Cet article a été publié dans le cadre du Blogathon sur la science des données
Introduction
NOUS, les humains, nous lisons des textes presque à chaque minute de notre vie. Ne serait-il pas formidable que nos machines ou systèmes puissent également lire du texte comme nous le faisons? Mais la question la plus importante est “Comment faisons-nous lire nos machines”? C'est là qu'intervient la reconnaissance optique de caractères. (OCR).
Reconnaissance optique de caractères (OCR)
Reconnaissance optique de caractères (OCR) est une technique de lecture ou de capture de texte à partir de photographies imprimées ou numérisées, images manuscrites et les convertir en un format numérique modifiable et consultable.
Applications
OCR a de nombreuses applications dans les affaires d'aujourd'hui. Certains d'entre eux sont énumérés ci-dessous:
- Reconnaissance des passeports dans les aéroports
- Automatisation de la saisie des données
- Reconnaissance de plaque d'immatriculation
- Extraire les informations de la carte de visite dans une liste de contacts
- Conversion de documents manuscrits en images électroniques
- Créer des fichiers PDF interrogeables
- Créer des fichiers audibles (texte en audio)
Certains des outils OCR open source sont Tesseract, OCRopus.
Dans cet article, nous allons nous concentrer sur Tesseract OCR. Et pour lire les images nous avons besoin d'OpenCV.
Installation de Tesseract OCR:
Téléchargez le dernier programme d'installation pour Windows 10 depuis “https://github.com/UB-Mannheim/tesseract/wiki". Exécutez le fichier .exe une fois téléchargé.
Noter: N'oubliez pas de copier le chemin d'installation du logiciel à partir du fichier. Nous en aurons besoin plus tard car nous devons ajouter le chemin de l'exécutable tesseract dans le code si le répertoire d'installation est différent du répertoire par défaut.
Le chemin d'installation typique sur les systèmes Windows est C: Fichiers de programme.
Ensuite, dans mon cas, il est “C: Fichiers programme Tesseract-OCRtesseract.exe".
Ensuite, installer le conteneur Python pour Tesseract, ouvrir l'invite de commande et exécuter la commande “pip instalar pytesseract".
OpenCV
OpenCV (Vision par ordinateur Open Source) est une bibliothèque open source pour les applications de traitement d'images, apprentissage automatique et vision par ordinateur.
OpenCV-Python est l'API Python pour OpenCV.
Pour l'installer, ouvrir l'invite de commande et exécuter la commande “pip instalar opencv-python".
Créer un exemple de script OCR
1. Lire un exemple d'image
importer cv2
Lire l'image en utilisant la méthode cv2.imread () et enregistrez-le dans une variable "img".
img = cv2.imread("image.jpg")
Si c'est nécessaire, redimensionner l'image en utilisant la méthode cv2.resize ()
img = cv2.redimensionner(img, (400, 400))
Afficher l'image à l'aide de la méthode cv2.imshow ()
cv2.imshow("Image", img)
Afficher la fenêtre à l'infini (pour empêcher le noyau de planter)
cv2.waitKey(0)
Fermez toutes les fenêtres ouvertes
cv2.destroyAllWindows()
2. Conversion d'images en chaîne
importer pytesseract
Définir le chemin de tesseract dans le code
pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe'
L'erreur suivante se produit si nous ne définissons pas le chemin.

Pour convertir une image en chaîne, utiliser pytesseract.image_to_string (img) et enregistrez-le dans une variable “texte”
text = pytesseract.image_to_string(img)
imprimer le résultat
imprimer(texte)
Code complet:
importer cv2
importer pytesseract
pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe'
img = cv2.imread("image.jpg")
img = cv2.redimensionner(img, (400, 450))
cv2.imshow("Image", img)
text = pytesseract.image_to_string(img)
imprimer(texte)
cv2.waitKey(0)
cv2.destroyAllWindows()
La sortie du code ci-dessus:
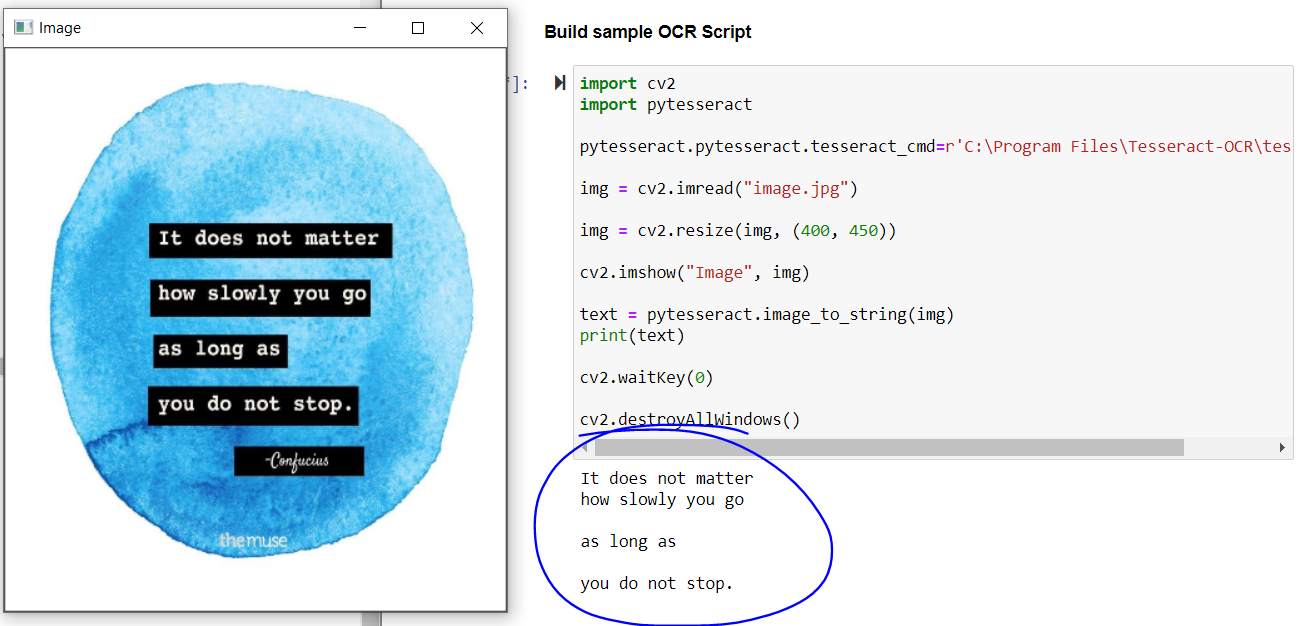
La sortie du code ci-dessus
Si on regarde le résultat, la citation principale est parfaitement extraite, mais tu n'as pas le nom du philosophe et le texte en bas de l'image.
Pour extraire le texte avec précision et éviter la chute de précision, nous devons pré-traiter l'image. j'ai trouvé cet article (https://versdatascience.com/pre-processing-in-ocr-fc231c6035a7) plutôt utile. Veuillez vous y référer pour mieux comprendre les techniques de prétraitement.
Parfait! Maintenant que nous avons les bases nécessaires, regardons quelques applications OCR simples.
1. Création de nuages de mots dans les images de révision
Le nuage de mots est une représentation visuelle de la fréquence des mots. Plus le mot apparaît gros dans un nuage de mots, le mot est le plus couramment utilisé dans le texte.
Pour ca, J'ai pris quelques instantanés d'examen Amazon pour le produit Apple iPad 8e génération.
Exemple d'image
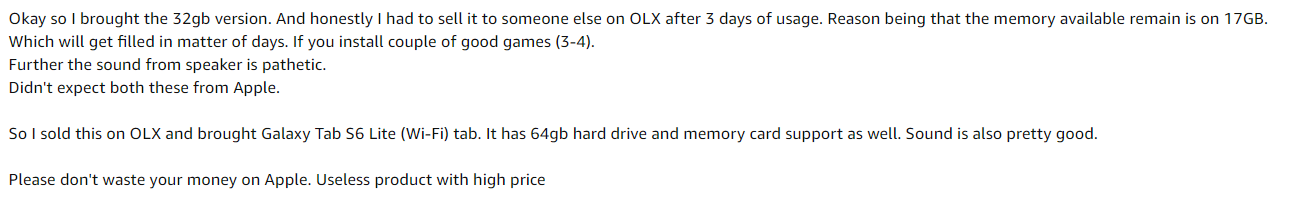
Pas:
- Créer une liste de toutes les images de révision disponibles
- Si c'est nécessaire, afficher les images à l'aide de la méthode cv2.imshow ()
- Lire du texte à partir d'images à l'aide de pytesseract
- Créer un bloc de données
- Prétraiter le texte: supprimer les caractères spéciaux, mots vides
- Construire des nuages de mots positifs et négatifs
Paso 1: crée une liste de toutes les images de révision disponibles
importer le système d'exploitation chemindossier = "Commentaires" maListeRev = os.listdir(chemindossier)
Paso 2: Si c'est nécessaire, afficher les images à l'aide de la méthode cv2.imshow ()
pour l'image dans myRevList:
img = cv2.imread(F'{chemindossier}/{image}')
cv2.imshow("Image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Paso 3: lire du texte à partir d'images en utilisant pytesseract
importer cv2
importer pytesseract
pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe'
corpus = []
pour les images dans myRevList:
img = cv2.imread(F'{chemindossier}/{images}')
si img est Aucun:
corpus.append("Impossible de lire l'image.")
autre:
rev = pytesseract.image_to_string(img)
corpus.append(tour)
liste(corpus)
corpus
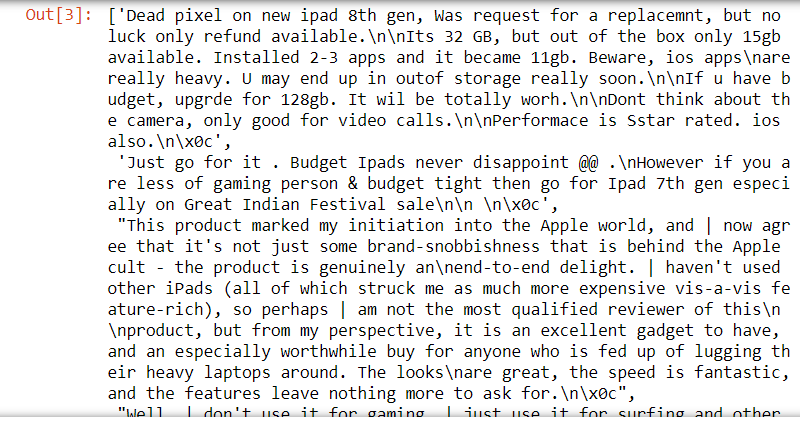
Paso 4: créer un bloc de données
importer des pandas au format pd données = pd.DataFrame(liste(corpus), colonnes=['Revoir']) Les données

Paso 5: prétraiter le texte: supprimer les caractères spéciaux, mots vides
#suppression de caractères spéciaux
importation re
def propre(texte):
retour re.sub('[^ A-Za-z0-9" "]+', ' ', texte)
Les données[« Revue nettoyée »] = données['Revoir'].appliquer(nettoyer)
Les données

Suppression des mots vides de la « révision propre’ et en ajoutant tous les mots restants à une variable de liste “liste finale”.
-
# suppression des mots vides importer nltk à partir de nltk.corpus importer des mots vides nltk.télécharger("Point") de nltk importer word_tokenize mots_arrêts = mots arrêtés.mots('Anglais') liste_finale = [] pour la colonne dans les données[[« Revue nettoyée »]]: columnSeriesObj = données[colonne] all_rev = columnSeriesObj.values pour moi à portée(longueur(all_rev)): jetons = word_tokenize(all_rev[je]) pour mot en jetons: si mot.inférieur() pas en stop_words: liste_finale.append(mot)
Paso 6: Construire des nuages de mots positifs et négatifs
Installez la bibliothèque word cloud avec la commande “nuage de mots instalaire pip".
En langue anglaise, nous avons un ensemble prédéfini de mots positifs et négatifs appelés lexiques d'opinion. Ces fichiers peuvent être téléchargés à partir de Relier ou directement de moi Dépôt GitHub.
Une fois les fichiers téléchargés, lire ces fichiers dans le code et créer une liste de mots positifs et négatifs.
avec ouvert(r"opinion-lexicon-Englishpositive-words.txt","r") en tant que position:
poswords = pos.lire().diviser("m")
avec ouvert(r"opinion-lexicon-Englishnegative-words.txt","r") comme négatif:
negwords = neg.read().diviser("m")
Importation de bibliothèques pour générer et afficher des nuages de mots.
importer matplotlib.pyplot en tant que plt à partir de wordcloud importer WordCloud
Nuage de mot positif
# Choisir les seuls mots présents dans poswords
pos_in_pos = " ".rejoindre([w pour w dans final_list si w dans poswords])
wordcloud_pos = WordCloud(
background_color="le noir",
largeur=1800,
hauteur=1400
).produire(pos_in_pos)
plt.imshow(wordcloud_pos)

Le mot « bon » est le mot le plus utilisé qui attire notre attention. Si on regarde les critiques, les gens ont écrit des critiques disant que l'iPad a un bon écran, bon son, bon logiciel et matériel.
Nuage de mot négatif
# Choisir les seuls mots présents dans les negwords
neg_in_neg = " ".rejoindre([w pour w dans final_list si w dans negwords])
wordcloud_neg = WordCloud(
background_color="le noir",
largeur=1800,
hauteur=1400
).produire(neg_in_neg)
plt.imshow(wordcloud_neg)

Les mots cher, bloqué, battu, la déception s'est démarquée dans le nuage de mots négatifs. Si nous regardons le contexte du mot coincé, dé “Bien qu'il n'ait que 3 Go de RAM, ne reste jamais coincé”, ce qui est positif pour l'appareil.
Donc, c'est bien de créer des nuages de mots bigrama / trigramme pour ne pas perdre le contexte.
2. Créer des fichiers audibles (texte en audio)
gTTS est une bibliothèque Python avec l'API de synthèse vocale de Google Translate.
Pour installer, exécuter la commande “pip installer gtts" A l'invite de commande.
Importer les bibliothèques requises
importer cv2 importer pytesseract de gtts importer gTTS importer le système d'exploitation
Définir le chemin de tesseract
pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe'
Lire l'image en utilisant cv2.imread () et récupérez le texte de l'image à l'aide de pytesseract et enregistrez-le dans une variable.
rev = cv2.imread("Avis15.PNG")
# afficher l'image en utilisant cv2.imshow() méthode
# cv2.imshow("Image", tour)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# récupérer le texte de l'image en utilisant pytesseract
txt = pytesseract.image_to_string(tour)
imprimer(SMS)
Définissez la langue et créez une conversion texte-audio à l'aide de gTTS sans passer par le texte, la langue
langue="dans" outObj = gTTS(texte=txt, lang=langue, lent=Faux)
Enregistrez le fichier audio sous “rev.mp3”
outObj.save("rev.mp3")
lire le fichier audio
os.system('rev.mp3')
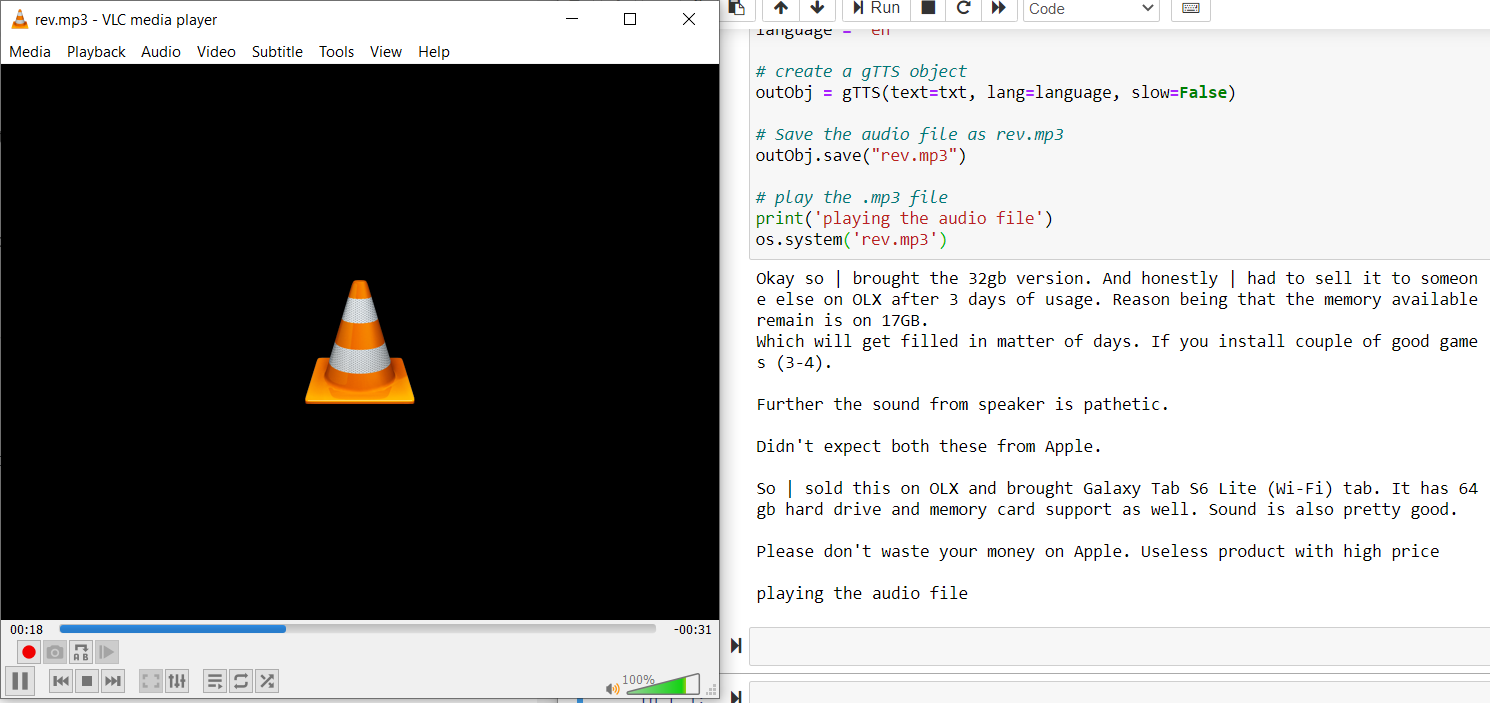
Code complet:
-
importer cv2 importer pytesseract de gtts importer gTTS importer le système d'exploitation rev = cv2.imread("Avis15.PNG") # cv2.imshow("Image", tour) # cv2.waitKey(0) # cv2.destroyAllWindows() txt = pytesseract.image_to_string(tour) imprimer(SMS) langue="dans" outObj = gTTS(texte=txt, lang=langue, lent=Faux) outObj.save("rev.mp3") imprimer('lecture du fichier audio') os.system('rev.mp3')
Remarques finales
A la fin de cet article, nous avons compris le concept de reconnaissance optique de caractères (OCR) et nous sommes habitués à lire des images avec OpenCV et à capturer du texte à partir d'images avec pytesseract. Nous avons vu deux applications OCR de base: construire des nuages de mots, créer des fichiers audibles en convertissant du texte en parole à l'aide de gTTS.
Les références:
J'espère que cet article est informatif et, S'il vous plait, Faites-moi savoir si vous avez des questions ou des commentaires liés à cet article dans la section des commentaires. Bon apprentissage
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





