Cet article a été publié dans le cadre du Blogathon sur la science des données.
introduction
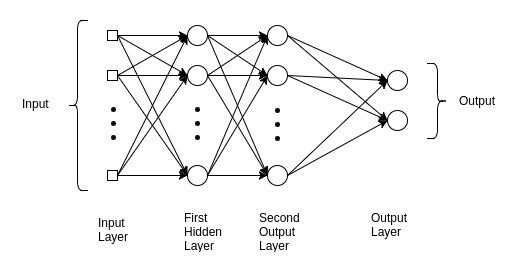
Comprender esta red nos ayuda a obtener información sobre las razones subyacentes en los modelos avanzados de Deep Learning. El perceptrón multicapa se usa comúnmente en problemas de regresión simple. Cependant, los MLP no son ideales para procesar patrones con datos secuenciales y multidimensionales.
🙄 Un perceptrón multicapa se esfuerza por recordar patrones en datos secuenciales, à cause de, requiere una “gran” cantidad de paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... para procesar datos multidimensionales.
MLP, CNN y RNN no hacen todo …
Gran parte de su éxito proviene de identificar su objetivo y la buena elección de algunos parámetros, Quoi Fonction de perte, Optimiseur, Oui Regularizador.
También disponemos de datos ajenos al entorno de formación. El papel del regularizador es garantizar que el modelo entrenado se generalice a nuevos datos.
Ensemble de données MNIST
Supongamos que nuestro objetivo es crear una red para identificar números basados en dígitos escritos a mano. Par exemple, cuando la entrada a la red es una imagen de un número 8, la previsión correspondiente también debe ser 8.
🤷🏻♂️ Este es un trabajo básico de clasificación con redes neuronales.
Antes de analizar el modelo MLP, es esencial comprender el conjunto de datos del MNIST. Se utiliza para explicar y validar muchas teorías de l'apprentissage en profondeurL'apprentissage en profondeur, Une sous-discipline de l’intelligence artificielle, s’appuie sur des réseaux de neurones artificiels pour analyser et traiter de grands volumes de données. Cette technique permet aux machines d’apprendre des motifs et d’effectuer des tâches complexes, comme la reconnaissance vocale et la vision par ordinateur. Sa capacité à s’améliorer continuellement au fur et à mesure que de nouvelles données lui sont fournies en fait un outil clé dans diverses industries, de la santé... porque las 70.000 imágenes que contiene son pequeñas pero suficientemente ricas en información;

MNIST es una colección de dígitos que van del 0 Al 9. Tiene un conjunto de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... de 60.000 imágenes y 10.000 pruebas clasificadas en categorías.
Usar el conjunto de datos MNIST en TensorFlow es simple.
importer numpy comme par exemple de tensorflow.keras.datasets importer mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()
Les mnist.load_data () El método es conveniente, ya que no es necesario cargar las 70.000 imágenes y sus etiquetas.
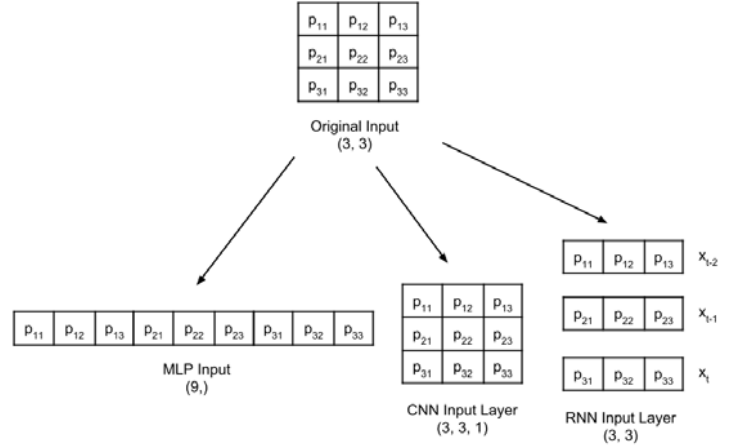
Antes de entrar en el clasificador de Perceptrón Multicapa, es fundamental tener en cuenta que, si bien los datos del MNIST constan de tensores bidimensionales, se deben remodelar, según el tipo de couche d'entréeLa "couche d'entrée" fait référence au niveau initial d’un processus d’analyse de données ou d’architectures de réseaux de neurones. Sa fonction principale est de recevoir et de traiter l’information brute avant qu’elle ne soit transformée par les couches suivantes. Dans le contexte de l’apprentissage automatique, Une bonne configuration de la couche d’entrée est cruciale pour garantir l’efficacité du modèle et optimiser ses performances dans des tâches spécifiques.....
Se cambia la forma de una imagen en escala de grises de 3 × 3 para las capas de entrada MLP, CNN y RNN:
Las etiquetas tienen forma de dígitos, du 0 Al 9.
num_labels = len(np.unique(y_train)) imprimer("total de labels:t{}".format(nombre_étiquettes)) imprimer("Étiquettes:ttt{0}".format(np.unique(y_train)))
⚠️ Esta representación no es adecuada para la capa de pronóstico que genera probabilidad por clase. El formato más adecuado es one-hot, un vector de 10 dimensiones como todos los valores 0, excepto el indiceLe "Indice" C’est un outil fondamental dans les livres et les documents, qui vous permet de localiser rapidement les informations souhaitées. Généralement, Il est présenté au début d’une œuvre et organise les contenus de manière hiérarchique, y compris les chapitres et les sections. Sa préparation correcte facilite la navigation et améliore la compréhension du matériau, ce qui en fait une ressource incontournable tant pour les étudiants que pour les professionnels dans divers domaines.... de clase. Par exemple, si la etiqueta es 4, el vector equivalente es [0,0,0,0, 1, 0,0,0,0,0].
Apprentissage en profondeur, los datos se almacenan en un tensorLos tensores son estructuras matemáticas que generalizan conceptos como scalars y vectores. Se utilizan en diversas disciplinas, incluyendo física, ingeniería y aprendizaje automático, para representar datos multidimensionales. Un tensor puede ser visualizado como una matriz de múltiples dimensiones, lo que permite modelar relaciones complejas entre diferentes variables. Su versatilidad y capacidad para manejar grandes volúmenes de información los convierten en herramientas fundamentales en el análisis y procesamiento de datos..... El término tensor se aplica a un tensor escalar (tensor 0D), vector (tensor 1D), quartier général (tensor bidimensional) Oui tensor multidimensionalLos tensores multidimensionales son estructuras matemáticas que generalizan la noción de escalares, vectores y matrices a dimensiones superiores. Se utilizan ampliamente en campos como la física, la ingeniería y el aprendizaje automático, permitiendo representar y manipular datos complejos de manera eficiente. Su capacidad para almacenar información en múltiples dimensiones facilita el análisis y la modelización de fenómenos reales, contribuyendo a avances en diversas disciplinas científicas y tecnológicas.....
#converter em one-hot
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
Nuestro modelo es un MLP, por lo que sus entradas deben ser un tensor 1D. En tant que tel, x_train y x_test deben transformarse en [60,000, 2828] Oui [10,000, 2828],
En sume, el tamaño de -1 significa permitir que la biblioteca calcule la dimensión correcta. En el caso de x_train, il est 60.000.
image_size = x_train.shape[1] input_size = image_size * image_size print("x_train:t{}".format(x_train.shape)) imprimer("x_test:tt{}m".format(x_test.shape)) x_train = np.reshape(x_train, [-1, taille_entrée]) x_train = x_train.astype('float32') / 255 x_test = np.reshape(x_test, [-1, taille_entrée]) x_test = x_test.astype('float32') / 255 imprimer("x_train:t{}".format(x_train.shape)) imprimer("x_test:tt{}".format(x_test.shape))
OUTPUT:
x_train: (60000, 28, 28) x_test: (10000, 28, 28) x_train: (60000, 784) x_test: (10000, 784)
Construire le modèle
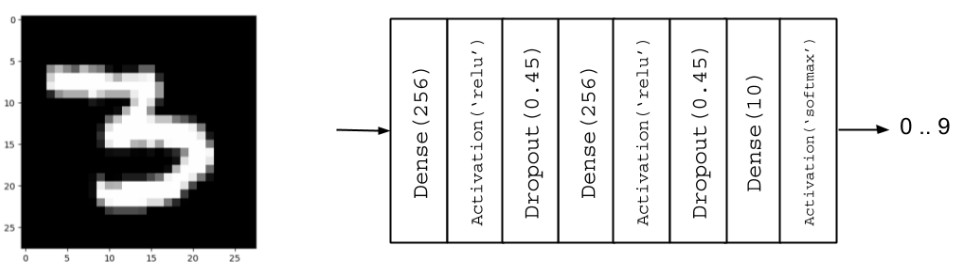
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Activation, Abandonner # Parameters batch_size = 128 # It is the sample size of inputs to be processed at each training stage. hidden_units = 256 abandon = 0.45 # Nossa MLP com ReLU e Dropout model = Sequential() model.ajouter(Dense(hidden_units, input_dim=input_size)) model.ajouter(Activation('relu')) model.ajouter(Abandonner(abandonner)) model.ajouter(Dense(hidden_units)) model.ajouter(Activation('relu')) model.ajouter(Abandonner(abandonner)) model.ajouter(Dense(nombre_étiquettes))
Régularisation
Una red neuronal tiende a memorizar sus datos de entrenamiento, especialmente si contiene capacidad más que suficiente. Dans ce cas, la red falla catastróficamente cuando se somete a los datos de prueba.
Este es el caso clásico en el que la red no logra generalizar (OverfittingEl sobreajuste, o overfitting, es un fenómeno en el aprendizaje automático donde un modelo se ajusta demasiado a los datos de entrenamiento, capturando ruido y patrones irrelevantes. Esto resulta en un rendimiento deficiente en datos no vistos, ya que el modelo pierde capacidad de generalización. Para mitigar el sobreajuste, se pueden emplear técnicas como la regularización, la validación cruzada y la reducción de la complejidad del modelo.... / UnderfittingEl underfitting es un problema común en el aprendizaje automático que ocurre cuando un modelo es demasiado simple para capturar la complejidad de los datos. Esto se traduce en un rendimiento deficiente tanto en el conjunto de entrenamiento como en el de prueba. Las causas del underfitting pueden incluir un modelo inadecuado, características irrelevantes o insuficientes datos. Afin de le résoudre, se puede optar por modelos más complejos o mejorar la calidad...). Para evitar esta tendencia, el modelo utiliza una capa reguladora. Laisser.
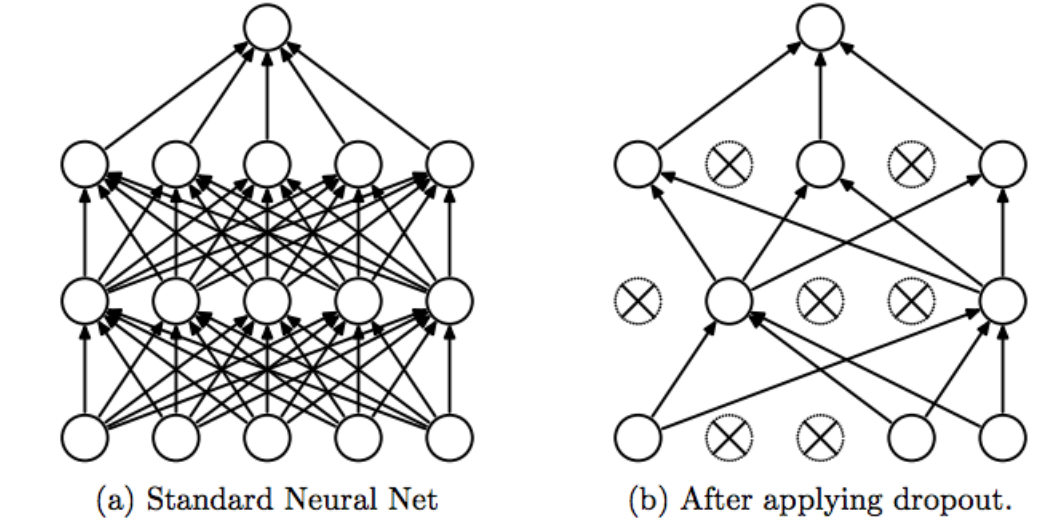
La idea de Dropout es simple. Dada una tasa de descarte (en nuestro modelo, establecemos = 0,45), la capa elimina aleatoriamente esta fracción de unidades.
Par exemple, si la primera capa tiene 256 unités, después de que se aplica el abandono (0.45), solo (1 – 0.45) * 255 = 140 unidades participarán en la siguiente capa
La deserción hace que las redes neuronales sean más robustas para los datos de entrada imprevistos, porque la red está entrenada para predecir correctamente, incluso si algunas unidades están ausentes.
⚠️ El abandono solo participa en « jouer » 🤷🏻♂️ durante el entrenamiento.
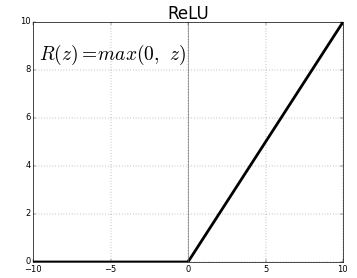
Activation
La Couche de sortieLa "Couche de sortie" est un concept utilisé dans le domaine des technologies de l’information et de la conception de systèmes. Il s’agit de la dernière couche d’un modèle logiciel ou d’une architecture qui est chargée de présenter les résultats à l’utilisateur final. Cette couche est cruciale pour l’expérience utilisateur, puisqu’il permet une interaction directe avec le système et la visualisation des données traitées.... possède 10 unités, seguidas de una función de activación softmax. Le 10 unidades corresponden a las 10 posibles etiquetas, clases o categorías.
La activación de softmax se puede expresar matemáticamente, de acuerdo con la siguiente ecuación:
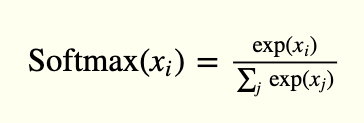
model.ajouter(Activation('softmax'))
modèle.résumé()
OUTPUT:
Modèle: "séquentiel" _________________________________________________________________ Couche (taper) Paramètre de forme de sortie # ================================================================= dense (Dense) (Rien, 256) 200960 _________________________________________________________________ activation (Activation) (Rien, 256) 0 _________________________________________________________________ dropout (Abandonner) (Rien, 256) 0 _________________________________________________________________ dense_1 (Dense) (Rien, 256) 65792 _________________________________________________________________ activation_1 (Activation) (Rien, 256) 0 _________________________________________________________________ abandon_1 (Abandonner) (Rien, 256) 0 _________________________________________________________________ dense_2 (Dense) (Rien, 10) 2570 _________________________________________________________________ activation_2 (Activation) (Rien, 10) 0 ================================================== ================ Paramètres totaux: 269,322 Paramètres entraînables: 269,322 Paramètres non entraînables: 0 _________________________________________________________________
Visualización de modelos
Amélioration
El propósito de la Optimización es minimizar la función de pérdida. La idea es que si la pérdida se reduce a un nivel aceptable, el modelo aprendió indirectamente la función que asigna las entradas a las salidas. Las métricas de rendimiento se utilizan para determinar si su modelo ha aprendido.
modèle.compile(perte ="catégorique_crossentropie", optimiseur="Adam", métriques=['précision'])
-
- Categorical_crossentropy, se utiliza para one-hot
- La precisión es una buena métrica para las tareas de clasificación.
- Adam es un Algorithme d’optimisationUn algorithme d’optimisation est un ensemble de règles et de procédures conçues pour trouver la meilleure solution à un problème spécifique, Optimisation ou réduction d’une fonction cible. Ces algorithmes sont fondamentaux dans divers domaines, comme l’ingénierie, L’économie et l’intelligence artificielle, où elle cherche à améliorer l’efficacité et à réduire les coûts. Les approches sont multiples, y compris les algorithmes génétiques, Programmation linéaire et méthodes d’optimisation combinatoire.... que se puede utilizar en lugar del procedimiento clásico de descenso de penteLe gradient est un terme utilisé dans divers domaines, comme les mathématiques et l’informatique, pour décrire une variation continue de valeurs. En mathématiques, fait référence au taux de variation d’une fonction, pendant la conception graphique, S’applique à la transition de couleur. Ce concept est essentiel pour comprendre des phénomènes tels que l’optimisation dans les algorithmes et la représentation visuelle des données, permettant une meilleure interprétation et analyse dans... stochastique
📌 Dado nuestro conjunto de entrenamiento, la elección de la Fonction de perteLa fonction de perte est un outil fondamental de l’apprentissage automatique qui quantifie l’écart entre les prédictions du modèle et les valeurs réelles. Son but est de guider le processus de formation en minimisant cette différence, permettant ainsi au modèle d’apprendre plus efficacement. Il existe différents types de fonctions de perte, tels que l’erreur quadratique moyenne et l’entropie croisée, chacun adapté à différentes tâches et..., el optimizador y el regularizador, podemos comenzar a entrenar nuestro modelo.
model.fit(x_train, y_train, époques=20, batch_size=bat_size)
OUTPUT:
Époque 1/20
469/469 [===============================] - 1s 3ms/step - perte: 0.4230 - précision: 0.8690
....
Époque 20/20 469/469 [===============================] - 2s 4ms/pas - perte: 0.0515 - précision: 0.9835
Évaluation
En ce point, nuestro modelo de clasificador de dígitos MNIST está completo. Su evaluación de desempeño será el siguiente paso para determinar si el modelo entrenado presentará una solución subóptima
_, acc = model.evaluate(x_test, y_test, batch_size=bat_size, verbeux=0) imprimer("nAccuracy: %.1f%%n" % (100.0 * acc))
OUTPUT:
Précision: 98.4%
continuará…





