Depuis la dernière décennie, nous avons vu le GPU entrer en scène plus souvent dans des domaines comme le HPC (Calcul haute performance) et le domaine le plus populaire, c'est-à-dire, les jeux. Les GPU se sont améliorés d'année en année et sont maintenant capables de faire des choses incroyablement cool, mais ces dernières années, ils ont attiré encore plus d'attention en raison de l'apprentissage en profondeur.

Comment les modèles d'apprentissage en profondeur passent beaucoup de temps à s'entraîner, même les processeurs puissants n'étaient pas assez efficaces pour gérer autant de calculs à un moment donné et c'est le domaine où les GPU ont tout simplement surpassé les processeurs en raison de leur parallélisme. Mais avant de plonger profondément, commençons par comprendre quelques petites choses sur le GPU.
Qu'est-ce que le GPU?
Un GPU ou 'Graphics Processing Unit’ c'est une mini version d'un ordinateur complet, mais uniquement dédié à une tâche spécifique. Il est différent d'un processeur qui effectue plusieurs tâches en même temps. Le GPU est livré avec son propre processeur intégré à sa propre carte mère avec v-ram ou ram vidéo, et également une conception thermique appropriée pour la ventilation et le refroidissement.
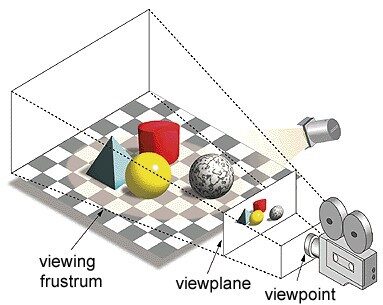
Dans le terme « unité de traitement graphique », 'Graphique’ fait référence au rendu d'une image à des coordonnées spécifiques dans un espace 2D ou 3D. Une fenêtre ou point de vue est la perspective d'un spectateur pour regarder un objet selon le type de projection utilisé. La rastérisation et le lancer de rayons sont quelques-uns des moyens de rendre des scènes 3D, les deux concepts sont basés sur un type de projection appelé projection en perspective. Qu'est-ce que la projection en perspective?
En résumé, est la façon dont une image est formée sur un plan de vue ou une toile où des lignes parallèles convergent vers un point convergent appelé «centre de projection’ aussi lorsque l'objet s'éloigne du point de vue, il semble être plus petit , exactement comment nos yeux sont représentés dans le monde réel et cela aide également à comprendre la profondeur d'une image, c'est la raison pour laquelle il produit des images réalistes.
En outre, Les GPU traitent également des géométries complexes, vecteur, sources lumineuses ou éclairages, textures, formes, etc. Comme nous avons maintenant une idée de base sur le GPU, comprenons pourquoi il est beaucoup utilisé pour le deep learning.
Pourquoi les GPU sont-ils meilleurs pour l'apprentissage en profondeur?
L'une des fonctionnalités les plus admirées d'un GPU est la capacité de calculer des processus en parallèle. C'est le point où le concept de traitement en parallèle passer à l'action. Un CPU termine généralement sa tâche de manière séquentielle. Un processeur peut être divisé en cœurs et chaque cœur effectue une tâche à la fois. Supposons qu'un processeur ait 2 noyaux. Alors, deux processus de tâches différents peuvent s'exécuter sur ces deux cœurs, réalisant ainsi le multitâche.
Mais reste, ces processus s'exécutent en série.
Cela ne signifie pas que les processeurs ne sont pas assez bons.. En réalité, Les processeurs sont vraiment bons pour gérer différentes tâches liées à différentes opérations comme la gestion des systèmes d'exploitation, livrer des feuilles de calcul, lire des vidéos HD, extraire de gros fichiers zip, Tout en même temps. Ce sont certaines des choses qu'un GPU ne peut tout simplement pas faire.
Où est la différence?
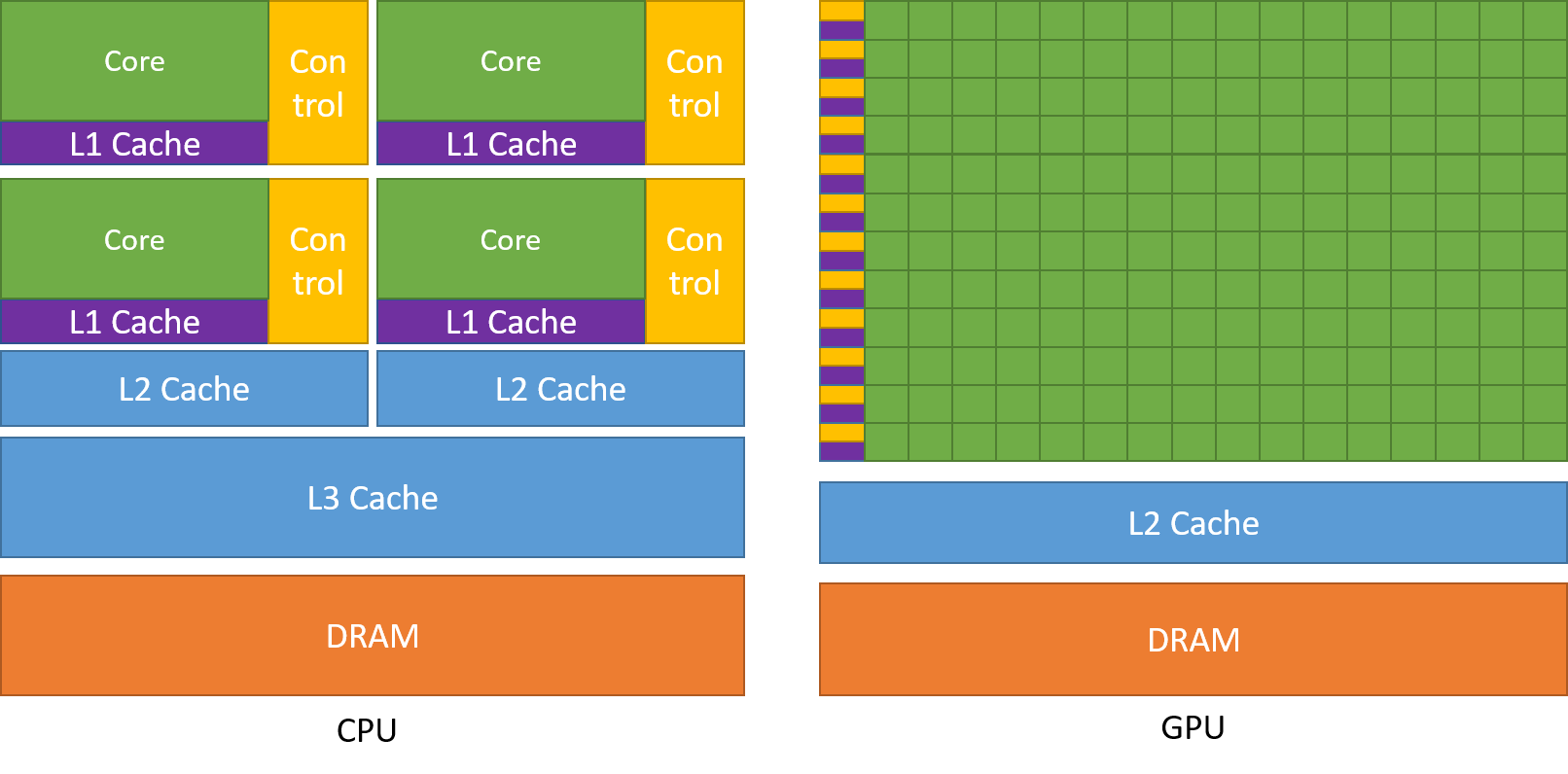
Comme mentionné précédemment, un processeur est divisé en plusieurs cœurs afin qu'ils puissent effectuer plusieurs tâches en même temps, tandis que le GPU aura des centaines et des milliers de cœurs, qui sont tous dédiés à une seule tâche. Ce sont des calculs simples qui sont effectués plus fréquemment et sont indépendants les uns des autres.. Et les deux stockent les données fréquemment requises dans leur cache respectif, suivant ainsi le principe de ‘référence de la localité'.
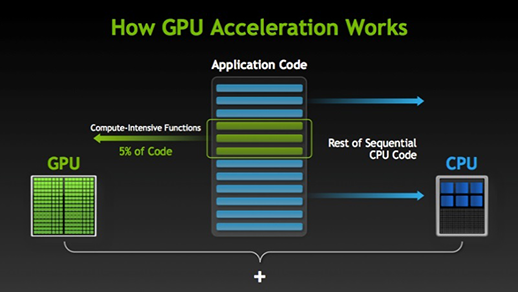
Il existe de nombreux programmes et jeux qui peuvent tirer parti des GPU pour exécuter. L'idée derrière cela est de rendre parallèles certaines parties de la tâche ou du code d'application, mais pas tous les processus. En effet, la plupart des processus de tâche n'ont besoin de s'exécuter que de manière séquentielle. Par exemple, la connexion à un système ou à une application n'a pas besoin d'être parallèle.
Quand il y a une partie de l'exécution qui peut se faire en parallèle, il suffit de passer au GPU pour le traitement, où en même temps la tâche séquentielle est exécutée sur la CPU, puis les deux parties de la tâche sont à nouveau combinées.
Sur le marché des GPU, il y a deux acteurs principaux, c'est-à-dire, AMD et Nvidia. Les GPU Nvidia sont largement utilisés pour l'apprentissage en profondeur car ils sont largement pris en charge dans le logiciel du forum, Contrôleurs, CUDA et cuDNN. Ensuite, en termes d'intelligence artificielle et d'apprentissage profond, Nvidia est un pionnier depuis longtemps.
Les réseaux de neurones sont dits parallèle embarrassant, ce qui signifie que les calculs dans les réseaux de neurones peuvent être facilement exécutés en parallèle et sont indépendants les uns des autres.
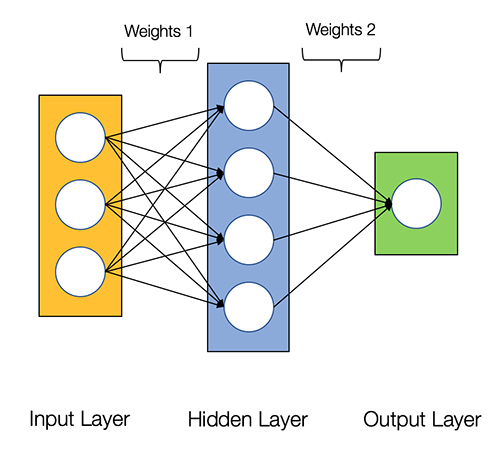
Certains calculs comme le calcul des poids et des fonctions d'activation de chaque couche, la rétropropagation peut se faire en parallèle. De nombreux articles de recherche sont également disponibles à ce sujet..
Les GPU Nvidia sont livrés avec des cœurs spécialisés appelés MIRACLES noyaux qui aident à accélérer l'apprentissage en profondeur.
Qu'est-ce que CUDA?
Significa CUDA 'Compute Unified Device Architecture’ qui a été lancé l'année 2007, c'est un moyen de réaliser un calcul parallèle et de tirer le meilleur parti de la puissance de votre GPU de manière optimisée, résultant en de bien meilleures performances lors de l'exécution des tâches.
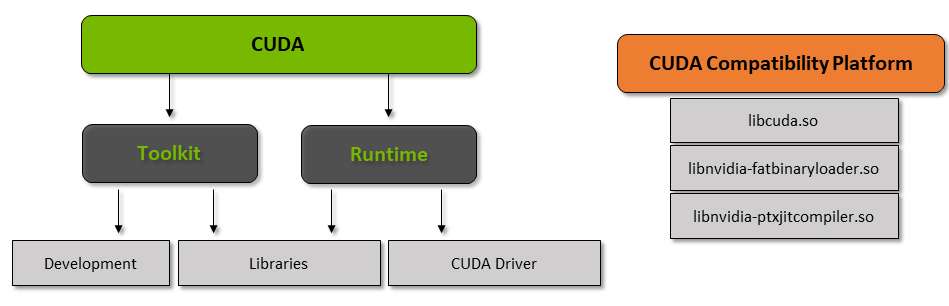
La boîte à outils CUDA est un package complet composé d'un environnement de développement utilisé pour créer des applications utilisant des GPU.. Cette boîte à outils contient principalement le compilateur, le débogueur et les bibliothèques c / c ++. En outre, le runtime CUDA a ses pilotes pour qu'il puisse communiquer avec le GPU. CUDA est également un langage de programmation spécialement conçu pour demander au GPU d'effectuer une tâche.. Également connu sous le nom de planification GPU.
Ci-dessous se trouve un simple programme hello world juste pour avoir une idée de ce à quoi ressemble le code CUDA.
/* Bonjour programme mondial en cuda * #comprendre<stdio.h> #comprendre<stdlib.h> #comprendre<cuda.h>__global__ void démo() { imprimer("Bonjour le monde!,mon premier programme cuda"); }int main() { imprimer("Du principal!m"); démo<<<1,1>>>(); revenir 0; }

Qu'est-ce que cuDNN?

cuDNN est une bibliothèque de réseau neuronal optimisée pour le GPU et qui peut tirer pleinement parti du GPU Nvidia. Cette bibliothèque se compose de l'implémentation de convolution, propagation avant et arrière, fonctions d'activation et de regroupement. C'est une bibliothèque indispensable sans laquelle vous ne pouvez pas utiliser le GPU pour entraîner les réseaux de neurones.
Grand bond en avant avec les noyaux Tensor !!
Dans l'année 2018, Nvidia a lancé une nouvelle gamme de ses GPU, c'est-à-dire, la série 2000. Aussi appelé RTX, Ces cartes sont livrées avec des cœurs Tensor dédiés au deep learning et basés sur l'architecture Volta.
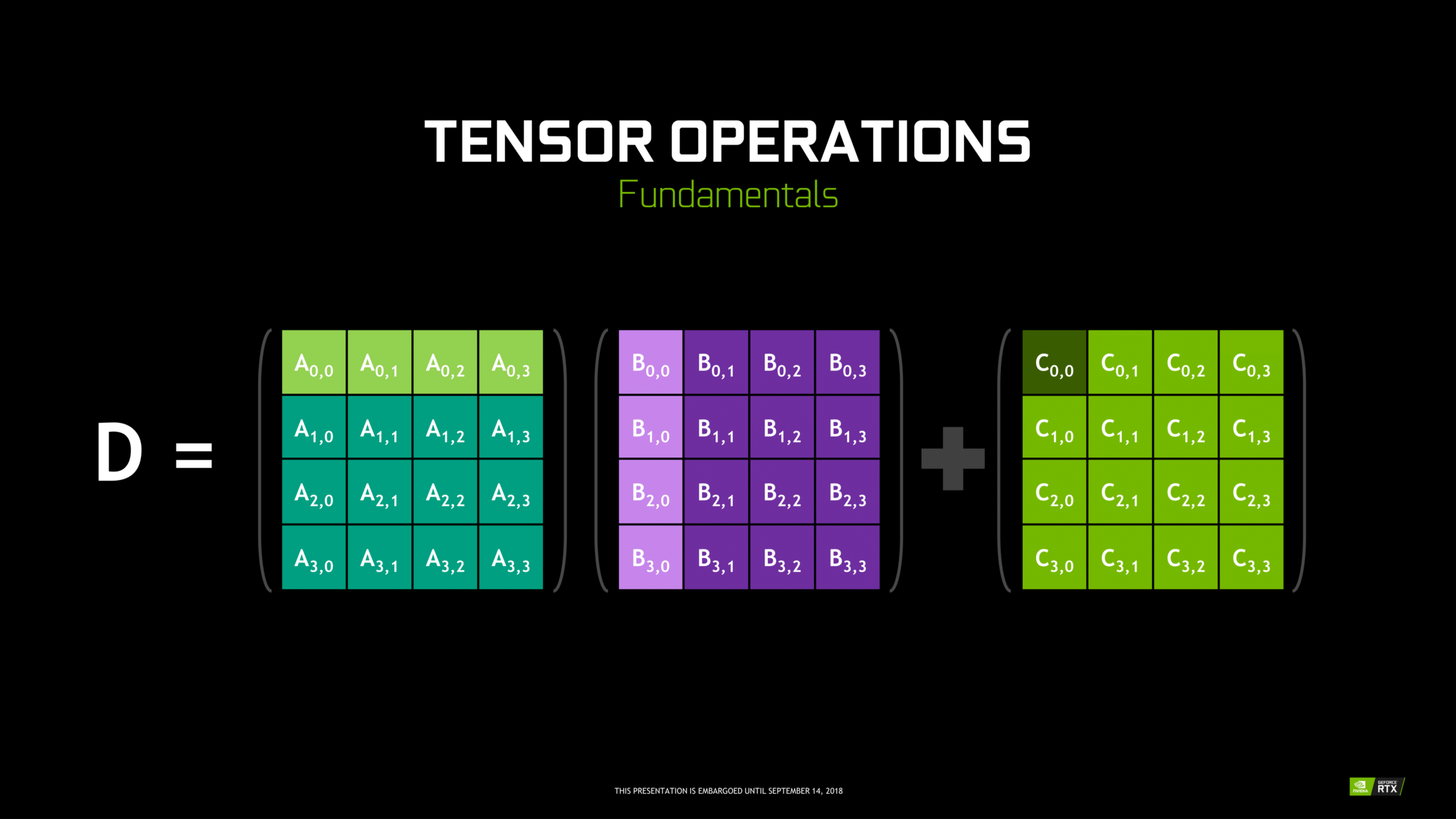
Les noyaux tenseurs sont des noyaux particuliers qui effectuent la multiplication matricielle 4 X 4 FP16 et la somme avec 4 X 4 Matrice FP16 ou FP32 en précision moyenne, la sortie se traduira par un tableau 4 X 4 FP16 ou FP32 avec une précision totale.
Noter: 'FP’ signifie virgule flottante pour mieux comprendre la virgule flottante et la précision, vérifie ça Blog.
Comme indiqué par Nvidia, les cœurs tenseurs de nouvelle génération basés sur l'architecture Volta sont beaucoup plus rapides que les cœurs CUDA basés sur l'architecture Pascal. Cela a donné un énorme coup de pouce à l'apprentissage en profondeur..
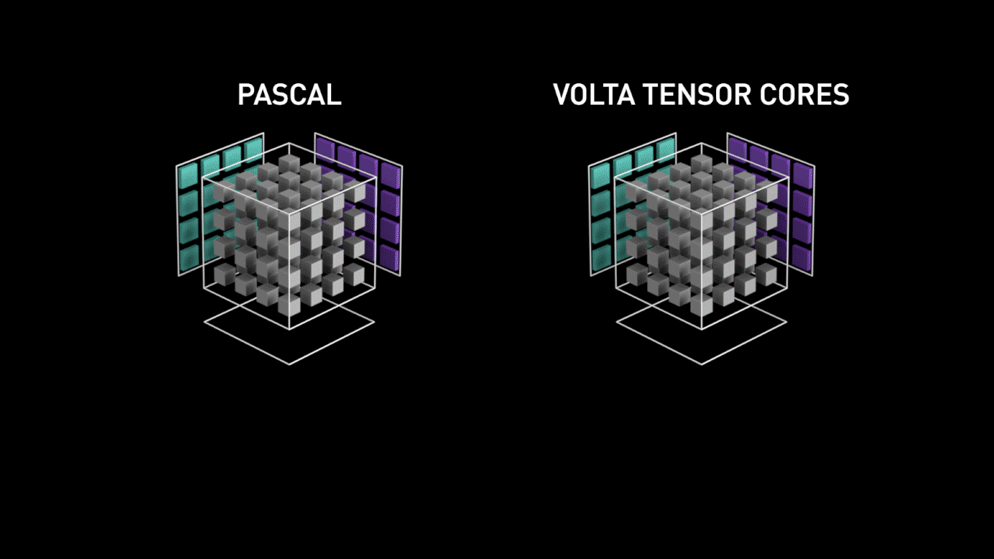
Au moment d'écrire ce blog, Nvidia a annoncé la dernière série 3000 de sa gamme de GPU qui vient avec l'architecture Ampere. Dans ce, amélioration des performances des cœurs tenseurs par 2x. Il apporte également de nouvelles valeurs de précision comme TF32 (flotteur tenseur 32), FP64 (point flottant 64). Le TF32 fonctionne de la même manière que le FP32 mais avec une accélération jusqu'à 20x, à la suite de tout cela, Nvidia affirme que le temps de formation ou d'inférence du modèle sera réduit de quelques semaines à quelques heures.
AMD contre Nvidia

DMLA Les GPU sont décents pour les jeux, mais dès que l'apprentissage en profondeur démarre, simplement Nvidia est en avance. Cela ne veut pas dire que les GPU AMD sont mauvais. Cela est dû à l'optimisation du logiciel et à la non-mise à jour active des pilotes, du côté de Nvidia, ils ont de meilleurs pilotes avec des mises à jour fréquentes et en plus de cela CUDA, cuDNN permet d'accélérer le calcul.
Certaines bibliothèques appelées Tensorflow, Prise en charge de PyTorch pour CUDA. Cela signifie que les GPU d'entrée de gamme de la série GTX peuvent être utilisés 1000. Du côté d'AMD, a très peu de support logiciel pour ses GPU. Côté matériel, Nvidia a introduit des noyaux de tendeurs dédiés. AMD a ROCm pour l'accélération, mais pas bon comme noyaux tenseurs, et de nombreuses bibliothèques d'apprentissage en profondeur ne prennent pas en charge ROCm. Pendant les dernières années, aucun grand saut n'a été remarqué en termes de performances.
En raison de tous ces points, Nvidia excelle tout simplement dans l'apprentissage en profondeur.
résumé
Pour conclure de tout ce que nous avons appris, il est clair qu'à ce jour Nvidia est le leader du marché en termes de GPU, mais j'espère vraiment que même AMD rattrapera son retard à l'avenir ou au moins apportera des améliorations notables à la prochaine gamme de leurs GPU.. car ils font déjà un excellent travail en ce qui concerne leurs processeurs, c'est-à-dire, série ryzen.
La portée des GPU dans les années à venir est énorme alors que nous apportons de nouvelles innovations et avancées dans l'apprentissage en profondeur, apprentissage automatique et HPC. L'accélération GPU sera toujours utile à de nombreux développeurs et étudiants pour entrer dans ce domaine, car leurs prix deviennent également plus abordables. Merci également à la large communauté qui contribue également au développement de l'IA et du HPC.

Patil de Prathmesh
Passionné d'apprentissage automatique, science des données, développeur python.
LinkedIn: https://www.linkedin.com/in/prathmesh





