Cet article a été publié dans le cadre du Blogathon sur la science des données
Prenez le travail d'un ingénieur de données, extraction de données à partir de plusieurs sources de formats de fichiers, les transformer en types de données particuliers et les charger dans une source unique pour l'analyse. Peu de temps après avoir lu cet article, à l'aide de quelques exemples pratiques, vous pourrez tester vos compétences en implémentant le web scraping et l'extraction de données avec l'API. Avec Python et l'ingénierie des données, vous pouvez commencer à collecter d'énormes ensembles de données à partir de nombreuses sources et les transformer en une seule source principale ou commencer à explorer le Web pour obtenir des informations commerciales utiles.
Synopsis:
- Pourquoi l'ingénierie des données est-elle plus fiable?
- Processus du cycle ETL
- Extraire étape par étape, transformer, fonction de charge
- À propos de l'ingénierie des données
- Sur moi
- conclusion
Pourquoi l'ingénierie des données est-elle plus fiable?
C'est une profession technologique plus fiable et à la croissance la plus rapide dans la génération actuelle, car il se concentre davantage sur le grattage Web et le suivi des ensembles de données.
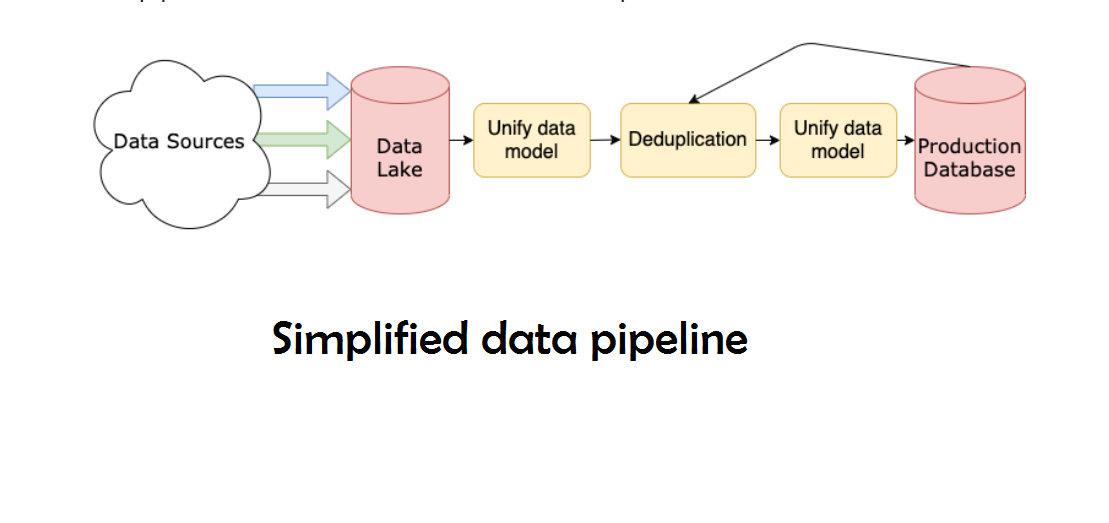
Traiter (cycle ETL):
Vous êtes-vous déjà demandé comment les données de nombreuses sources ont été intégrées pour créer une source d'informations unique? Le traitement par lots est un moyen de collecter des données et d'en savoir plus sur « comment explorer un type de traitement par lots » appelé Extract, Transformer et charger.
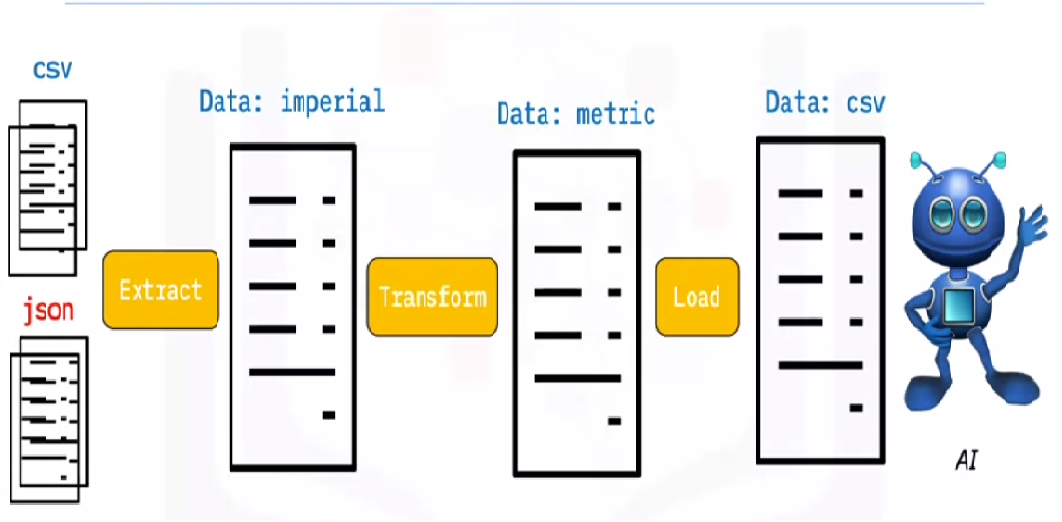
L’ETL est le processus qui consiste à extraire de grands volumes de données à partir d’une variété de sources et de formats et à les convertir en un seul format avant de les placer dans un base de donnéesUne base de données est un ensemble organisé d’informations qui vous permet de stocker, Gérez et récupérez efficacement les données. Utilisé dans diverses applications, Des systèmes d’entreprise aux plateformes en ligne, Les bases de données peuvent être relationnelles ou non relationnelles. Une bonne conception est essentielle pour optimiser les performances et garantir l’intégrité de l’information, facilitant ainsi la prise de décision éclairée dans différents contextes.... ou dans un fichier de destination.
Certaines de vos données sont stockées dans des fichiers CSV, tandis que d’autres sont stockés dans des archives JSONJSON, o Notation d’objet JavaScript, Il s’agit d’un format d’échange de données léger, facile à lire et à écrire pour les humains, et facile à analyser et à générer pour les machines. Il est couramment utilisé dans les applications Web pour envoyer et recevoir des informations entre un serveur et un client. Sa structure est basée sur des paires clé-valeur, ce qui le rend polyvalent et largement adopté dans le développement de logiciels... Vous devez collecter toutes ces informations dans un seul fichier pour que l'IA puisse les lire. Parce que vos données sont en unités impériales, mais l'IA a besoin d'unités métriques, faut les convertir. Parce que l'IA ne peut lire que les données CSV dans un seul gros fichier, vous devez d'abord le charger. Si les données sont au format CSV, mettons l'ETL suivant avec python et examinons l'étape d'extraction avec quelques exemples simples.
En regardant la liste des fichiers .json et .csv. L’extension de fichier glob est précédée d’une étoile et d’un point dans l’entrée. Une liste de fichiers .csv est renvoyée. Pour les fichiers .json, nous pouvons faire la même chose. Nous pouvons créer un fichier qui extrait les noms, hauteurs et poids au format CSV. le nom de fichier du fichier .csv est l’entrée et la sortie est une trame de données. Pour les formats JSON, nous pouvons faire la même chose.
Paso 1:
Ouvrez le bloc-notes et importez les fonctions et modules nécessaires
import glob
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetime
Données utilisées:
Les archives dealership_data contiennent des fichiers CSV, JSON et XML pour les données de voiture d’occasion qui contiennent des fonctionnalités appelées car_model, year_of_manufacture, price, Oui fuel. Extrayons donc le fichier des données brutes et transformons-le en fichier de destination et chargeons-le dans la sortie.
Télécharger le fichier source depuis le cloud:
!wget https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0221EN-SkillsNetwork/labs/module 6/Lab - Extract Transform Load/data/datasource.zip
Extraire le fichier zip:
Source de données nzip .zip dealership_data -d
Définir le chemin d’accès des fichiers de destination:
tmpfile = "dealership_temp.tmp" # store all extracted data logfile = "dealership_logfile.txt" # all event logs will be stored targetfile = "dealership_transformed_data.csv" # les données transformées sont stockées
Paso 2 (EXTRAIREL’extrait est une substance obtenue en concentrant des composés d’origine végétale, animale ou minérale. Utilisé dans une variété d’applications, comme l’industrie alimentaire, Pharmaceutique et cosmétique. Les extraits peuvent être présentés sous forme liquide, sous forme de poudre ou de teintures, et sa production implique des techniques telles que la macération, La destilación o la extracción con solventes. Su uso permite aprovechar las propiedades beneficiosas de los ingredientes originales de manera más...):
L’extrait de fonction extraira de grandes quantités de données de plusieurs sources par lots. Lors de l’ajout de cette fonctionnalité, maintenant, il découvrira et chargera tous les noms de fichiers CSV, et les fichiers CSV seront ajoutés au cadre de date à chaque itération de la boucle, avec la première itération attachant en premier, suivi de la deuxième itération, résultant en une liste de données extraites. Une fois que nous avons collecté les données, nous passerons à l'étape « Transformer » de processus.
Noter: Si il « indiceLe "Indice" C’est un outil fondamental dans les livres et les documents, qui vous permet de localiser rapidement les informations souhaitées. Généralement, Il est présenté au début d’une œuvre et organise les contenus de manière hiérarchique, y compris les chapitres et les sections. Sa préparation correcte facilite la navigation et améliore la compréhension du matériau, ce qui en fait une ressource incontournable tant pour les étudiants que pour les professionnels dans divers domaines.... de ignorar » est mis à vrai, l'ordre de chaque ligne sera le même que l'ordre dans lequel les lignes ont été ajoutées au bloc de données.
Fonction d'extraction CSV
def extrait_de_csv(file_to_process):
cadre de données = pd.read_csv(file_to_process)
renvoyer la trame de données
Fonction d'extraction JSON
def extract_from_json(file_to_process):
cadre de données = pd.read_json(file_to_process,lignes=Vrai)
renvoyer la trame de données
Fonction d'extraction XML
def extrait_de_xml(file_to_process):
dataframe = pd.DataFrame(colonnes=['modèle de voiture','année de fabrication','le prix', 'carburant'])
tree = ET.parse(file_to_process)
racine = arbre.getroot()
pour personne en racine:
car_model = personne.find("car_model").text
year_of_manufacture = int(personne.trouver("year_of_manufacture").texte)
prix = flottant(personne.trouver("le prix").texte)
carburant = personne.find("combustible").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "le prix":le prix, "combustible":combustible}, ignore_index=Vrai)
renvoyer la trame de données
Función de extracción ():
Ahora llame a la función de extracción usando su llamada de función para CSV, JSON, XML.
extrait def():
extracted_data =. DataFrame(colonnes=['modèle de voiture','année de fabrication','le prix', 'carburant'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(fichier csv), ignore_index=Vrai)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=Vrai)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=Vrai)
extracted_data de retour
Paso 3 (Transformer):
Une fois que nous avons collecté les données, pasaremos a la fase « Transformer » de processus. Esta función convertirá la altura de la columna, que está en pulgadas, en millimètres et la colonne livre, qui est en livres, au kilogramme, et il renverra les résultats dans les données variables. Dans le bloc de données d'entrée, la hauteur de la colonne est en pieds. Convertir la colonne en mètres et arrondir à deux décimales.
def transformer(Les données):
Les données['le prix'] = rond(données.prix, 2)
renvoyer des données
Paso 4 (chargement et enregistrement):
Il est temps de charger les données dans le fichier de destination maintenant que nous les avons collectées et spécifiées. Nous enregistrons la trame de données des pandas au format CSV dans ce scénario. Maintenant, nous avons parcouru les étapes d'extraction, transformer et charger des données de plusieurs sources dans un seul fichier cible. Nous devons définir une entrée de registre avant de pouvoir terminer notre travail. Nous y parviendrons en écrivant une fonction de registre.
Fonction de charge:
charge def(fichier cible,data_to_load):
data_to_load.to_csv (en anglais seulement)(fichier cible)
Fonction d’enregistrement:
Toutes les données saisies seront ajoutées aux informations actuelles lorsque le « une ». Nous pouvons ensuite attacher un horodatage à chaque phase du processus, indiquant quand il commence et quand il se termine, générer ce type d’entrée. Une fois que nous avons défini tout le code nécessaire pour effectuer le processus ETL sur les données, la dernière étape consiste à appeler toutes les fonctions.
def log(un message):
timestamp_format="%H:%M:%S-%h-%d-%Y"
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
avec ouvert("dealership_logfile.txt","une") comme f: f.écrire(horodatage + ',' + un message + 'n')
Paso 5 (Exécution du processus ETL):
Tout d’abord, nous commençons par appeler la fonction extract_data. Les données reçues de cette étape seront ensuite transférées à la deuxième étape de transformation des données. Une fois ceci terminé, les données sont chargées dans le fichier de destination. En outre, notez qu'avant et après chaque étape, l'heure et la date de début et de fin ont été ajoutées.
L'enregistrement que le processus ETL a commencé:
Journal("Travail ETL démarré")
L'enregistrement qui a démarré et terminé l'étape d'extraction:
Journal("Phase d'extraction démarrée")
extrait_données = extraire()
Journal("Phase d'extraction terminée")
L'enregistrement qui a commencé et terminé l'étape de transformation:
Journal (« La phase de transformation a commencé »)
data_transformed = transformer (données_extraites)
Journal("Phase de transformation terminée")
L'enregistrement qui a commencé et terminé la phase de téléchargement:
Journal("Phase de charge démarrée")
charge(fichier cible,données_transformées)
Journal("Phase de charge terminée")
Le dossier d'achèvement du cycle ETL:
Journal("Tâche ETL terminée")
Grâce à ce processus, nous discutons de certaines fonctions d'extraction de base, transformation et chargement
- Comment écrire une fonction d'extraction simple.
- Comment écrire une fonction de transformation simple.
- Comment écrire une fonction de chargement simple.
- Comment écrire une fonction de registre simple.
« Pas grand Les données, tu es aveugle et sourd et tu es au milieu d'une autoroute « . – Geoffroy Moore.
Au plus, nous avons discuté de tous les processus ETL. En outre, Voyons voir, « Quels sont les avantages du travail d'ingénierie des données? ».
À propos de l'ingénierie des données:
L'ingénierie des données est un vaste domaine avec de nombreux noms. Vous n'avez peut-être même pas de diplôme officiel dans de nombreux établissements. Par conséquent, il est généralement préférable de commencer par définir les objectifs des travaux d'ingénierie des données qui conduisent aux résultats attendus. Les utilisateurs qui font confiance aux ingénieurs de données sont aussi divers que les talents et les résultats des équipes d'ingénierie de données. Vos consommateurs définiront toujours les problèmes que vous gérez et comment vous les résolvez, quel que soit le secteur auquel il est dédié.
Sur moi:
Salut, je m'appelle Lavanya et je viens de Chennai. Je suis un écrivain passionné et un créateur de contenu enthousiaste. Les problèmes les plus difficiles m'excitent toujours. J'étudie actuellement mon B. Tech en génie chimique et j'ai un vif intérêt pour les domaines de l'ingénierie des données, apprentissage automatique, science des données et intelligence artificielle, et je suis constamment à la recherche de moyens d'intégrer ces domaines avec d'autres disciplines telles que la science. et la chimie pour poursuivre mes objectifs de recherche.
conclusion:
J'espère que vous avez apprécié mon article et compris ce qu'est Python en un mot, qui vous fournira quelques conseils au début de votre parcours pour apprendre l'ingénierie des données. Ce n'est que la pointe de l'iceberg en termes de possibilités.. Il existe de nombreux sujets plus sophistiqués en ingénierie des données, par exemple, pour apprendre. Cependant, avant de pouvoir saisir de telles notions, je développerai dans le prochain article. Merci!
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





