introduction
De temps en temps, une bibliothèque Python est développée qui a le potentiel de changer le paysage dans le domaine de l'apprentissage en profondeur. PyTorch est l'une de ces bibliothèques.
Au cours des dernières semaines, J'ai un peu barboté dans PyTorch. J'ai été impressionné par la facilité de compréhension. Parmi les différents frameworks d'apprentissage en profondeur que j'ai utilisés à ce jour, PyTorch a été le plus flexible et sans effort de tous.
![]()
Dans cet article, nous allons explorer PyTorch avec une approche plus pratique, couvrant les bases avec une étude de cas. Nous comparerons également un réseau de neurones construit à partir de zéro dans numpy et PyTorch pour voir leurs similitudes dans la mise en œuvre..
Allons-nous en!
Noter: cet article suppose que vous avez une compréhension de base de l'apprentissage en profondeur. Si vous voulez rattraper votre retard sur le deep learning, lisez d'abord cet article.
En outre, si vous voulez une explication plus détaillée de PyTorch à partir de zéro, comprendre le fonctionnement des tendeurs, comment vous pouvez effectuer des opérations mathématiques et matricielles avec PyTorch, Je vous recommande fortement de consulter le guide du débutant sur PyTorch et son fonctionnement à partir de zéro..
Table des matières
- Un aperçu de PyTorch
- Plongez dans les détails techniques
- Construire un réseau de neurones dans Numpy vs PyTorch
- Comparaison avec d'autres bibliothèques de deep learning
- Étude de cas: résoudre un problème de reconnaissance d'image avec PyTorch
Si vous préférez aborder les concepts suivants dans un format structuré, Vous pouvez vous inscrire à ce cours gratuit sur PyTorche et les suivre par chapitres.
Un aperçu de PyTorch
Les créateurs de PyTorch disent avoir une philosophie: ils veulent être impératifs. Cela signifie que nous exécutons notre calcul immédiatement. Cela s'intègre parfaitement dans la méthodologie de programmation Python, Quoi nous n'avons pas à attendre que tout le code soit écrit avant de savoir s'il fonctionne ou non. Nous pouvons facilement exécuter une partie du code et l'inspecter en temps réel. Pour moi, en tant que débogueur de réseau neuronal, C'est une bénédiction!
PyTorch est une bibliothèque basée sur Python créée pour offrir une flexibilité en tant que plate-forme de développement d'apprentissage en profondeur. Le workflow PyTorch est ce qui se rapproche le plus de la bibliothèque de calcul scientifique de Python: numpy.
Maintenant je pourrais demander, Pourquoi utiliser PyTorch pour créer des modèles d'apprentissage en profondeur? Je peux énumérer trois choses qui pourraient aider à répondre à cela:
- API facile à utiliser – C'est aussi simple que Python peut l'être.
- Prise en charge de Python – Comme mentionné précédemment, PyTorch s'intègre de manière transparente à la pile de science des données Python. C'est tellement similaire à numpy que vous ne remarquerez peut-être même pas la différence.
- Graphiques de calcul dynamique – Au lieu de graphiques prédéfinis avec des fonctionnalités spécifiques, PyTorch nous fournit un cadre pour créer des graphiques informatiques au fur et à mesure, et nous les changeons même pendant l'exécution. Ceci est utile pour les situations où nous ne savons pas combien de mémoire il faudra pour créer un réseau de neurones..
Certains autres avantages de l'utilisation de PyTorch sont sa prise en charge multiGPU, chargeurs de données personnalisés et préprocesseurs simplifiés.
Depuis son lancement début janvier 2016, de nombreux chercheurs l'ont adopté comme bibliothèque de référence en raison de sa facilité à créer des graphiques nouveaux et même extrêmement complexes. Ayant dit cela, il reste encore du temps avant que PyTorch ne soit adopté par la plupart des professionnels de la science des données en raison de sa nouvelle et “en construction”.
Plongez dans les détails techniques
Avant de plonger dans les détails, voyons le workflow PyTorch.
PyTorch utilise un paradigme impératif / anxieux. C'est-à-dire, chaque ligne de code requise pour créer un graphique définit un composant de ce graphique. Nous pouvons effectuer indépendamment des calculs sur ces composants, avant même que votre graphique ne soit entièrement construit. C'est ce qu'on appelle le “définition par exécution”.

La source: http://pytorch.org/about/
L'installation de PyTorch est assez facile. Vous pouvez suivre les étapes mentionnées dans le documents officiels et exécutez la commande en fonction des spécifications de votre système. Par exemple, c'est la commande que j'ai utilisée en fonction des options que j'ai choisies:
conda installer pytorch torchvision cuda91 -c pytorch
Les principaux éléments que nous devons connaître en commençant avec PyTorch sont:
- Tendeurs PyTorch
- Des opérations mathématiques
- Module d'auto-évaluation
- module Optim et
- module nn
Ensuite, nous allons examiner chacun d'eux en détail.
Tendeurs PyTorch
Les tenseurs ne sont rien de plus que des matrices multidimensionnelles. Les tenseurs dans PyTorch sont similaires aux ndarrays de numpy, avec en plus que les tendeurs peuvent également être utilisés sur un GPU. Compatible PyTorch divers types de tendeurs. Si vous connaissez d'autres frameworks d'apprentissage en profondeur, doit avoir également trouvé des tenseurs dans TensorFlow. En réalité, vous pouvez également implémenter les tâches suivantes dans Tensorflow et faire votre propre comparaison entre PyTorch et TensorFlow.
Vous pouvez définir un simple tableau à une dimension comme indiqué ci-dessous:
# importer une torche torche d'importation # définir un tenseur torche.FloatTensor([2])
2 [torche.FloatTensor de taille 1]
Des opérations mathématiques
Comme avec numpy, il est très important qu'une bibliothèque de calcul scientifique ait des implémentations efficaces de fonctions mathématiques. PyTorch vous propose une interface similaire, avec plus de 200 des opérations mathématiques vous pouvez utiliser.
Vous trouverez ci-dessous un exemple d'une opération d'addition simple dans PyTorch:
a = torche.FloatTensor([2]) b = torche.FloatTensor([3]) une + b
5 [torche.FloatTensor de taille 1]
Cela ne semble-t-il pas être une approche Python kinessentiel? Nous pouvons également effectuer diverses opérations matricielles sur les tenseurs PyTorch que nous définissons. Par exemple, nous allons transposer une matrice à deux dimensions:
matrice = torche.randn(3, 3) matrice 0.7162 1.0152 1.1525 -0.3503 -0.9452 -1.0861 -0.1093 -0.0927 -0.0476 [torche.FloatTensor de taille 3x3] matrice.t() 0.7162 -0.3503 -0.1093 1.0152 -0.9452 -0.0927 1.1525 -1.0861 -0.0476 [torche.FloatTensor de taille 3x3]
Module d'auto-évaluation
PyTorch utilise une technique appelée différenciation automatique. C'est-à-dire, nous avons un enregistreur qui enregistre les opérations que nous avons effectuées puis les rejoue pour calculer nos gradients. Cette technique est particulièrement puissante lors de la construction de réseaux de neurones, puisque nous gagnons du temps dans une époque lors du calcul de la différenciation des paramètres dans la passe directe.
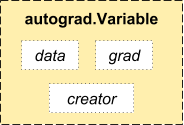
La source: http://pytorch.org/about/
de torch.autograd importation Variable x = variable(train_x) y = Variable(train_y, require_grad=Faux)
Module optimal
torch.optim est un module qui implémente divers algorithmes d'optimisation utilisés pour construire des réseaux de neurones. La plupart des méthodes les plus couramment utilisées sont déjà prises en charge, nous n'avons donc pas à les créer à partir de zéro (Sauf si vous voulez!).
Ci-dessous le code pour utiliser un optimiseur Adam:
optimiseur = torche.optim.Adam(model.paramètres(), lr=taux_apprentissage)
module nn
PyTorche autograd permet de définir facilement des graphiques de calcul et de prendre des dégradés, mais l'autograd brut peut être un niveau trop bas pour définir des réseaux neuronaux complexes. C'est là que le module nn peut vous aider.
Le package nn définit un ensemble de modules, que nous pouvons considérer comme une couche de réseau neuronal qui produit une sortie à partir de l'entrée et peut avoir des poids pouvant être entraînés.
Vous pouvez considérer un module nn comme le dur de PyTorch!
torche d'importation # définir le modèle modèle = torche.nn.Séquentiel( torche.nn.Linéaire(input_num_units, hidden_num_units), torche.nn.ReLU(), torche.nn.Linéaire(hidden_num_units, output_num_units), ) loss_fn = torch.nn.CrossEntropyLoss()
Maintenant que vous connaissez les composants de base de PyTorch, vous pouvez facilement créer votre propre réseau de neurones à partir de zéro. Suivez-le si vous voulez savoir comment!
Construire un réseau de neurones dans Numpy vs PyTorch
J'ai mentionné ci-dessus que PyTorch et Numpy sont très similaires. Voyons pourquoi. Dans cette section, nous verrons une implémentation d'un réseau de neurones simple pour résoudre un problème de classification binaire (vous pouvez lire cet article pour une explication détaillée).
## Réseau de neurones dans numpy
importer numpy en tant que np
#Tableau d'entrée
X=np.tableau([[1,0,1,0],[1,0,1,1],[0,1,0,1]])
#Sortir
y=np.tableau([[1],[1],[0]])
#Fonction sigmoïde
def sigmoïde (X):
revenir 1/(1 + np.exp(-X))
#Dérivée de la fonction sigmoïde
def dérivés_sigmoïde(X):
retourner x * (1 - X)
#Initialisation des variables
epoch=5000 #Définition des itérations d'entraînement
lr=0.1 #Réglage du taux d'apprentissage
inputlayer_neurons = X.shape[1] #nombre d'entités dans l'ensemble de données
hiddenlayer_neurons = 3 #nombre de neurones à couches cachées
output_neurons = 1 #nombre de neurones à la couche de sortie
#initialisation du poids et du biais
wh=np.random.uniform(taille =(inputlayer_neurons,couche_cachée_neurones))
bh=np.aléatoire.uniforme(taille =(1,couche_cachée_neurones))
wout=np.random.uniform(taille =(couche_cachée_neurones,output_neurons))
bout=np.random.uniform(taille =(1,output_neurons))
pour moi à portée(époque):
#Propagation vers l'avant
hidden_layer_input1=np.dot(X,quoi)
hidden_layer_input=hidden_layer_input1 + bh
hiddenlayer_activations = sigmoïde(hidden_layer_input)
output_layer_input1=np.dot(activations_couche cachée,route)
output_layer_input= output_layer_input1+ combat
sortie = sigmoïde(output_layer_input)
#Rétropropagation
E = sortie y
slope_output_layer = dérivés_sigmoïde(sortir)
slope_hidden_layer = dérivés_sigmoïde(activations_couche cachée)
d_sortie = E * slope_output_layer
Error_at_hidden_layer = d_output.dot(wout.T)
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
wout += hiddenlayer_activations.T.dot(d_sortie) *g / D
bout += np.sum(d_sortie, axe=0,keepdims=True) *g / D
wh += X.T.dot(d_couche cachée) *g / D
bh + = np.sum(d_couche cachée, axe=0,keepdims=True) *g / D
imprimer('réel :n', Oui, 'n')
imprimer('prédit :n', sortir)
À présent, essayez de repérer la différence dans une implémentation super simple de la même chose dans PyTorch (les différences sont mentionnées en gras dans le code suivant).
## réseau de neurones dans pytorch
torche d'importation
#Tableau d'entrée
X = torche.Tensor([[1,0,1,0],[1,0,1,1],[0,1,0,1]])
#Sortir
y = torche.Tensor([[1],[1],[0]])
#Fonction sigmoïde
def sigmoïde (X):
revenir 1/(1 + torche.exp(-X))
#Dérivée de la fonction sigmoïde
def dérivés_sigmoïde(X):
retourner x * (1 - X)
#Initialisation des variables
epoch=5000 #Définition des itérations d'entraînement
lr=0.1 #Réglage du taux d'apprentissage
inputlayer_neurons = X.shape[1] #nombre d'entités dans l'ensemble de données
hiddenlayer_neurons = 3 #nombre de neurones à couches cachées
output_neurons = 1 #nombre de neurones à la couche de sortie
#initialisation du poids et du biais
quoi=torche.randn(inputlayer_neurons, couche_cachée_neurones).taper(torche.FloatTensor)
bh=torche.randn(1, couche_cachée_neurones).taper(torche.FloatTensor)
route =torche.randn(couche_cachée_neurones, output_neurons)
bout=torche.randn(1, output_neurons)
pour moi à portée(époque):
#Propagation vers l'avant
hidden_layer_input1 = torche.mm(X, quoi)
hidden_layer_input = hidden_layer_input1 + bh
hidden_layer_activations = sigmoïde(hidden_layer_input)
output_layer_input1 = torche.mm(activations_couches_cachées, route)
output_layer_input = output_layer_input1 + combat
sortie = sigmoïde(output_layer_input1)
#Rétropropagation
E = sortie y
slope_output_layer = dérivés_sigmoïde(sortir)
slope_hidden_layer = dérivés_sigmoïde(activations_couches_cachées)
d_sortie = E * slope_output_layer
Error_at_hidden_layer = torche.mm(d_sortie, wout.t())
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
pas += torche.mm(activations_couche_cachée.t(), d_sortie) *g / D
bout += d_output.sum() *g / D
wh += torche.mm(X.t(), d_couche cachée) *g / D
bh += d_sortie.somme() *g / D
imprimer('réel :n', Oui, 'n')
imprimer('prédit :n', sortir)
Comparaison avec d'autres bibliothèques de deep learning
Dans une script d'analyse comparative, Il a été démontré avec succès que PyTorch surpasse toutes les autres grandes bibliothèques d'apprentissage en profondeur dans la formation d'un réseau de mémoire à long et à court terme (LSTM) ayant le temps médian le plus bas par époque (se référer à l'image ci-dessous).

Les API pour le chargement des données sont bien conçues dans PyTorch. Les interfaces sont spécifiées dans un ensemble de données, un échantillonneur et un chargeur de données.
Lors de la comparaison d'outils de chargement de données dans TensorFlow (lecteurs, colas, etc.), j'ai trouvé PyTorcheLes modules de chargement de données sont assez faciles à utiliser. En outre, PyTorch est parfait pour essayer de créer un réseau de neurones, nous n'avons donc pas à nous fier à des bibliothèques tierces de haut niveau comme keras.
D'un autre côté, Je ne recommanderais toujours pas d'utiliser PyTorch pour la mise en œuvre. PyTorch n'a pas encore évolué. Comme l'ont dit les développeurs de PyTorch, « Ce que nous constatons, c'est que les utilisateurs créent d'abord un modèle PyTorch. Quand ils sont prêts à déployer leur modèle en production, il suffit d'en faire un modèle Caffe 2 et ensuite ils l'envoient sur une plateforme mobile ou une autre ".
Étude de cas: Résoudre un problème de reconnaissance d'image dans PyTorch
Se familiariser avec PyTorch, nous allons résoudre le problème de la pratique de l'apprentissage en profondeur de DataPeaker: Identifier les chiffres. Jetons un coup d'œil à notre énoncé de problème:
Notre problème est un problème de reconnaissance d'image, pour identifier les chiffres d'une image donnée de 28 X 28. Nous avons un sous-ensemble d'images pour l'entraînement et le reste pour tester notre modèle.
Premier, télécharger le train et les fichiers de test. L'ensemble de données contient un fichier compressé de toutes les images et train.csv et test.csv sont nommés d'après les images de train et de test correspondantes. Les fonctionnalités supplémentaires ne sont pas fournies dans les ensembles de données, seules les images brutes sont fournies au format '.png'.
Nous allons commencer:
PASO 0: Se préparer
une) Importez toutes les bibliothèques nécessaires
# importer des modules %pylab en ligne importer le système d'exploitation importer numpy en tant que np importer des pandas au format pd de scipy.misc importer imread de sklearn.metrics importer precision_score
b) Définissons une valeur de départ, afin que nous puissions contrôler le caractère aléatoire de nos modèles
# Pour arrêter le hasard potentiel graine = 128 rng = np.random.RandomState(la graine)
c) La première étape consiste à définir les chemins de répertoire, Pour votre garde!
root_dir = os.path.abspath('.')
data_dir = os.path.join(répertoire_racine, 'Les données')
# vérifier l'existence
os.path.existe(répertoire_racine), os.path.existe(rép_données)
PASO 1: Chargement et prétraitement des données
une) Lisons maintenant nos ensembles de données. Ceux-ci sont au format .csv et ont un nom de fichier avec les balises correspondantes.
# charger l'ensemble de données train = pd.read_csv(os.path.join(rép_données, 'Former', 'train.csv')) test = pd.read_csv(os.path.join(rép_données, 'Test.csv')) sample_submission = pd.read_csv(os.path.join(rép_données, 'Sample_Submission.csv')) train.head()
| nom de fichier | étiqueter | |
|---|---|---|
| 0 | 0.png | 4 |
| 1 | 1.png | 9 |
| 2 | 2.png | 1 |
| 3 | 3.png | 7 |
| 4 | 4.png | 3 |
b) Voyons à quoi ressemblent nos données !! Nous lisons notre image et la montrons.
# imprimer une image
nom_img = rng.choix(train.nom_fichier)
chemin de fichier = os.path.join(rép_données, 'Former', 'Images', 'former', nom_img)
img = imread(chemin du fichier, aplatir=Vrai)
pylab.imshow(img, cmap='gris')
pylab.axis('désactivé')
pylab.show()

ré) Pour une manipulation plus facile des données, nous stockons toutes nos images sous forme de tableaux numpy
# charger des images pour créer un train et un ensemble de test
température = []
pour img_name dans train.filename:
image_path = os.path.join(rép_données, 'Former', 'Images', 'former', nom_img)
img = imread(chemin_image, aplatir=Vrai)
img = img.astype('float32')
temp.append(img)
train_x = np.pile(température)
train_x /= 255.0
train_x = train_x.remodeler(-1, 784).astype('float32')
température = []
pour img_name dans test.filename:
image_path = os.path.join(rép_données, 'Former', 'Images', 'test', nom_img)
img = imread(chemin_image, aplatir=Vrai)
img = img.astype('float32')
temp.append(img)
test_x = np.pile(température)
test_x /= 255.0
test_x = test_x.reshape(-1, 784).astype('float32')
train_y = train.label.values
e) Comment c'est un problème typique des AA, pour tester le bon fonctionnement de notre modèle nous créons un ensemble de validation. Prenons une taille de division de 70:30 pour la rame vs. l'ensemble de validation
# créer un jeu de validation split_size = entier(train_x.shape[0]*0.7) train_x, val_x = train_x[:split_size], train_x[split_size:] train_y, val_y = train_y[:split_size], train_y[split_size:]
PASO 2: Construction de maquettes
une) Vient maintenant la partie principale! Définissons notre architecture de réseau de neurones. On définit un réseau de neurones avec 3 couches d'entrée, caché et sortie. Le nombre de neurones en entrée et en sortie est fixe, puisque l'entrée est notre image de 28 X 28 et la sortie est un vecteur de 10 X 1 que représente la classe. Nous prenons 50 neurones dans la couche cachée. Ici on utilise Adam comme nos algorithmes d'optimisation, qui est une variante efficace de l'algorithme de descente de gradient.
torche d'importation de torch.autograd importation Variable
# nombre de neurones dans chaque couche input_num_units = 28*28 hidden_num_units = 500 output_num_units = 10 # définir les variables restantes époques = 5 taille_bat = 128 taux_apprentissage = 0.001
b) Il est temps de former notre modèle
# définir le modèle modèle = torche.nn.Séquentiel( torche.nn.Linéaire(input_num_units, hidden_num_units), torche.nn.ReLU(), torche.nn.Linéaire(hidden_num_units, output_num_units), ) loss_fn = torch.nn.CrossEntropyLoss() # définir l'algorithme d'optimisation optimiseur = torche.optim.Adam(model.paramètres(), lr=taux_apprentissage)
## fonctions d'assistance
# prétraiter un lot de données
def preproc(unclean_batch_x):
"""Convertir les valeurs en plage 0-1"""
temp_batch = unclean_batch_x / unclean_batch_x.max()
retourner temp_batch
# créer un lot
def batch_creator(taille du lot):
dataset_name="former"
dataset_length = train_x.shape[0]
batch_mask = rng.choice(dataset_length, taille du lot)
batch_x = eval(nom_ensemble_données + '_X')[batch_mask]
batch_x = préproc(lot_x)
if dataset_name == 'train':
batch_y = eval(nom_ensemble_données).ix[batch_mask, 'étiqueter'].valeurs
renvoyer batch_x, batch_y
# réseau ferroviaire
total_batch = entier(forme.du.train[0]/taille du lot)
pour l'époque dans la gamme(époques):
coût_moy = 0
pour moi à portée(total_lot):
# créer un lot
lot_x, batch_y = batch_creator(taille du lot)
# passer ce lot pour la formation
X, y = Variable(torche.from_numpy(lot_x)), Variable(torche.from_numpy(batch_y), require_grad=Faux)
avant = modèle(X)
# obtenir une perte
perte = perte_fn(pred, Oui)
# effectuer une rétropropagation
perte.en arrière()
optimiseur.étape()
coût_moy += perte.données[0]/total_lot
imprimer(époque, coût_moy)
# obtenir la précision de l'entraînement X, y = Variable(torche.from_numpy(préproc(train_x))), Variable(torche.from_numpy(train_y), require_grad=Faux) avant = modèle(X) final_pred = np.argmax(pred.data.numpy(), axe=1) score_précision(train_y, final_pred)
# obtenir la précision de la validation X, y = Variable(torche.from_numpy(préproc(val_x))), Variable(torche.from_numpy(val_y), require_grad=Faux) avant = modèle(X) final_pred = np.argmax(pred.data.numpy(), axe=1) score_précision(val_y, final_pred)
Le score d'entraînement s'avère être:
0.8779008746355685
tandis que le score de validation est:
0.867482993197279
C'est un score assez impressionnant !, surtout quand nous avons formé un réseau de neurones très simple pour seulement cinq époques!
Remarques finales
J'espère que cet article vous a donné une idée de la façon dont le framework PyTorch peut changer la perspective de la construction de modèles d'apprentissage en profondeur. Dans cet article, nous venons de gratter la surface. Approfondir, tu peux lire la documentation Oui tutoriels sur la page officielle de PyTorch.
Dans les prochains articles, Je vais postuler PyTorche pour l'analyse audio et nous essaierons de créer des modèles d'apprentissage en profondeur pour le traitement de la parole. Restez à l'écoute!
Avez-vous utilisé PyTorch pour créer une application ou dans l'un de vos projets de science des données? Faites-le moi savoir dans les commentaires ci-dessous..





