Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
La science des données est un domaine émergent avec de nombreuses opportunités d’emploi. Nous devons tous avoir entendu parler des meilleures compétences en science des données. Pour commencer, la compétence la plus simple et la plus essentielle que tout aspirant à la science des données devrait acquérir est SQL.
Aujourd'hui, La plupart des entreprises sont axées sur les données. Estos datos se almacenan en una base de donnéesUne base de données est un ensemble organisé d’informations qui vous permet de stocker, Gérez et récupérez efficacement les données. Utilisé dans diverses applications, Des systèmes d’entreprise aux plateformes en ligne, Les bases de données peuvent être relationnelles ou non relationnelles. Une bonne conception est essentielle pour optimiser les performances et garantir l’intégrité de l’information, facilitant ainsi la prise de décision éclairée dans différents contextes.... y se gestionan y procesan a través de un sistema de gestión de bases de datos. Le SGBD rend notre travail si facile et organisé. Donc, il est essentiel d’intégrer le langage de programmation le plus populaire avec l’incroyable outil SGBD.
SQL est le langage de programmation le plus utilisé lors du travail avec des bases de données et est compatible avec divers systèmes de bases de données relationnelles, comme MySQL, SQL Server et Oracle. Cependant, La norme SQL possède certaines fonctionnalités qui sont implémentées différemment dans différents systèmes de base de données. Pourtant, SQL devient l’un des concepts les plus importants à apprendre dans ce domaine de la science des données.
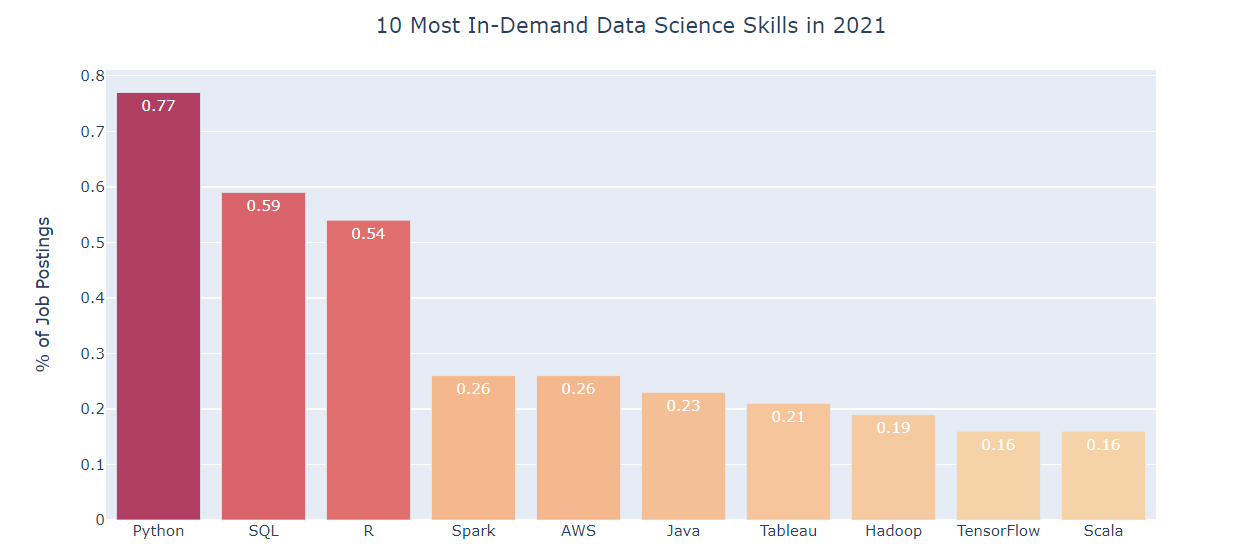
Source de l'image: KDnuggets
Besoin de SQL dans la science des données
SQL (Langage de requête structuré) Utilisé pour effectuer diverses opérations sur des données stockées dans des bases de données, Comment mettre à jour les enregistrements, suppression d’enregistrements, Créer et modifier des tables, Affichage, etc. SQL est également la norme pour les plates-formes Big Data d’aujourd’hui qui utilisent SQL comme API clé pour leurs bases de données relationnelles..
La science des données est l’étude complète des données. Pour travailler avec des données, Nous devons les extraire de la base de données. C’est là que SQL entre en jeu. La gestion des bases de données relationnelles est un élément crucial de la science des données. Un data scientist peut contrôler, définir, manipuler, créer et interroger la base de données à l’aide de commandes SQL.
De nombreuses industries modernes ont équipé la gestion des données de leurs produits avec la technologie NoSQL., mais SQL reste le choix idéal pour de nombreux outils de Business Intelligence et opérations bureautiques.
De nombreuses plates-formes de base de données sont basées sur SQL. C’est pourquoi il est devenu un standard pour de nombreux systèmes de base de données.. Systèmes Big Data modernes comme Hadoop, Spark utilise également SQL uniquement pour maintenir les systèmes de bases de données relationnelles et traiter les données structurées.
Nous pouvons dire que:
1. Un data scientist a besoin de SQL pour gérer des données structurées. Stockage des données structurées dans les bases de données relationnelles. Donc, Pour interroger ces bases de données, un data scientist doit avoir une bonne connaissance des commandes SQL.
Les plates-formes Big Data telles que Hadoop et Spark fournissent une extension pour interroger à l’aide de commandes SQL pour manipuler.
3.SQL est l’outil standard pour expérimenter avec les données en créant des environnements de test.
4. Pour effectuer des opérations analytiques avec des données stockées dans des bases de données relationnelles telles qu’Oracle, Microsoft SQL, MySQL, nous avons besoin de SQL.
5. SQL est également un outil essentiel pour la préparation et le traitement des données. Donc, lorsqu’il s’agit de divers outils Big Data, nous utilisons SQL.
Éléments clés de SQL pour la science des données
Vous trouverez ci-dessous les principaux aspects de SQL les plus utiles pour la science des données. Tous les aspirants scientifiques des données doivent être conscients de ces compétences et fonctionnalités SQL nécessaires..
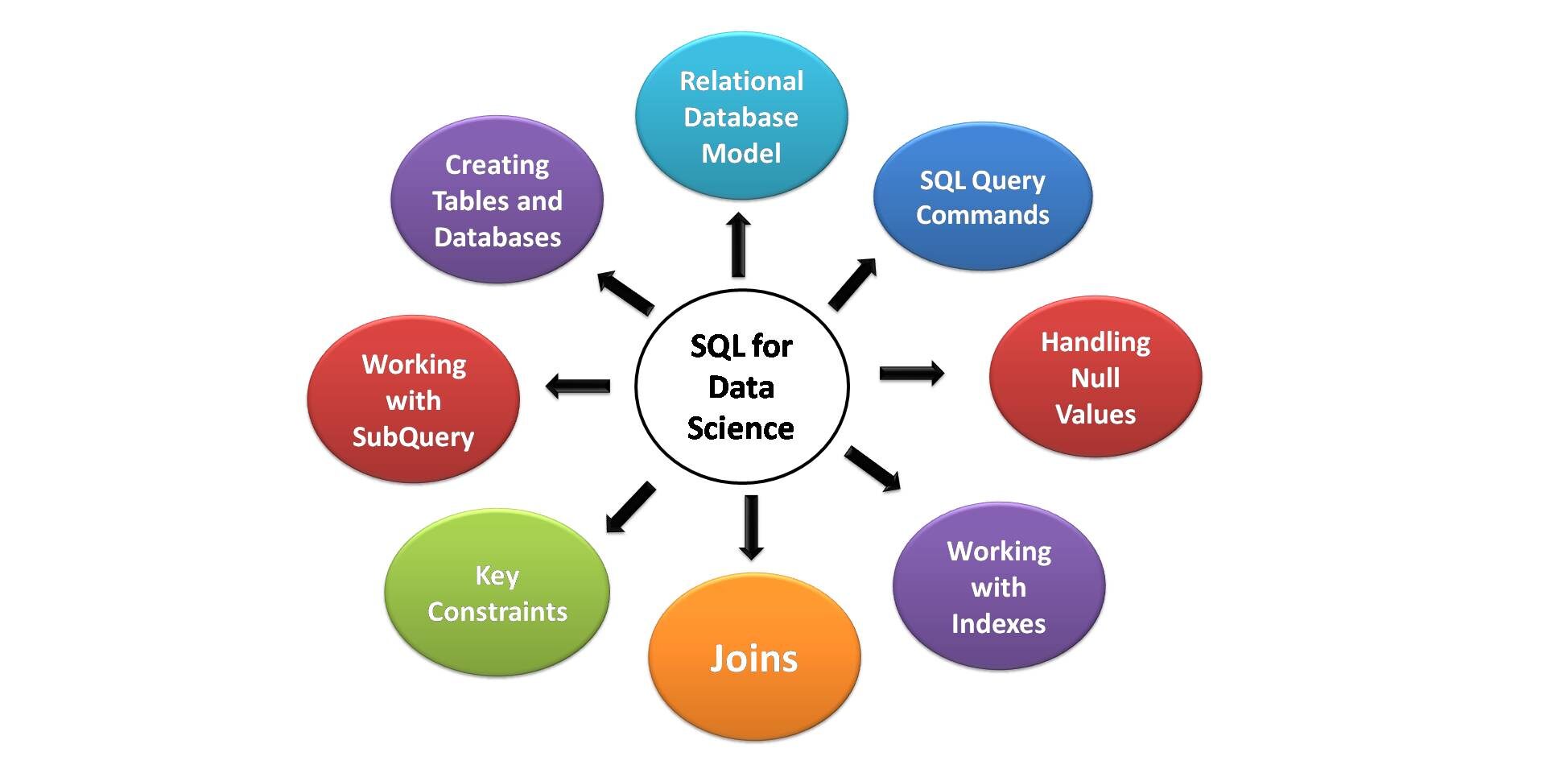
Source de l'image: Pour moi
Introduction à SQL avec Python
Comme nous le savons tous, SQL est l’outil de gestion de base de données le plus utilisé et Python est le langage de science des données le plus populaire pour sa flexibilité et son large éventail de bibliothèques.. Il existe plusieurs façons d’utiliser SQL avec Python. Python fournit plusieurs bibliothèques qui sont développées et peuvent être utilisées à cette fin. SQLite, PostgreSQL, et MySQL sont des exemples de ces bibliothèques.
Pourquoi utiliser SQL avec Python
Il existe de nombreux cas d’utilisation où les scientifiques des données veulent connecter Python à SQL. Les scientifiques des données doivent connecter une base de données SQL afin de stocker les données provenant de l’application Web. Il aide également à communiquer entre différentes sources de données.
Pas besoin de basculer entre différents langages de programmation pour la gestion des données. Rend le travail des scientifiques des données plus pratique. Ils seront en mesure d’utiliser leurs compétences Python pour manipuler des données stockées dans une base de données SQL. Ils n’ont pas besoin d’un fichier CSV.
MySQL avec Python
MySQL est un système de gestion de base de données basé sur serveur. Un serveur MySQL peut avoir plusieurs bases de données. Une base de données MySQL est un processus en deux étapes pour créer une base de données:
1. Établir une connexion à un serveur MySQL.
2. Exécuter des requêtes distinctes pour créer la base de données et traiter les données.
Commençons par MySQL avec Python
Premier, nous allons créer une connexion entre le serveur MySQL et la base de données MySQL. Pour cela, nous allons définir une fonction qui établira une connexion au serveur de base de données MySQL et retournera l’objet de connexion:
!pip installer mysql-connector-python
import mysql.connector
from mysql.connector import Error
def create_connection(host_name, user_name, user_password):
connection = None
try:
connexion = mysql.connector.connect(
host=host_name,
utilisateur=user_name,
passwd=user_password
)
imprimer("Connexion à la base de données MySQL réussie")
sauf Erreur en tant que e:
imprimer(F"L’erreur '{e}' s’est produit")
return connection
connection = create_connection("hôte local", "racine", "")
Dans le code ci-dessus, Nous avons défini une fonction create_connection () que acepta los siguientes tres paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet....:
1. nombre_host
2. nom d'utilisateur
3. Mot de passe de l’utilisateur
Mysql.connector est un module Python SQL qui contient une méthode .connect () qui est utilisé pour se connecter à un serveur de base de données MySQL. Lorsque la connexion est établie, L’objet de connexion créé sera renvoyé à la fonction appelante.
Jusqu'à maintenant, La connexion a été établie avec succès, Créons maintenant une base de données.
#we have created a function to create database that contions two parameters #connection and query defcreate_database(connexion,mettre en doute): #nous créons maintenant un curseur d’objet pour exécuter le curseur des requêtes SQL=connexion.curseur() essayer: #La requête à exécuter sera transmise dans cursor.execute() sous forme de chaîne cursor.execute(mettre en doute) imprimer("Base de données créée avec succès") saufErreurcommee: imprimer(F"L’erreur '{e}' s’est produit")
#now we are creating a database named example_app create_database_query="CRÉER UNE BASE DE DONNÉES example_app" create_database(connexion,create_database_query)
#now will create database example_app on database server #and also cretae connection between database and server defcreate_connection(host_name,user_name,user_password,db_name): connexion=Aucun essai: connexion=mysql.connector.connect( host=host_name, utilisateur=user_name, passwd=user_password, base de données=db_name ) imprimer("Connexion à la base de données MySQL réussie") saufErreurcommee: imprimer(F"L’erreur '{e}' s’est produit") revenirconnexion
#En appelant lecreate_connection()et se connecte auexample_appBase de données. connexion=create_connection("hôte local","racine","","example_app")
SQLite
SQLite est probablement la base de données la plus simple que nous puissions connecter à une application Python, car il s’agit d’un module intégré, nous n’avons pas besoin d’installer de modules Python SQL externes. Par défaut, L’installation Python contient une bibliothèque SQL Python nommée SQLITE3 qui peut être utilisée pour interagir avec une base de données SQLite.
SQLite est une base de données sans serveur. Lit et écrit des données dans un fichier. Cela signifie que nous n’avons même pas besoin d’installer et d’exécuter un serveur SQLite pour effectuer des opérations de base de données comme MySQL et PostgreSQL!!
Utilisons sqlite3 pour se connecter à une base de données SQLite en Python:
importersqlite3 à partir desqlite3importerErreur
défcreate_connection(chemin): connexion=Aucun essai: connexion=sqlite3.connect(chemin) imprimer("Connexion à SQLite DB réussie")
saufErreurcommee: imprimer(F"L’erreur '{e}' s’est produit") revenirconnexion
Dans le code ci-dessus, Nous avons importé sqlite3 et la classe d’erreur du module. Définissez ensuite une fonction appelée .create_connection () qui acceptera le chemin d’accès à la base de données SQLite. Puis .connect () du module sqlite3 prendra le chemin de la base de données SQLite comme paramètre. Si la base de données existe dans le chemin spécifié dans .connect, Une connexion à la base de données sera établie. Au contraire, Une nouvelle base de données est créée au niveau du chemin spécifié, puis une connexion est établie.
sqlite3.connect (route) retournera un objet de connexion, qui a également été restitué par create_connection (). Cet objet de connexion sera utilisé pour exécuter des requêtes SQL sur une base de données SQLite. La ligne de code suivante créera une connexion à la base de données SQLite:
connexion=create_connection("E:example_app.sqlite")
Une fois la connexion établie, nous pouvons voir que le fichier de base de données est créé dans le répertoire racine et si nous le voulons, Nous pouvons également modifier l’emplacement du fichier.
Dans cet article, Nous avons discuté de la façon dont SQL est essentiel pour la science des données et aussi comment nous pouvons travailler avec SQL en utilisant Python. Merci pour la lecture. Faites-moi part de vos commentaires et suggestions dans la section commentaires.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





