Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
Traitement du langage naturel (PNL) est un domaine où convergent intelligence artificielle et linguistique. L'objectif est de faire comprendre aux ordinateurs le langage du monde réel ou le langage naturel afin qu'ils puissent effectuer des tâches en réponse à des questions., traduction de langue et bien d'autres.
La PNL a de nombreuses applications dans différents domaines.
1. La PNL permet la reconnaissance et la prédiction des maladies sur la base des dossiers médicaux électroniques.
2. Utilisé pour obtenir les commentaires des clients.
3. Pour aider à identifier les fausses nouvelles.
4. Chatbots.
5. Veille des réseaux sociaux, etc.
Qu'est-ce qu'un transformateur?
L'architecture du modèle Transformer a été présentée par Ashish Vaswani, Noam shazeer, Niki Parmar, Jakob Razoreit, Lion Jones, Aidan N. Gomez, Lukasz Kaiser e Illia Polosukhin en su artículo « L'attention est tout ce dont vous avez besoin ». [1]
Le modèle Transformer extrait les caractéristiques de chaque mot en utilisant un mécanisme d'auto-attention pour connaître l'importance de chaque mot dans la phrase. Aucune autre unité récurrente n'est utilisée pour extraire cette fonctionnalité, ce ne sont que des activations et des sommes pondérées, ils peuvent donc être très efficaces et parallélisables.
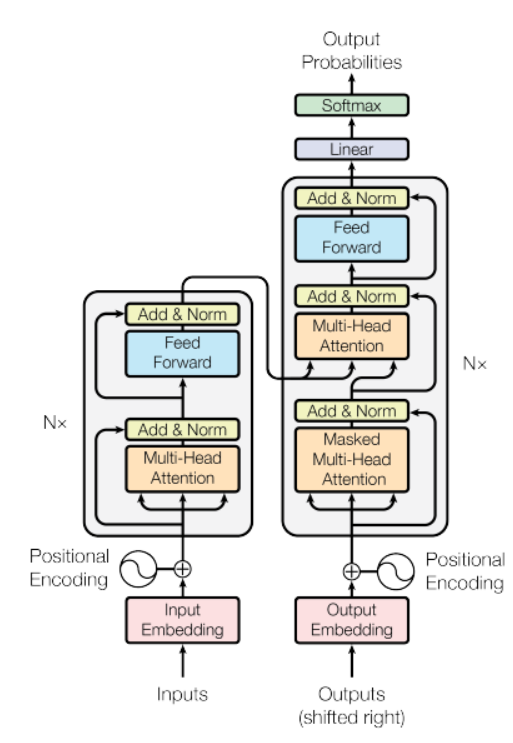
La source: document « L'attention est tout ce dont vous avez besoin »
Dans le chiffre"Chiffre" est un terme utilisé dans divers contextes, De l’art à l’anatomie. Dans le domaine artistique, fait référence à la représentation de formes humaines ou animales dans des sculptures et des peintures. En anatomie, désigne la forme et la structure du corps. En outre, en mathématiques, "chiffre" Il est lié aux formes géométriques. Sa polyvalence en fait un concept fondamental dans de multiples disciplines.... antérieur, il y a un modèle d'encodeur sur le côté gauche et le décodeur sur la droite. L'encodeur et le décodeur contiennent tous deux un bloc central de attention et un réseau de rétroaction répété N nombre de fois.
Dans la figure ci-dessus, il y a un modèle d'encodeur sur le côté gauche et le décodeur sur la droite. L'encodeur et le décodeur contiennent tous deux un bloc d'attention central et un réseau de rétroaction répété N nombre de fois.
A une pile de 6 encodeurs et 6 décodeurs, l'encodeur contient deux couches (sous-couches), c'est-à-dire, une couche d'autosoins multi-têtes et un réseau d'alimentation directe entièrement connecté. Le décodeur contient trois couches (sous-couches), une couche d'autosoins multi-têtes, une autre couche d'auto-soins multi-têtes pour effectuer des auto-soins sur les sorties d'encodeur et un réseau d'alimentation directe entièrement connecté. Cada subcapa en Decoder y Encoder tiene una conexión residual con standardisationLa normalisation est un processus fondamental dans diverses disciplines, qui vise à établir des normes et des critères uniformes afin d’améliorer la qualité et l’efficacité. Dans des contextes tels que l’ingénierie, Formation et administration, La standardisation facilite la comparaison, Interopérabilité et compréhension mutuelle. Lors de la mise en œuvre des normes, La cohésion est favorisée et les ressources sont optimisées, qui contribue au développement durable et à l’amélioration continue des processus.... de capa.
Commençons à créer un modèle de traduction linguistique
Ici, nous utiliserons le jeu de données Multi30k. Ne t'inquiète pas, l'ensemble de données sera téléchargé avec un extrait de code.
Premier, la partie traitement des données, nous utiliserons le Torche Module PyTorch. Les Torche a des utilitaires pour créer des ensembles de données qui peuvent être facilement itérés afin de créer un modèle de traduction linguistique. Le code suivant téléchargera l'ensemble de données et marquera également un texte brut, construirá el vocabulario y convertirá tokens en un tensorLos tensores son estructuras matemáticas que generalizan conceptos como scalars y vectores. Se utilizan en diversas disciplinas, incluyendo física, ingeniería y aprendizaje automático, para representar datos multidimensionales. Un tensor puede ser visualizado como una matriz de múltiples dimensiones, lo que permite modelar relaciones complejas entre diferentes variables. Su versatilidad y capacidad para manejar grandes volúmenes de información los convierten en herramientas fundamentales en el análisis y procesamiento de datos.....
importer des mathématiques importer le texte de la torche torche d'importation importer torch.nn en tant que nn de torchtext.data.utils importer get_tokenizer des collections import compteur de torchtext.vocab importer Vocab de torchtext.utils importer download_from_url, extraire_archive de torch.nn.utils.rnn importer pad_sequence de torch.utils.data importer DataLoader de la torche importer Tensor de torch.nn importer (TransformerEncoder, TransformateurDécodeur,TransformerEncoderLayer, TransformerDecoderLayer) importer io heure d'importation
url_base="https://raw.githubusercontent.com/multi30k/dataset/master/data/task1/raw/"
train_urls = ('train.de.gz', 'train.en.gz')
val_urls = ('val.de.gz', 'val.fr.gz')
test_urls = ('test_2016_flickr.de.gz', 'test_2016_flickr.en.gz')
train_filepaths = [extraire_archive(download_from_url(url_base + URL))[0] pour l'url dans train_urls]
val_filepaths = [extraire_archive(download_from_url(url_base + URL))[0] pour l'url dans val_urls]
test_filepaths = [extraire_archive(download_from_url(url_base + URL))[0] pour l'url dans test_urls]
de_tokenizer = get_tokenizer('espace', langue="de_core_news_sm")
en_tokenizer = get_tokenizer('espace', langue="en_core_web_sm")
def build_vocab(chemin du fichier, tokenizer):
compteur = compteur()
avec io.open(chemin du fichier, encodage="utf8") comme f:
pour string_ en f:
compteur.update(tokenizer(chaîne de caractères_))
retour Vocab(contrer, spéciaux=['<unk>', '<tampon>', '<groupe>', '<eos>'])
de_vocab = build_vocab(train_filepaths[0], de_tokenizer)
en_vocab = build_vocab(train_filepaths[1], en_tokenizer)
def data_process(chemins de fichiers):
raw_de_iter = iter(io.open(chemins de fichiers[0], encodage="utf8"))
raw_en_iter = iter(io.open(chemins de fichiers[1], encodage="utf8"))
données = []
pour (raw_de, raw_fr) en zip(raw_de_iter, raw_en_iter):
de_tenseur_ = torche.tenseur([de_vocab[jeton] pour le jeton dans de_tokenizer(raw_de.rstrip("m"))],
dtype=torche.long)
en_tenseur_ = torche.tenseur([en_vocab[jeton] pour le jeton dans en_tokenizer(raw_en.rstrip("m"))],
dtype=torche.long)
data.append((de_tenseur_, en_tenseur_))
renvoyer des données
train_data = data_process(train_filepaths)
val_data = data_process(val_filepaths)
test_data = data_process(test_filepaths)
appareil = torche.appareil('cuda' si torch.cuda.is_available() sinon 'cpu')
TAILLE_LOT = 128
PAD_IDX = de_vocab['<tampon>']
BOS_IDX = de_vocab['<groupe>']
EOS_IDX = de_vocab['<eos>']
Ensuite, nous utiliserons le module PyTorch DataLoader qui combine un jeu de données et un échantillonneur, et nous permet d'itérer sur l'ensemble de données donné. Le DataLoader prend en charge les ensembles de données itérables et de style carte avec un chargement simple ou multithread, nous pouvons également personnaliser l'ordre de chargement et la fixation de la mémoire.
# DataLoader
def generate_batch(data_batch):
de_batch, en_batch = [], []
pour (de_item, fr_item) dans data_batch:
de_batch.append(torche.chat([torche.tenseur([BOS_IDX]), de_item, torche.tenseur([EOS_IDX])], dim=0))
en_batch.append(torche.chat([torche.tenseur([BOS_IDX]), fr_item, torche.tenseur([EOS_IDX])], dim=0))
de_batch = pad_sequence(de_batch, padding_value=PAD_IDX)
en_batch = pad_sequence(en_batch, padding_value=PAD_IDX)
retour de_batch, en_batch
train_iter = DataLoader(train_données, batch_size=BATCH_SIZE, shuffle=Vrai, collate_fn=generate_batch) valid_iter = DataLoader(val_data, batch_size=BATCH_SIZE, shuffle=Vrai, collate_fn=generate_batch) test_iter = DataLoader(données de test, batch_size=BATCH_SIZE, shuffle=Vrai, collate_fn=generate_batch)
Nous concevons donc le transformateur. Ici, l'encodeur traite le flux d'entrée en le propageant à travers une série de couches de réseau de soins multi-têtes à anticipation. La sortie de cet encodeur est appelée mémoire ci-dessous et est transmise au décodeur avec les tenseurs cibles. L'encodeur et le décodeur sont formés de bout en bout.
# transformateur
classe Seq2SeqTransformer(nn.Module):
def __init__(soi, num_encoder_layers: entier, num_decoder_layers: entier,
taille_emb: entier, src_vocab_size: entier, tgt_vocab_size: entier,
dim_feedforward:entier = 512, abandonner:flotteur = 0.1):
super(Transformateur Seq2Seq, soi).__init__()
encoder_layer = TransformerEncoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_encoder = TransformerEncoder(encoder_layer, num_layers=num_encoder_layers)
decoder_layer = TransformerDecoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_decoder = TransformerDecoder(couche_décodeur, num_layers=num_decoder_layers)
self.générateur = nn.Linéaire(taille_emb, tgt_vocab_size)
self.src_tok_emb = Intégration de jetons(src_vocab_size, taille_emb)
self.tgt_tok_emb = Intégration de jetons(tgt_vocab_size, taille_emb)
self.positional_encoding = PositionalEncoding(taille_emb, abandon = abandon)
def vers l'avant(soi, src: Tenseur, trg: Tenseur, masque_src: Tenseur,
tgt_mask: Tenseur, src_padding_mask: Tenseur,
tgt_padding_mask: Tenseur, memory_key_padding_mask: Tenseur):
src_emb = self.positional_encoding(self.src_tok_emb(src))
target_emb = self.positional_encoding(self.tgt_tok_emb(trg))
mémoire = self.transformer_encoder(src_emb, masque_src, src_padding_mask)
outs = self.transformer_decoder(objectif_emb, Mémoire, tgt_mask, Rien,
tgt_padding_mask, memory_key_padding_mask)
retourner self.generator(sorties)
def encoder(soi, src: Tenseur, masque_src: Tenseur):
retourner self.transformer_encoder(self.positional_encoding(
self.src_tok_emb(src)), masque_src)
def décoder(soi, objectif: Tenseur, Mémoire: Tenseur, tgt_mask: Tenseur):
retourner self.transformer_decoder(self.positional_encoding(
self.tgt_tok_emb(objectif)), Mémoire,
tgt_mask)
Le texte converti en jetons est représenté par des intégrations de jetons. La fonction d'encodage positionnel est ajoutée à l'incorporation de jetons afin que nous puissions obtenir les notions d'ordre des mots.
classe PositionalEncoding(nn.Module):
def __init__(soi, taille_emb: entier, abandonner, maxlen: entier = 5000):
super(Codage positionnel, soi).__init__()
den = torche.exp(- torche.arange(0, taille_emb, 2) * math.log(10000) / taille_emb)
pos = torche.arange(0, maxlen).remodeler(maxlen, 1)
pos_embedding = torche.zeros((maxlen, taille_emb))
pos_embedding[:, 0::2] = torche.péché(position * les)
pos_embedding[:, 1::2] = torche.cos(position * les)
pos_embedding = pos_embedding.unsqueeze(-2)
self.dropout = nn.Dropout(abandonner)
self.register_buffer('pos_embedding', pos_embedding)
def vers l'avant(soi, jeton_embedding: Tenseur):
retour self.dropout(jeton_embedding +
self.pos_embedding[:jeton_embedding.size(0),:])
classe TokenEmbedding(nn.Module):
def __init__(soi, vocab_size: entier, taille_emb):
super(JetonIncorporation, soi).__init__()
self.embedding = nn.Embedding(vocab_size, taille_emb)
self.emb_size = emb_size
def vers l'avant(soi, jetons: Tenseur):
retour self.embedding(jetons.long()) * math.sqrt(self.emb_size)
Ici, dans le code ci-dessous, un masque de mot suivant est créé pour empêcher un mot cible de prêter attention à ses mots suivants. Les masques sont également créés ici, pour masquer les jetons de remplissage source et destination.
def generate_square_subsequent_mask(sz):
masque = (torche.triu(torche.unes((sz, sz), appareil=APPAREIL)) == 1).transposer(0, 1)
masque = masque.float().masked_fill(masque == 0, flotter('-inf')).masked_fill(masque == 1, flotter(0.0))
masque de retour
def create_mask(src, objectif):
src_seq_len = src.forme[0]
cible_seq_len = cible.forme[0]
tgt_mask = generate_square_subsequent_mask(cible_seq_len)
src_mask = torche.zeros((src_seq_len, src_seq_len), appareil=APPAREIL).taper(torche.bool)
src_padding_mask = (src == PAD_IDX).transposer(0, 1)
tgt_padding_mask = (objectif == PAD_IDX).transposer(0, 1)
retourner src_mask, tgt_mask, src_padding_mask, tgt_padding_mask
Luego defina los paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... del modelo y cree una instancia del modelo.
SRC_VOCAB_SIZE = longueur(de_vocab)
TGT_VOCAB_SIZE = longueur(en_vocab)
EMB_SIZE = 512
NHEAD = 8
FFN_HID_DIM = 512
TAILLE_LOT = 128
NUM_ENCODER_LAYERS = 3
NUM_DECODER_LAYERS = 3
NUM_EPOCHS = 50
APPAREIL = torche.appareil('miracles:0' si torch.cuda.is_available() sinon 'cpu')
transformateur = Seq2SeqTransformer(NUM_ENCODER_LAYERS, NUM_DECODER_LAYERS,
EMB_SIZE, SRC_VOCAB_SIZE, TGT_VOCAB_SIZE,
FFN_HID_DIM)
pour p dans transformateur.paramètres():
si p.dim() > 1:
nn.init.xavier_uniform_(p)
transformateur = transformateur.à(dispositif)
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
optimiseur = torche.optim.Adam(
paramètres.du.transformateur(), lr=0,0001, bêta=(0.9, 0.98), EPS = 1er-9e
)
Définir deux fonctions différentes, c'est-à-dire, pour la formation et l'évaluation.
def train_epoch(maquette, train_iter, optimiseur):
modèle.train()
pertes = 0
pour idx, (src, objectif) en énumérer(train_iter):
src = src.to(dispositif)
objectif = objectif.à(dispositif)
cible_entrée = cible[:-1, :]
masque_src, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = modèle(src, tgt_input, masque_src, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
optimiseur.zero_grad()
cible_sortie = cible[1:, :]
perte = perte_fn(logits.reshape(-1, logits.forme[-1]), tgt_out.reshape(-1))
perte.en arrière()
optimiseur.étape()
pertes += perte.item()
torche.sauvegarder(maquette, CHEMIN)
pertes de retour / longueur(train_iter)
def évaluer(maquette, val_iter):
modèle.eval()
pertes = 0
pour idx, (src, objectif) dans (énumérer(valid_iter)):
src = src.to(dispositif)
objectif = objectif.à(dispositif)
cible_entrée = cible[:-1, :]
masque_src, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = modèle(src, tgt_input, masque_src, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
cible_sortie = cible[1:, :]
perte = perte_fn(logits.reshape(-1, logits.forme[-1]), tgt_out.reshape(-1))
pertes += perte.item()
pertes de retour / longueur(val_iter)
Maintenant, entraînez le modèle.
pour l'époque dans la gamme(1, NUM_EPOCHS+1):
heure_départ = heure.heure()
train_loss = train_epoch(transformateur, train_iter, optimiseur)
heure_fin = heure.heure()
val_loss = évaluer(transformateur, valid_iter)
imprimer((F"Époque: {époque}, Perte de train: {train_loss:.3F}, perte de valeur: {perte_val:.3F}, "
F"Temps d'époque = {(heure de fin - Heure de début):.3F}s"))
Ce modèle est entraîné à l'aide d'une architecture de transformateur de manière à ce qu'il s'entraîne plus rapidement et converge également vers une perte de validation inférieure par rapport aux autres modèles RNN..
def gourmand_decode(maquette, src, masque_src, max_len, start_symbol):
src = src.to(dispositif)
src_mask = src_mask.to(dispositif)
mémoire = model.encode(src, masque_src)
ys = torch.ones(1, 1).remplir_(start_symbol).taper(torche.long).à(dispositif)
pour moi à portée(max_len-1):
mémoire = mémoire.à(dispositif)
memory_mask = torch.zeros(ys.forme[0], mémoire.forme[0]).à(dispositif).taper(torche.bool)
tgt_mask = (generate_square_subsequent_mask(ys.taille(0))
.taper(torche.bool)).à(dispositif)
out = model.decode(oui, Mémoire, tgt_mask)
out = out.transpose(0, 1)
prob = modèle.générateur(dehors[:, -1])
_, mot_suivant = torche.max(prob, faible = 1)
mot_suivant = mot_suivant.item()
ys = torche.cat([oui,
torche.unes(1, 1).type_as(src.data).remplir_(mot_suivant)], dim=0)
si mot_suivant == EOS_IDX:
Pause
retour oui
def traduire(maquette, src, src_vocab, tgt_vocab, src_tokenizer):
modèle.eval()
jetons = [BOS_IDX] + [src_vocab.stoi[a pris] pour tok dans src_tokenizer(src)] + [EOS_IDX]
num_tokens = len(jetons)
src = (torche.LongTensor(jetons).remodeler(num_tokens, 1))
masque_src = (torche.zéros(num_tokens, num_tokens)).taper(torche.bool)
tgt_tokens = greedy_decode(maquette, src, masque_src, max_len=num_tokens + 5, start_symbol=BOS_IDX).aplatir()
revenir " ".rejoindre([tgt_vocab.itos[a pris] pour tok dans tgt_tokens]).remplacer("<groupe>", "").remplacer("<eos>", "")
À présent, Testons notre modèle de traduction.
sortie = traduire(transformateur, "Un groupe de personnes se tient devant un igloo .", de_vocab, en_vocab, de_tokenizer) imprimer(sortir)
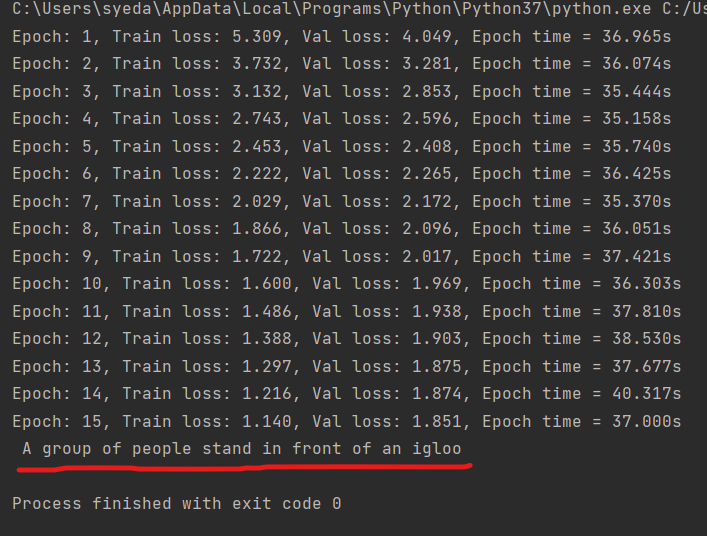
Au-dessus de la ligne rouge se trouve le résultat du modèle de traduction. Vous pouvez également le comparer avec google translate.
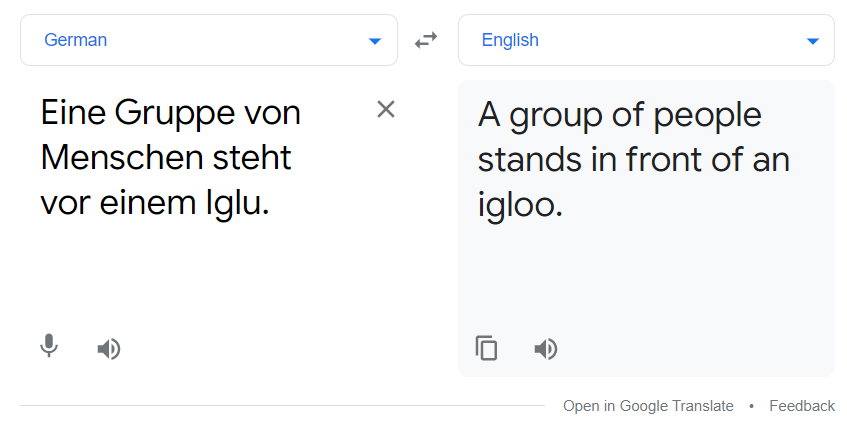
La traduction ci-dessus et la sortie de notre modèle correspondent. Le modèle n'est pas le meilleur, mais ça marche toujours jusqu'à un certain point.
Référence
[1]. Ashish Vaswani, Noam shazeer, Niki Parmar, Jakob Razoreit, Lion Jones, Aidan N. Gomez, Lukasz Kaiser et Illia Polosukhin: l'attention est tout ce dont vous avez besoin, décembre de 2017, EST CE QUE JE: https://arxiv.org/pdf/1706.03762.pdf
Aussi pour plus d'informations, voir https://pytorch.org/tutorials/
Merci
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





