Noter: Cet article a été initialement publié en octobre 6 de, 2015 et mis à jour le 13 septembre 2017
Vue d'ensemble
- Machine à vecteur de support expliquée (SVM), un algorithme ou une classification d'apprentissage automatique populaire
- Implémentation de SVM en R et Python
- En savoir plus sur les avantages et les inconvénients des machines à vecteurs de support (SVM) et ses différentes applications
introduction
Maîtriser algorithmes d'apprentissage automatique pas du tout un mythe. La plupart des débutants commencent par apprendre la régression. Il est simple à apprendre et à utiliser, mais est-ce que cela résout notre objectif? Bien sûr que non! Parce que vous pouvez faire bien plus qu'une simple régression !!
Considérez les algorithmes d'apprentissage automatique comme un arsenal plein d'axes, épées, feuilles, arcos, poignards, etc. Dispose de divers outils, mais il faut apprendre à les utiliser au bon moment. Par analogie, piense en ‘Régression’ comme une épée capable de trancher et de trancher efficacement les données, mais incapable de gérer des données très complexes. Au contraire, ‘Support Vector Machines’ c'est comme un couteau tranchant: fonctionne sur des ensembles de données plus petits, mais dans des ensembles complexes, peut être beaucoup plus fort et plus puissant dans la création de modèles d'apprentissage automatique.
À ce point, J'espère que vous maîtrisez Random Forest, l'algorithme de Naive Bayes et Modélisation d'ensemble. Mais, Je vous suggère de prendre quelques minutes et de lire à leur sujet aussi. Dans cet article, Je vais vous expliquer les bases d'une connaissance avancée d'un algorithme crucial d'apprentissage automatique, machines à vecteurs de soutien.
Vous pouvez obtenir des informations sur les machines à vecteurs de support sous forme de cours ici (c'est gratuit!):
Si vous êtes un débutant et que vous souhaitez vous lancer dans la science des données, Vous êtes au bon endroit! Découvrez les cours complets ci-dessous, sélectionnés par des experts de l'industrie, que nous avons créé juste pour vous:

Comprendre l'algorithme Support Vector Machine à partir d'exemples (avec le code)
Table des matières
- Qu'est-ce que la machine à vecteur de support?
- Comment ça marche?
- Comment implémenter SVM en Python et R?
- ¿Cómo ajustar los paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... de SVM?
- Avantages et inconvénients associés à SVM
Quelle est la machine à vecteur de support?
« Machine à vecteur de soutien » (SVM) est un système supervisé algorithme d'apprentissage automatique qui peut être utilisé pour des défis de classification ou de régression. Cependant, principalement utilisé dans les problèmes de classification. Dans l'algorithme SVM, nous traçons chaque élément de données comme un point dans un espace à n dimensions (où n est un nombre de caractéristiques qui a) la valeur de chaque caractéristique étant la valeur d'une coordonnée particulière. Alors, nous effectuons la classification en trouvant l'hyperplan qui différencie très bien les deux classes (regardez l'instantané ci-dessous).
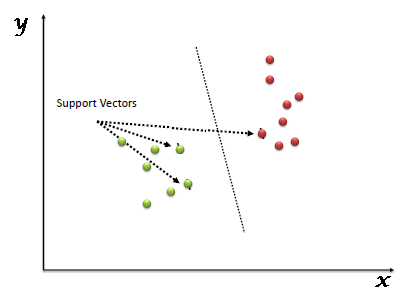
Les vecteurs supports sont simplement les coordonnées de l'observation individuelle. Le classificateur SVM est une limite qui sépare au mieux les deux classes (hyperplan / ligne).
Vous pouvez voir les machines vectorielles de support et quelques exemples de leur fonctionnement ici.
Comment ça marche?
Dessus, on s'habitue au processus de séparation des deux classes avec un hyperplan. Maintenant, la question brûlante est « Comment pouvons-nous identifier le bon hyperplan? ». Ne t'inquiète pas, ce n'est pas aussi difficile que tu le penses!
Nous comprenons:
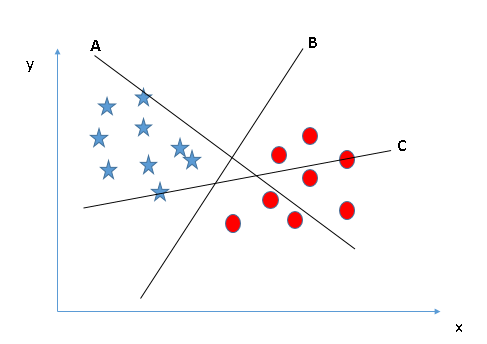
- Identifier le bon hyperplan (Scénario 1): Ici, nous avons trois hyperplans (UNE, Par C). À présent, identifier le bon hyperplan pour classer les étoiles et les cercles.
 Vous devez vous souvenir d'une règle empirique pour identifier le bon hyperplan: « Sélectionnez l'hyperplan qui sépare le mieux les deux classes ». À ce stade, l'hyperplan « B » a fait ce travail excellemment.
Vous devez vous souvenir d'une règle empirique pour identifier le bon hyperplan: « Sélectionnez l'hyperplan qui sépare le mieux les deux classes ». À ce stade, l'hyperplan « B » a fait ce travail excellemment. - Identifier le bon hyperplan (Scénario-2): Ici, nous avons trois hyperplans (UNE, Par C) et tout le monde sépare bien les classes. À présent, Comment pouvons-nous identifier le bon hyperplan?
 Ici, maximiser les distances entre le point de données le plus proche (n'importe quelle classe) et l'hyperplan nous aidera à choisir le bon hyperplan. Cette distance est appelée MargeLa marge est un terme utilisé dans divers contextes, comme la comptabilité, Économie et imprimerie. En comptabilité, fait référence à la différence entre les revenus et les coûts, qui permet d’évaluer la rentabilité d’une entreprise. Dans le domaine de l’édition, La marge est l’espace blanc autour du texte d’une page, qui le rend facile à lire et offre une présentation esthétique. Sa bonne gestion est essentielle... Voyons le prochain instantané:
Ici, maximiser les distances entre le point de données le plus proche (n'importe quelle classe) et l'hyperplan nous aidera à choisir le bon hyperplan. Cette distance est appelée MargeLa marge est un terme utilisé dans divers contextes, comme la comptabilité, Économie et imprimerie. En comptabilité, fait référence à la différence entre les revenus et les coûts, qui permet d’évaluer la rentabilité d’une entreprise. Dans le domaine de l’édition, La marge est l’espace blanc autour du texte d’une page, qui le rend facile à lire et offre une présentation esthétique. Sa bonne gestion est essentielle... Voyons le prochain instantané:
Dessus, vous pouvez voir que la marge pour l'hyperplan C est élevée par rapport à A et B. Donc, nous nommons l'hyperplan droit C. Une autre raison évidente de choisir l'hyperplan avec une marge plus élevée est la robustesse. Si nous sélectionnons un hyperplan qui a une faible marge, il y a de grandes chances d'erreur de classification. - Identifier le bon hyperplan (Scénario-3):Insinuation: Utilisez les règles comme indiqué dans la section précédente pour identifier l'hyperplan correct
 Vous devez vous souvenir d'une règle empirique pour identifier le bon hyperplan: « Sélectionnez l'hyperplan qui sépare le mieux les deux classes ». À ce stade, l'hyperplan « B » a fait ce travail excellemment.
Vous devez vous souvenir d'une règle empirique pour identifier le bon hyperplan: « Sélectionnez l'hyperplan qui sépare le mieux les deux classes ». À ce stade, l'hyperplan « B » a fait ce travail excellemment.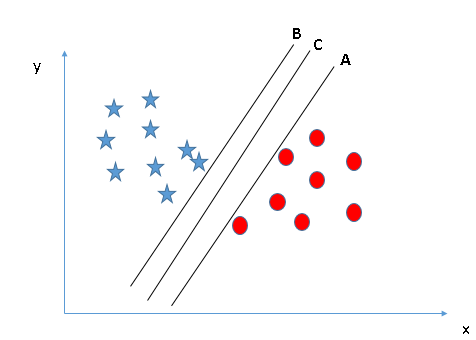 Ici, maximiser les distances entre le point de données le plus proche (n'importe quelle classe) et l'hyperplan nous aidera à choisir le bon hyperplan. Cette distance est appelée
Ici, maximiser les distances entre le point de données le plus proche (n'importe quelle classe) et l'hyperplan nous aidera à choisir le bon hyperplan. Cette distance est appelée 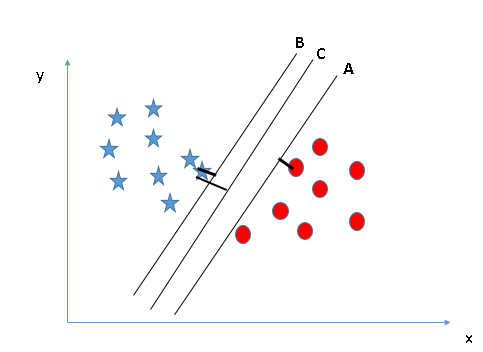
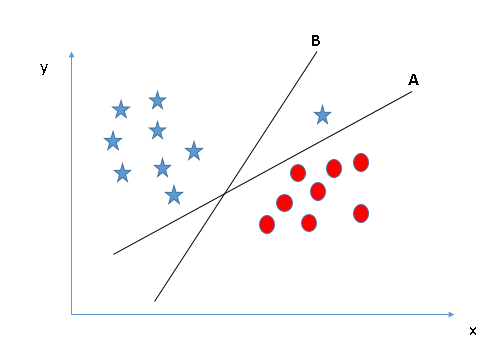 Certains d'entre vous ont peut-être choisi l'hyperplan B car il a une marge plus élevée que ONGLE. Mais, voici le piège, SVM sélectionne l'hyperplan qui classe avec précision les classes avant de maximiser la marge. Ici, l'hyperplan B a une erreur de classification et A a tout classé correctement. Donc, l'hyperplan droit est ONGLE.
Certains d'entre vous ont peut-être choisi l'hyperplan B car il a une marge plus élevée que ONGLE. Mais, voici le piège, SVM sélectionne l'hyperplan qui classe avec précision les classes avant de maximiser la marge. Ici, l'hyperplan B a une erreur de classification et A a tout classé correctement. Donc, l'hyperplan droit est ONGLE.
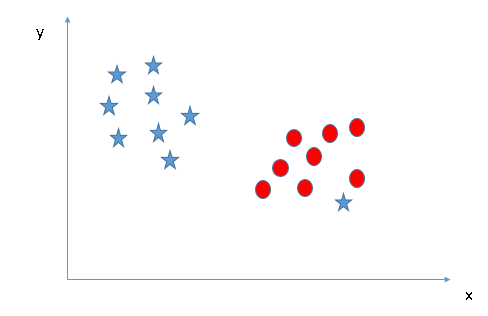
- Peut-on classer deux classes (Scénario-4) ?: Ensuite, Je ne peux pas séparer les deux classes en utilisant une ligne droite, puisque l'une des étoiles est sur le territoire de l'autre classe (cercle) comme valeur aberrante.
 Comme je l'ai déjà mentionné, une étoile à l'autre extrémité est comme une valeur aberrante pour la classe des étoiles. L'algorithme SVM a une fonction pour ignorer les valeurs aberrantes et trouver l'hyperplan qui a la marge maximale. Donc, on peut dire que la classification SVM est robuste aux valeurs aberrantes.
Comme je l'ai déjà mentionné, une étoile à l'autre extrémité est comme une valeur aberrante pour la classe des étoiles. L'algorithme SVM a une fonction pour ignorer les valeurs aberrantes et trouver l'hyperplan qui a la marge maximale. Donc, on peut dire que la classification SVM est robuste aux valeurs aberrantes.
- Trouver l'hyperplan pour séparer les classes (Scénario-5): Dans le scénario suivant, on ne peut pas avoir un hyperplan linéaire entre les deux classes, ensuite, Comment SVM classe-t-il ces deux classes? Jusqu'à maintenant, nous n'avons regardé que l'hyperplan linéaire.
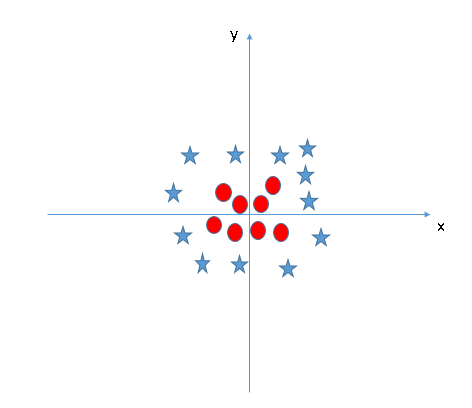
 SVM peut résoudre ce problème. Facilement! Résoudre ce problème en introduisant une fonctionnalité supplémentaire. Ici, nous allons ajouter une nouvelle fonctionnalité z = x ^ 2 + et ^ 2. À présent, traçons les points de données sur les axes x et z:
SVM peut résoudre ce problème. Facilement! Résoudre ce problème en introduisant une fonctionnalité supplémentaire. Ici, nous allons ajouter une nouvelle fonctionnalité z = x ^ 2 + et ^ 2. À présent, traçons les points de données sur les axes x et z:
Dans le graphique ci-dessus, les points à considérer sont:- Toutes les valeurs de z seraient toujours positives car z est la somme au carré de x et y
- Dans le graphique d'origine, des cercles rouges apparaissent près de l'origine des axes x et y, conduisant à une valeur inférieure de z et une étoile relativement éloignée de l'origine résultent à une valeur supérieure de z.
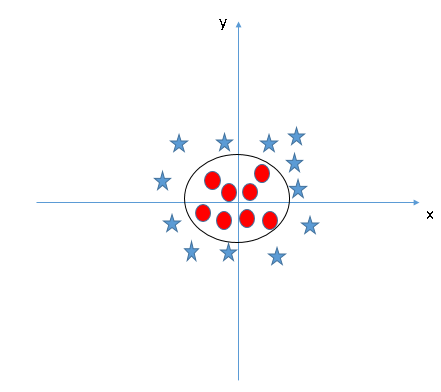
Dans le classificateur SVM, il est facile d'avoir un hyperplan linéaire entre ces deux classes. Mais, une autre question brûlante qui se pose est de savoir si nous devons ajouter cette fonction manuellement pour avoir un hyperplan. Non, l'algorithme SVM a une technique appelée coeur tour. El kernel SVM es una función que toma un espacio de entrada de baja dimension"Dimension" C’est un terme qui est utilisé dans diverses disciplines, comme la physique, Mathématiques et philosophie. Il s’agit de la mesure dans laquelle un objet ou un phénomène peut être analysé ou décrit. En physique, par exemple, On parle de dimensions spatiales et temporelles, alors qu’en mathématiques, il peut faire référence au nombre de coordonnées nécessaires pour représenter un espace. Sa compréhension est fondamentale pour l’étude et... y lo transforma en un espacio de mayor dimensión, c'est-à-dire, convertit un problème non séparable en un problème séparable. Il est particulièrement utile dans les problèmes de séparation non linéaire. En peu de mots, effectue des transformations de données extrêmement complexes, puis découvrez le processus pour séparer les données en fonction des étiquettes ou des sorties que vous avez définies.
Quand on regarde l'hyperplan dans l'espace d'entrée d'origine, ressemble à un cercle:

 Comme je l'ai déjà mentionné, une étoile à l'autre extrémité est comme une valeur aberrante pour la classe des étoiles. L'algorithme SVM a une fonction pour ignorer les valeurs aberrantes et trouver l'hyperplan qui a la marge maximale. Donc, on peut dire que la classification SVM est robuste aux valeurs aberrantes.
Comme je l'ai déjà mentionné, une étoile à l'autre extrémité est comme une valeur aberrante pour la classe des étoiles. L'algorithme SVM a une fonction pour ignorer les valeurs aberrantes et trouver l'hyperplan qui a la marge maximale. Donc, on peut dire que la classification SVM est robuste aux valeurs aberrantes.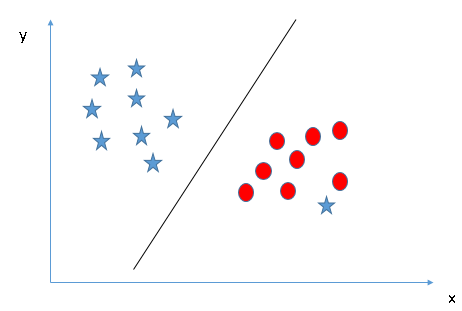
 SVM peut résoudre ce problème. Facilement! Résoudre ce problème en introduisant une fonctionnalité supplémentaire. Ici, nous allons ajouter une nouvelle fonctionnalité z = x ^ 2 + et ^ 2. À présent, traçons les points de données sur les axes x et z:
SVM peut résoudre ce problème. Facilement! Résoudre ce problème en introduisant une fonctionnalité supplémentaire. Ici, nous allons ajouter une nouvelle fonctionnalité z = x ^ 2 + et ^ 2. À présent, traçons les points de données sur les axes x et z: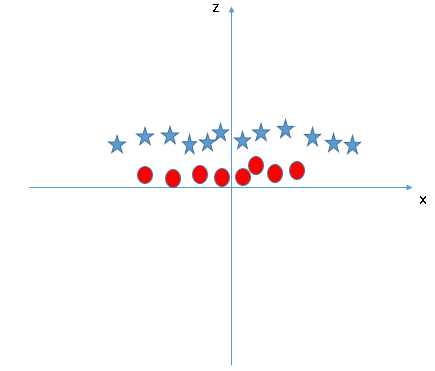
À présent, Voyons les méthodes pour appliquer l'algorithme de classificateur SVM dans un défi de science des données.
Vous pouvez également en savoir plus sur le fonctionnement de Support Vector Machine au format vidéo à partir de ce Certification en apprentissage automatique.
Comment implémenter SVM en Python et R?
Et Python, scikit-learn est une bibliothèque largement utilisée pour la mise en œuvre d'algorithmes d'apprentissage automatique. SVM est également disponible dans la bibliothèque scikit-learn et nous suivons la même structure pour l'utiliser (importer la bibliothèque, création d'objet, modèle d'ajustement et de prédiction).
À présent, Jetons un coup d'œil à un énoncé de problème réel et à un ensemble de données pour comprendre comment appliquer SVM pour la classification.
Approche du probléme
Dream Housing Finance prend en charge tous les prêts hypothécaires. Ils sont présents dans toutes les zones urbaines, semi-urbain et rural. Un client demande d'abord un prêt immobilier, après que l'entreprise a validé l'éligibilité du client à un prêt.
L'entreprise souhaite automatiser le processus d'éligibilité au prêt (temps réel) sur la base des détails du client fournis lors du remplissage d'un formulaire de demande en ligne. Ces détails sont le sexe, état civil, éducation, Nombre de personnes à charge, le revenu, montant du prêt, antécédents de crédit et autres. Pour automatiser ce processus, ont donné un problème pour identifier les segments de clientèle, qui sont éligibles au montant du prêt afin de pouvoir cibler spécifiquement ces clients. Ici, ils ont fourni un ensemble de données partiel.
Utilisez la fenêtre de codage ci-dessous pour prédire l'éligibilité au prêt dans l'ensemble de test. Essayez de modifier les hyperparamètres de Linear SVM pour améliorer la précision.
Prise en charge du code machine vectoriel (SVM) un R
Le package e1071 dans R est utilisé pour créer facilement des machines à vecteurs de support. Possède des fonctions auxiliaires, ainsi que le code pour le classificateur Naive Bayes. La création d'une machine à vecteurs de support en R et Python suit des approches similaires, Regardons maintenant le code suivant:
#Importer la bibliothèque exiger(e1071) #Contient le SVM Former <- lire.csv(fichier.choisir()) Test <- lire.csv(fichier.choisir()) # il existe différentes options associées à la formation SVM; comme changer de noyau, valeur gamma et C. # créer un modèle maquette <- svm(Cible~Prédicteur1+Prédicteur2+Prédicteur3,données=Entraînement,noyau="linéaire",gamma=0.2,coût=100) #Prédire la sortie preds <- prédire(maquette,Test) tableau(preds)
Comment ajuster les paramètres SVM?
Le réglage des valeurs des paramètres pour les algorithmes d'apprentissage automatique améliore efficacement les performances du modèle. Voyons la liste des paramètres disponibles avec SVM.
sklearn.svm.SVC(C=1.0, noyau="rbf", degré=3, gamma=0.0, coef0=0.0, rétrécissement=Vrai, probabilité=Faux,péage=0.001, taille_cache=200, class_weight=Aucun, verbeux=Faux, max_iter=-1, random_state=Aucun)
Je vais discuter de certains paramètres importants qui ont un plus grand impact sur les performances du modèle., « noyau », « gamma » Oui « C ».
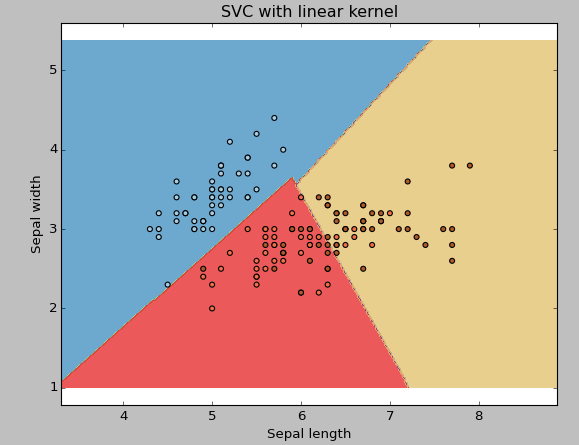
coeur: Nous en avons déjà discuté. Ici, nous avons plusieurs options disponibles avec le noyau comme, « linéaire », « rbf », « poly » et d'autres (la valeur par défaut est « rbf »). Ici « rbf » Oui « poly » sont utiles pour les hyperplans non linéaires. Voyons l'exemple, où nous avons utilisé un noyau linéaire sur deux caractéristiques de l'ensemble de données d'iris pour classer leur classe.
Prend en charge le code machine vectoriel (SVM) et Python
Exemple: Avoir un noyau SVM linéaire
importer numpy en tant que np importer matplotlib.pyplot en tant que plt de sklearn importer svm, ensembles de données
# importer des données pour jouer avec iris = jeux de données.load_iris() X = iris.données[:, :2] # nous ne prenons que les deux premières caractéristiques. Nous pourrions # évitez ce slicing laid en utilisant un ensemble de données à deux dim y = iris.cible
# nous créons une instance de SVM et aménageons les données. Nous n'échelonnons pas notre # données puisque nous voulons tracer les vecteurs de support C = 1.0 # Paramètre de régularisation SVM svc = svm.SVC(noyau="linéaire", C=1,gamma=0).ajuster(X, Oui)
# créer un maillage dans lequel tracer x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 h = (x_max / x_min)/100 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
plt.sous-intrigue(1, 1, 1) Z = svc.predict(PNJ_[xx.ravel(), aa.ravel()]) Z = Z.remodeler(xx.forme) plt.contourf(xx, aa, AVEC, cmap=plt.cm.Appairé, alpha=0,8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Appairé)
plt.xlabel('Longueur des sépales')
plt.ylabel('Largeur des sépales')
plt.xlim(xx.min(), xx.max())
plt.titre('SVC avec noyau linéaire')
plt.show()
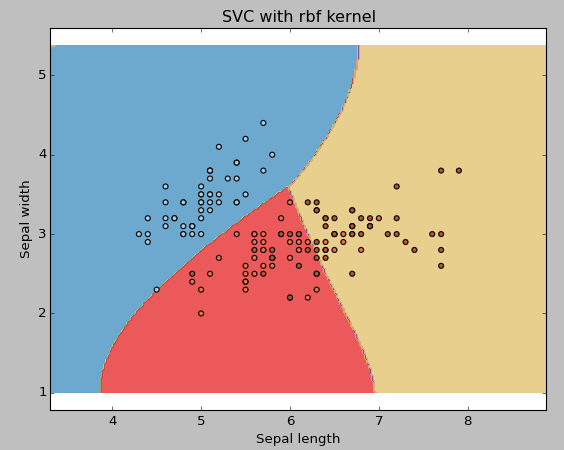
Exemple: Utiliser le noyau rbf SVM
Changez le type de noyau en rbf dans la ligne ci-dessous et observez l'impact.
svc = svm.SVC(noyau="rbf", C=1,gamma=0).ajuster(X, Oui)
Je vous suggère d'opter pour le noyau SVM linéaire si vous avez beaucoup de fonctionnalités (> 1000) parce que les données sont plus susceptibles d'être linéairement séparables dans un espace de grande dimension. En outre, vous pouvez utiliser RBF, mais n'oubliez pas de valider vos paramètres pour éviter de trop régler.
gamme: Coeficiente de kernel para ‘rbf’, ‘poli’ Oui ‘sigmoïde’. Plus la valeur gamma est élevée, se intentará ajustar con exactitud el conjunto de datos de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines...., c'est-à-dire, l'erreur de généralisation et provoquera un problème de surapprentissage.
Exemple: Nous allons différencier si nous avons des valeurs gamma différentes comme 0, 10 O 100.
svc = svm.SVC(noyau="rbf", C=1,gamma=0).ajuster(X, Oui)
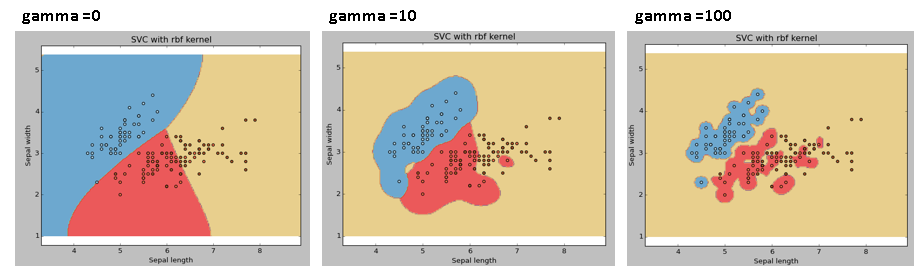
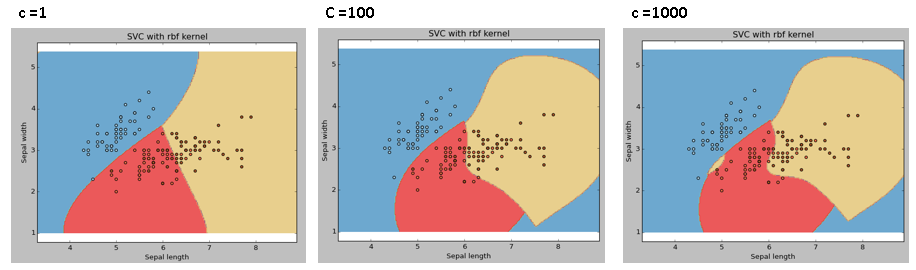
C: Paramètre de pénalité C du terme d'erreur. Il contrôle également le compromis entre les limites de décision souples et la classification correcte des points d'entraînement.
Nous devrions toujours regarder le score de validation croisée pour avoir une combinaison efficace de ces paramètres et éviter le surapprentissage.
Un R, Les SVM peuvent être ajustés de la même manière qu'ils le sont en Python. Ci-dessous sont mentionnés les paramètres respectifs pour le package e1071:
- Le paramètre du noyau peut être ajusté pour prendre « Linéaire », « Poly », « rbf », etc.
- La valeur gamma peut être ajustée en réglant le paramètre « Gamma ».
- La valeur C en Python est définie par le paramètre « Coût » un R.
Avantages et inconvénients associés à SVM
- Avantages:
- Fonctionne très bien avec un écart clair.
- Il est efficace dans les grands espaces.
- Il est efficace dans les cas où le nombre de dimensions est supérieur au nombre d'échantillons.
- Utiliser un sous-ensemble de points d'entraînement dans la fonction de décision (appelés vecteurs de support), il est donc aussi efficace en mémoire.
- Les inconvénients:
- Cela ne fonctionne pas bien lorsque nous avons un grand ensemble de données car le temps de formation requis est plus long
- Cela ne fonctionne pas non plus très bien lorsque l'ensemble de données a plus de bruit, c'est-à-dire, les classes cibles se chevauchent
- SVM ne fournit pas directement d'estimations de probabilité, ceux-ci sont calculés à l'aide d'une validation croisée coûteuse en cinq temps. Il est inclus dans la méthode SVC associée de la bibliothèque scikit-learn de Python.
Problème de pratique
Trouvez la fonctionnalité supplémentaire appropriée pour avoir un hyperplan pour séparer les classes dans l'instantané suivant:
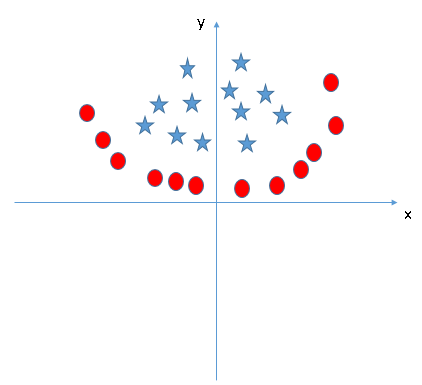
Responda el nombre de la variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... en la sección de comentarios a continuación. Ensuite, je vais révéler la réponse.
Remarques finales
Dans cet article, nous analysons en détail l'algorithme d'apprentissage automatique, Machine à vecteur de soutien. J'ai parlé de sa conception du travail, le processus d'implémentation en python, les astuces pour rendre le modèle efficace en ajustant ses paramètres, Avantages et les inconvénients, et enfin un problème à résoudre. Je vous suggère d'utiliser SVM et d'analyser la puissance de ce modèle en ajustant les paramètres. Je veux aussi connaître votre expérience avec SVM, Comment avez-vous ajusté les paramètres pour éviter un ajustement excessif et réduire le temps d'entraînement?
Trouvez-vous utile cet article? Partagez vos opinions / pensées dans la section des commentaires ci-dessous.





