Cet article a subi une série de changements !!
J'écrivais initialement sur un autre sujet (relacionado con la analytiqueL’analytique fait référence au processus de collecte, Mesurer et analyser les données pour obtenir des informations précieuses qui facilitent la prise de décision. Dans divers domaines, Comme les affaires, Santé et sport, L’analytique peut identifier des modèles et des tendances, Optimiser les processus et améliorer les résultats. L’utilisation d’outils et de techniques statistiques de pointe est essentielle pour transformer les données en connaissances applicables et stratégiques....). j'avais presque fini de l'écrire. j'avais investi environ 2 heures et écrit un article moyen. Si je l'avais fait en direct, j'aurais bien fait! Mais quelque chose en moi m'a empêché de le faire vivre. Je n'étais juste pas satisfait du résultat. L'article ne dit pas ce que je ressens à propos de 2015 et à quel point DataPeaker pourrait être utile pour votre apprentissage analytique cette année.
Ensuite, J'ai mis cet article dans la corbeille et j'ai commencé à repenser quel sujet ferait justice. C'est ce que j'ai fini avec: laissez-moi écrire des articles et des guides incroyables sur ce qui a été mon plus grand apprentissage en 2014: Bibliothèque Scikit-learn ou sklearn en Python. Ce fut mon plus grand apprentissage car c'est maintenant l'outil que j'utilise pour tout projet d'apprentissage automatique sur lequel je travaille.
La création de ces articles serait non seulement extrêmement utile aux lecteurs de blogs, cela me mettrait également au défi d'écrire sur quelque chose pour lequel je suis encore relativement nouveau. J'aimerais aussi avoir de vos nouvelles à propos de la même chose: Quel a été votre plus grand apprentissage en 2014 et vous aimeriez le partager avec les lecteurs de ce blog?
Qu'est-ce que scikit-learn ou sklearn?
Scikit-learn est probablement la bibliothèque la plus utile pour l'apprentissage automatique en Python. La bibliothèque sklearn contient de nombreux outils efficaces pour l'apprentissage automatique et la modélisation statistique, qui incluent la classification, régression, regroupement et réduction de dimensionnalité.
Notez que sklearn est utilisé pour créer des modèles d'apprentissage automatique. Il ne doit pas être utilisé pour lire les données, les manipuler et les résumer. Il y a de meilleures bibliothèques pour ça (par exemple, NumPy, Pandas, etc.)
![]()
Composants de scikit-learn:
Scikit-learn est livré avec de nombreuses fonctionnalités. En voici quelques-uns pour vous aider à comprendre la propagation:
- Algoritmos de enseignement superviséL’apprentissage supervisé est une approche d’apprentissage automatique dans laquelle un modèle est formé à l’aide d’un ensemble de données étiquetées. Chaque entrée du jeu de données est associée à une sortie connue, permettre au modèle d’apprendre à prédire les résultats pour de nouvelles entrées. Cette méthode est largement utilisée dans des applications telles que la classification d’images, Reconnaissance vocale et prédiction de tendances, soulignant son importance dans...: Pensez à n'importe quel algorithme d'apprentissage automatique supervisé dont vous avez entendu parler et il y a de fortes chances qu'il fasse partie de scikit-learn. A partir de modèles linéaires généralisés (par exemple, régression linéaire), machines à vecteurs de soutien (SVM), arbres de décision et méthodes bayésiennes, tous font partie de la boîte à outils scikit-learn. La diffusion des algorithmes d'apprentissage automatique est l'une des principales raisons de la forte utilisation de scikit-learn. J'ai commencé à utiliser scikit pour résoudre des problèmes d'apprentissage supervisé et je le recommanderais également aux personnes qui découvrent scikit / apprentissage automatique.
- Validation croisée: Il existe plusieurs méthodes pour vérifier l'exactitude des modèles surveillés sur des données invisibles à l'aide de sklearn.
- Algorithmes d'apprentissage non supervisé: Encore, il existe une grande variété d'algorithmes d'apprentissage automatique proposés, de la piscine, analyse factorielle, analyse en composantes principales aux réseaux de neurones non supervisés.
- Ensembles de données de jouets multiples: Cela a été utile lors de l'apprentissage de scikit-learn. J'avais appris SAS en utilisant divers ensembles de données académiques (par exemple, l'ensemble de données IRIS, l'ensemble de données sur les prix des logements à Boston). Les avoir à portée de main tout en apprenant une nouvelle bibliothèque a beaucoup aidé..
- Extraction de caractéristiques: Scikit-learn pour extraire des caractéristiques d'images et de texte (par exemple, sac de mots)
Communauté / organisations utilisant scikit-learn:
L'une des principales raisons derrière l'utilisation d'outils open source est la grande communauté qu'il a. Il en va de même pour sklearn aussi. Il y a autour de 35 contributeurs scikit-learn à ce jour, le plus notable est Andreas Mueller (PS Andy aide-mémoire pour l'apprentissage automatique est l'une des meilleures visualisations pour comprendre le spectre des algorithmes d'apprentissage automatique).
Il existe plusieurs organisations comme Evernote, Inria et AWeber présentés dans scikit apprendre page d'accueil en tant qu'utilisateurs. Mais je pense vraiment que l'utilisation réelle est beaucoup plus.
En plus de ces communautés, il y a plusieurs réunions dans le monde. Il y avait aussi un Concours de connaissances Kaggle, qui s'est terminé récemment, mais c'est peut-être encore l'un des meilleurs endroits pour commencer à jouer avec la bibliothèque.
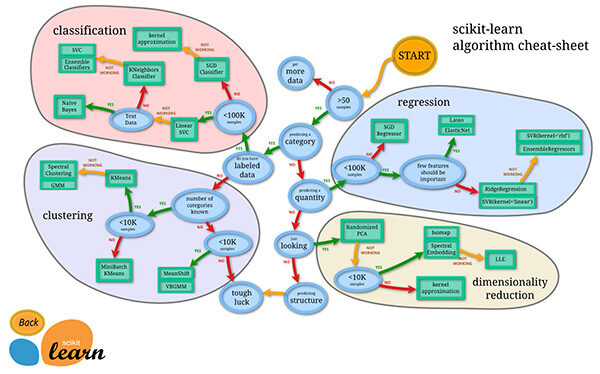
Aide-mémoire sur l'apprentissage automatique: consulte la imagen original para obtener una mejor résolutionLa "résolution" fait référence à la capacité de prendre des décisions fermes et d’atteindre les objectifs fixés.. Dans des contextes personnels et professionnels, Il s’agit de définir des objectifs clairs et d’élaborer un plan d’action pour les atteindre. La résolution est essentielle à la croissance personnelle et à la réussite dans divers domaines de la vie, car cela vous permet de surmonter les obstacles et de rester concentré sur ce qui compte vraiment....
Exemple rapide:
Maintenant que vous comprenez l'écosystème à un niveau élevé, permettez-moi d'illustrer l'utilisation de sklearn avec un exemple. L'idée est simplement d'illustrer la simplicité d'utilisation de sklearn. Nous examinerons divers algorithmes et les meilleures façons de les utiliser dans l'un des articles qui suivent..
Nous allons construire une régression logistique sur le jeu de données IRIS:
Paso 1: importer les bibliothèques pertinentes et lire l'ensemble de données
importer numpy en tant que np
importer matplotlib en tant que plt
à partir de jeux de données d'importation sklearn
des métriques d'importation sklearn
de sklearn.linear_model import LogisticRegression
Nous avons importé toutes les bibliothèques. Ensuite, nous lisons l'ensemble de données:
ensemble de données = ensembles de données.load_iris ()
Paso 2: Comprendre l'ensemble de données en examinant les distributions et les diagrammes
Je saute ces étapes pour l'instant. Vous pouvez lire cet article si vous voulez apprendre l'analyse exploratoire.
Paso 3: construire un modèle de régression logistique sur l'ensemble de données et faire des prédictions
model.fit (base de donnéesUn "base de données" ou ensemble de données est une collection structurée d’informations, qui peut être utilisé pour l’analyse statistique, Apprentissage automatique ou recherche. Les ensembles de données peuvent inclure des variables numériques, catégorique ou textuelle, Et leur qualité est cruciale pour des résultats fiables. Son utilisation s’étend à diverses disciplines, comme la médecine, Économie et sciences sociales, faciliter la prise de décision éclairée et l’élaboration de modèles prédictifs.....Les données, dataset.target)
attendu = dataset.target
prédit = model.predict (dataset.data)
Paso 4: Imprimer la matrice de confusion
imprimer (metrics.classification_report (attendu, prédit))
imprimer (metrics.confusion_matrix (attendu, prédit))
Remarques finales:
Il s'agissait d'un aperçu de l'une des bibliothèques d'apprentissage automatique les plus puissantes et les plus polyvalentes de Python.. C'était aussi le plus grand apprentissage que j'ai fait en 2014. Quel a été votre plus grand apprentissage en 2014? Partagez-le avec le groupe à travers les commentaires ci-dessous.
Êtes-vous impatient d'apprendre et d'utiliser Scikit-learn? Le cas échéant, restez à l'écoute pour les autres articles de cette série.
Un petit rappel: si vous n'avez pas vérifié Vidhya analytique Discuter cependant, tu devrais le faire maintenant. Les utilisateurs rejoignent rapidement, alors prenez le nom d'utilisateur que vous voulez avant que quelqu'un d'autre ne le récupère.





