Cet article a été publié dans le cadre du Blogathon sur la science des données.
introduction
Ces situations peuvent être résolues en comprenant le cas d'utilisation de chaque métrique.
Tout le monde connaît les bases de toutes les mesures de classement fréquemment utilisées, mais quand il s'agit de savoir lequel est le bon pour évaluer les performances de votre modèle de classification, très peu font confiance à la prochaine étape à franchir.
Le enseignement superviséL’apprentissage supervisé est une approche d’apprentissage automatique dans laquelle un modèle est formé à l’aide d’un ensemble de données étiquetées. Chaque entrée du jeu de données est associée à une sortie connue, permettre au modèle d’apprendre à prédire les résultats pour de nouvelles entrées. Cette méthode est largement utilisée dans des applications telles que la classification d’images, Reconnaissance vocale et prédiction de tendances, soulignant son importance dans... normalmente se encuentra en regresión (avoir des objectifs continus) ou en classement (avoir des objectifs discrets). Cependant, dans cet article, Je vais essayer de me concentrer sur une partie très petite mais très importante de l'apprentissage automatique, c'est le sujet de prédilection des intervieweurs, « qui sait quoi », il peut également vous aider à corriger vos concepts dans les modèles de classification et, finalement, à propos de tout problème commercial. Cet article vous aidera à savoir que lorsque quelqu'un vous dit qu'un modèle ml donne un 94% précision, quelles questions poser pour savoir si le modèle fonctionne réellement comme requis.

Ensuite, Comment décider des questions qui aideront?
À présent, c'est une pensée pour l'âme.
Nous y répondrons en sachant évaluer un modèle de classification, la bonne façon.
Nous passerons en revue les sujets suivants dans cet article:
-
Précision
-
Défauts
-
Matrice de confusion
-
Métriques basées sur la matrice de confusion
-
résumé
Après avoir lu cet article, aura la connaissance de:
-
Qu'est-ce que la matrice de confusion et pourquoi devez-vous l'utiliser?
-
Comment calculer une matrice de confusion pour un problème de classification 2 cours
-
Métriques basées sur la matrice de confusion et comment les utiliser
La précision et ses défauts:
Précision (CAC) mesure la fraction de prédictions correctes. est défini comme « la relation entre les prédictions correctes et les prédictions totales faites ».

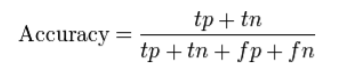
Problème de précision:
Cachez les détails dont vous avez besoin pour mieux comprendre les performances de votre modèle de classement. Vous pouvez suivre les exemples ci-dessous pour vous aider à comprendre le problème:
-
VariableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... de destino de varias clases: lorsque vos données ont plus de 2 cours. Avec 3 ou plusieurs cours, vous pouvez obtenir une sorte de précision de la 80%, mais vous ne savez pas si c'est parce que toutes les classes prédisent aussi bien ou si le modèle néglige une ou deux classes.
-
de déséquilibré
Un typique Exemple des données déséquilibrées sont dans un problème de classification des e-mails où les e-mails sont classés comme spam ou non spam. Ici, le nombre de spams est considérablement très faible (moins que 10%) que le nombre d'e-mails pertinents (Pas de spam) (plus que 90%). Ensuite, la distribution originale à deux classes conduit à un ensemble de données déséquilibré.
Si nous prenons deux cours, alors les données équilibrées signifieraient que nous avons 50% points pour chacune des classes. En outre, s'il y a 60-65% points pour une classe et 40% F
La précision de la classification ne met pas en évidence les détails dont vous avez besoin pour diagnostiquer les performances de votre modèle. Ceci peut être mis en évidence à l'aide d'une matrice de confusion.

Matrice de confusion:
Wikipédia définit le terme comme « une matrice de confusion, également connu sous le nom de matrice d'erreur, c'est un design de table spécifique qui permet la visualisation des performances d'un algorithme".

Vous trouverez ci-dessous une matrice de confusion pour deux classes (+, -).
Il y a quatre quadrants dans la matrice de confusion, qui sont symbolisés ci-dessous.
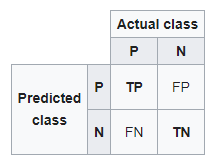
matrice de confusion
- : Le nombre d'en
- Prédit qu'un e-mail est un spam et qu'il l'est en réalité.
- Faux négatif (FN): Le nombre de cas positifs (+) et ont été incorrectement classés comme négatifs (-). Il est également connu sous le nom Erreur-type 2.
- Prédit qu'un e-mail n'est pas du spam et qu'il l'est en réalité.
- Vrai négatif (TN): Le nombre d'instances négatives (-) et ont été correctement classés comme (-).
- Prédit qu'un e-mail n'est pas du spam et en fait il n'est pas.
- Faux positif (PF): Le nombre d'instances négatives (-) et ont été classés à tort comme (+). Ceci également connu sous le nom Erreur-type 1.
- Prédit qu'un e-mail n'est pas du spam et qu'il l'est en réalité.
Pour ajouter un peu de clarté:
En haut à gauche: vrais positifs pour des valeurs d'événement correctement prédites.
En haut à droite: faux positifs pour les valeurs d'événement prédites de manière incorrecte.
En bas à gauche: faux négatifs pour des valeurs de non-événement correctement prédites.
En bas à droite: Vrais négatifs pour les valeurs sans événements mal prédits.
Métriques basées sur la matrice de confusion:
-
Précision
-
rappeler
-
Score F1
Précision
La précision calcule la capacité d'un classificateur à ne pas étiqueter une observation négative vraie comme positive.
Précision=TP/(TP+FP)
Utiliser la précision
Nous utilisons la précision lorsque nous travaillons sur un modèle similaire à l'ensemble de données de détection de spam, puisque Recall calcule en fait combien de positifs réels notre modèle capture en le qualifiant de positif.
rappeler (sensibilité)
Le rappel calcule la capacité d'un classificateur à trouver des observations positives dans l'ensemble de données. Si vous vouliez être sûr de trouver tous les commentaires positifs, pourrait maximiser la mémoire.
Rappel=TP/(TP+FN)
Nous avons toujours tendance à utiliser le retrait lorsque nous devons identifier correctement les scénarios positifs, comme dans un ensemble de données de détection de cancer ou un cas de détection de fraude. L'exactitude ou la précision ne sera pas si utile ici.
MesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... F
Pour comparer deux modèles, nous utilisons F1-Score. Il est difficile de comparer deux modèles avec une faible précision et une récupération élevée ou vice versa. Le score F1 permet de mesurer la récupération et la précision en même temps. Utilisez la moyenne harmonique au lieu de la moyenne arithmétique lorsque vous punissez davantage les valeurs extrêmes.
Comprendre la matrice de confusion
Disons que nous avons un problème de classification binaire dans lequel nous voulons prédire si un patient a un cancer ou non., selon les symptômes (les caractéristiques) introduit dans le modèle d'apprentissage automatique (classeur).
Comme étudié précédemment, le côté gauche de la matrice de confusion montre la classe prédite par le classificateur. Pendant, la rangée supérieure du tableau montre les étiquettes de classe réelles des exemples.
Si l'ensemble de problèmes a plus de deux classes, la matrice de confusion ne fait que croître du nombre respectif de classes. Par exemple, s'il y a quatre classes, serait un tableau de 4 X 4.
En mots simples, le nombre de cours n'a pas d'importance, le principal restera le même: le côté gauche de la matrice sont les valeurs prédites et le haut les valeurs réelles. Ce que nous devons vérifier, c'est où ils se croisent pour voir le nombre d'exemples prédits pour une classe donnée par rapport au nombre réel d'exemples pour cette classe.
Bien que vous puissiez calculer manuellement des métriques comme la matrice de confusion, précision et récupération, la plupart des bibliothèques d'apprentissage automatique, comment Scikit-apprendre pour Python, ont des méthodes intégrées pour obtenir ces métriques.
Générer une matrice de confusion dans Scikit Learn
Nous avons déjà couvert la théorie sur le fonctionnement de la matrice de confusion, ici, nous partagerons les commandes python pour obtenir la sortie de n'importe quel classificateur sous forme de tableau.
Pour obtenir la matrice de confusion pour notre classificateur, nous devons instancier la matrice de confusion que nous avons importée de Sklearn et lui transmettre les arguments pertinents: les vraies valeurs et nos prédictions.
de sklearn.metrics importar confusion_matrix
c_matrice = confusion_matrx (grincheux, prédictions)
imprimer (c_matrice)
résumé
En bref résumé, nous analysons:
-
précision
-
problèmes qu'il peut apporter à la table
-
matrice de confusion pour mieux comprendre le modèle de classification
-
précision et récupération et scénario sur l'endroit où les utiliser
On penche vers la précision car tout le monde a une idée de ce que ça veut dire. Il est nécessaire d'augmenter l'utilisation de métriques plus adaptées, comme la récupération et la précision, ça peut paraître étrange. Vous avez maintenant une idée intuitive pourquoi ils fonctionnent mieux pour certains problèmes, comme les tâches de tri déséquilibrées.

Les statistiques nous fournissent des définitions formelles pour évaluer ces mesures.. Notre métier de data scientist est de connaître les bons outils pour le bon métier, et cela implique la nécessité d'aller au-delà de la précision lorsque l'on travaille avec des modèles de classification.
Utilisation de la récupération, précision et score F1 (précision moyenne harmonique et récupération) permet d'évaluer des modèles de classification et nous fait aussi penser à n'utiliser que la précision d'un modèle, surtout pour les problèmes de déséquilibre. Comme nous l'avons appris, la précision n'est pas un outil d'évaluation utile dans divers problèmes, mettons donc en œuvre d'autres mesures ajoutées à notre arsenal pour évaluer le modèle.
pantalon Rohit





