Ce message a été rendu public dans le cadre de la Blogathon sur la science des données
introduction
échantillonnage pour obtenir la probabilité d'une plage d'une quantité inconnue. Cela semble difficile! ne t'inquiète pas, nous allons explorer cela en profondeur dans ce post
Une histoire brève:
La méthode de Monte Carlo a été inventée par John Neumann et Ulam Stanislaw pour orienter la prise de décision dans des conditions incertaines. Il porte le nom d'une célèbre ville de casino de Monte Carlo appelée Monaco, puisque la part du hasard est au cœur de la démarche de modélisation, car il est similaire à un jeu de roulette.
En mots simples, La simulation de Monte Carlo est une méthode de estimer la valeur d'un quantité inconnue à l'aide de statistiques inférentielles. Vous n'avez pas besoin de vous plonger dans les statistiques inférentielles pour bien comprendre le fonctionnement de la simulation Monte Carlo. Malgré cela, cet article ne passera en revue que les points de statistiques inférentielles qui nous seront pertinents dans la simulation de Monte Carlo.
Les statistiques inférentielles sont responsables de la Ville quelle est notre série d'exemples et goûter, qui est un sous-ensemble approprié de la population. Le point clé auquel il faut prêter attention est qu'un échantillon aléatoire a tendance à présenter la même fonctionnalités / propriété que la population dont elle est extraite.
Nous verrons un exemple pour comprendre le fonctionnement de la simulation Monte Carlo.
Notre objectif est d'estimer la probabilité que nous ayons de l'avance si nous lançons une pièce un nombre infini de fois..
1. Disons que nous le retournons une fois et allons de l'avant. Sommes-nous sûrs de dire que notre réponse est 1?
2. Maintenant, nous avons à nouveau lancé la pièce et le visage est réapparu. Sommes-nous sûrs que la prochaine version sera également en avance?
3. Nous le retournons encore et encore, Disons 100 fois, et étrangement la tête apparaît à chaque fois. À présent, Doit-on accepter le fait que le prochain tour se traduira par une autre tête?
4. Changeons la scène et supposons que 100 libère, 52 a entraîné le repos de la tête, 48 ils sont devenus des croix. La probabilité que le prochain lancer frappe la tête est 52/100? Compte tenu du constat, est notre meilleure estimation, mais la confiance restera faible.
Pourquoi y a-t-il une différence dans le niveau de confiance?
Il est essentiel de savoir que notre estimation dépend de deux choses
1. Taille: La taille de l'échantillon (par exemple, 100 vs 2 Dans les cas 2 Oui 4 respectivement)
2. Différence: écart d'échantillon (tous les résultats comme tête vs. 52 têtes comme dans le cas 3 Oui 4 respectivement)
3. UNE mesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... que aumenta la varianza de la observación (cas 3 Oui 4), le besoin se fait sentir d'une observation plus approfondie (comme dans les cas 2 Oui 4) avoir le même degré de confiance.
Nous allons maintenant simuler un jeu de roulette (python):
Roulette est un jeu dans lequel un disque avec des blocs (moitié rouge et moitié noir) dans lequel une balle peut être contenue, tourner avec une balle. Nous devons deviner un nombre et si la balle atterrit sur ce nombre, alors c'est une victoire, et nous avons gagné un montant de (montant payé pour un créneau
) X (non. Du nombre total d’emplacements dans la machine).
classe Roulette():
def __init__(soi):
self.pockets = []
pour moi à portée(1,37):
self.pockets.append(je)
self.ball = None
self.pocketOdds = len(self.pockets) - 1
def spin(soi):
self.ball = random.choice(self.pockets)
def betPocket(soi, Poche, amt):
si str(Poche) == chaîne(self.ball):
return amt*self.pocketOdds
else: return -amt
def __str__(soi):
return 'Fair Roulette'
def playRoulette(Jeu, numSpins, Poche, Parier):
totPocket = 0
pour moi à portée(numSpins):
game.spin()
totPocket += game.betPocket(Poche, Parier)
si toPrint:
imprimer (numSpins, 'spins de', Jeu)
imprimer ('Pari de retour attendu', Poche, '=',
str(100*totPocket/numSpins) + '%n')
revenir (totPocket/numSpins)
jeu = Roulette()
pour numSpins dans (100, 1000000):
pour moi à portée(3):
playRoulette(Jeu, numSpins, 5, 1, Vrai)
100 Tours de roulette
Paris de rendement attendus 5 = -100.0%
100 Tours de roulette
Paris de rendement attendus 5 = 42.0%
100 Tours de roulette
Paris de rendement attendus 5 = -26.0%
1000000 Tours de roulette
Paris de rendement attendus 5 = -0,0546%
1000000 Tours de roulette
Paris de rendement attendus 5 = 0,502%
1000000 Tours de roulette
Paris de rendement attendus 5 = 0,7764%
Loi des grands nombres
Dans des tests indépendants répétés avec la probabilité p constante de la population d’un résultat particulier sur chaque test, la probabilité que le résultat se produise, En d'autres termes, obtenus à partir d’échantillons. Diffère de p converge vers zéro comme lui le nombre d'essais va à l'infini.
Cela signifie simplement que si des écarts se produisent (variance) comportement prévisible (probabilité p), ces écarts sont susceptibles d'être compensés à l'avenir par l'écart inverse.
Parlons maintenant d'un incident intéressant qui a eu lieu le 18 août 1913, dans un casino de Monte Carlo. A la roulette, les noirs ont grimpé un record vingt-six fois de suite, et la panique est survenue pour parier sur le rouge (égal à l'écart par rapport au comportement attendu)
Analysons mathématiquement cette situation
1. Probabilité 26 rouges consécutifs = 1 / 67,108,865
2. Probabilité 26 rouges consécutifs quand 25 les parchemins précédents étaient rouges = 1/2
Régression à la moyenne
1. Après un événement aléatoire extrême, le prochain événement aléatoire sera probablement moins extrême, pour que la moyenne soit conservée.
2. Par exemple, si la roulette tourne 10 fois et les rouges viennent à chaque fois, alors c'est un événement extrême = 1/1024 et il est probable que dans le prochain 10 tours nous obtenons moins que 10 rouge, mais le nombre moyen est 5 seulement.
Ensuite, quand on regarde la moyenne de 20 se tourne, sera plus proche de la moyenne attendue de 50% de rouge que de 100% en premier 10 se tourne.
Il est maintenant temps d'affronter une certaine réalité.
Exemple d'espace de résultats possibles
1. Il n'est pas possible de garantir une précision parfaite par échantillonnage et on ne peut pas dire qu'une estimation n'est pas exactement correcte..
Nous sommes ici confrontés à une question: Combien d'échantillons faut-il examiner avant que nous puissions avoir une confiance significative dans notre réponse?
Cela dépend de la variabilité de la distribution sous-jacente.
Niveaux de confiance et intervalles de confiance
Comme dans une situation réelle, nous ne pouvons pas être sûrs d'un paramètre inconnu obtenu à partir d'un échantillon pour l'ensemble de la population, nous utilisons donc des niveaux de confiance et des intervalles de confiance.
L'intervalle de confiance fournit une plage dans laquelle la valeur inconnue est susceptible d'être contenue avec la certitude que la valeur inconnue se situe strictement dans cette plage..
Par exemple, les performances des paris sur une machine à sous 1000 fois à la roulette est -3% avec un margeLa marge est un terme utilisé dans divers contextes, comme la comptabilité, Économie et imprimerie. En comptabilité, fait référence à la différence entre les revenus et les coûts, qui permet d’évaluer la rentabilité d’une entreprise. Dans le domaine de l’édition, La marge est l’espace blanc autour du texte d’une page, qui le rend facile à lire et offre une présentation esthétique. Sa bonne gestion est essentielle.. de error de +/- 4% avec un niveau de confiance de 95%.
Il peut être décodé davantage lorsque nous exécutons un test infini de 1000,
Rendement moyen / la moyenne attendue serait -3%
Les performances varieraient approximativement entre + 1% Oui -7% qu'outre le 95% des fois.
Fonction de densité de probabilité (PDF).
La distribution de forme générale est établie par la fonction de densité de probabilité (PDF). Se establece como la probabilidad de que la variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... aleatoria se encuentre entre un intervalo.
L'aire sous la courbe entre les deux points PDF est la probabilité que la variable aléatoire se situe dans cette plage.
Terminons notre apprentissage par un exemple:
Disons qu'il y a un jeu de cartes mélangées et que nous devons trouver la probabilité d'obtenir 2 rois consécutifs s'ils placent les cartes dans l'ordre où elles sont posées.
Méthode analytique:
P (au moins 2 rois consécutifs) = 1-P (pas de rois consécutifs)
= 1- (49! X 48!) / ((49-4)! X52!) = 0.217376
Par simulation de Monte Carlo:
Pas
1. Sélectionnez des points de données aléatoires à plusieurs reprises: ici on suppose que le brassage des cartes est aléatoire
2. Effectuer des calculs déterministes. Plusieurs d'entre eux mélangent et trouvent les résultats.
3. Combiner les résultats: Explorer le résultat et terminer par notre conclusion.
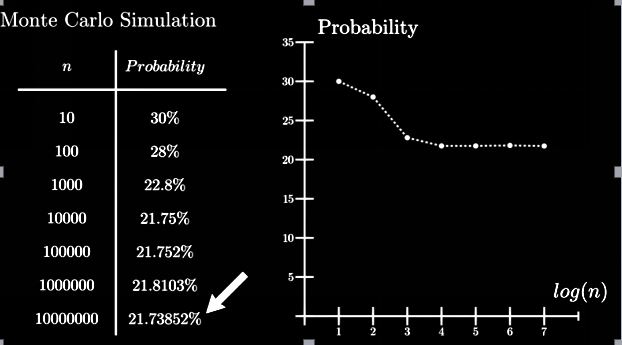
Grâce à la méthode de Monte Carlo, nous obtenons une solution presque exacte à partir de la méthode analytique.
Avantages de la simulation Monte Carlo
- Facile à mettre en œuvre et fournit un échantillonnage statistique pour les expériences numériques à l'aide de l'ordinateur.
- Nous fournit des solutions approximatives satisfaisantes à des problèmes mathématiques coûteux en calcul.
- Peut être utilisé pour les problèmes déterministes et stochastiques.
Inconvénients de la simulation Monte Carlo
- Parfois, cela prend beaucoup de temps, car nous devons générer un grand nombre d'échantillons pour obtenir le résultat satisfaisant souhaité.
- Les résultats obtenus avec cette méthode ne sont que l'approximation de la vraie réponse et non la réponse exacte.
A propos de l'auteur
Soja Dinesh Junjariya, un étudiant en Btech de l'IIT Jodhpur.
Pour toute suggestion, commentaires ci-dessous.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





