnoir de taux diffère-t-il d'un pays à l'autre? Quels pays planifient leurs réunions à l'avance?
Essayez-le à la fin et partagez vos connaissances dans la section commentaire ci-dessous.





