introduction
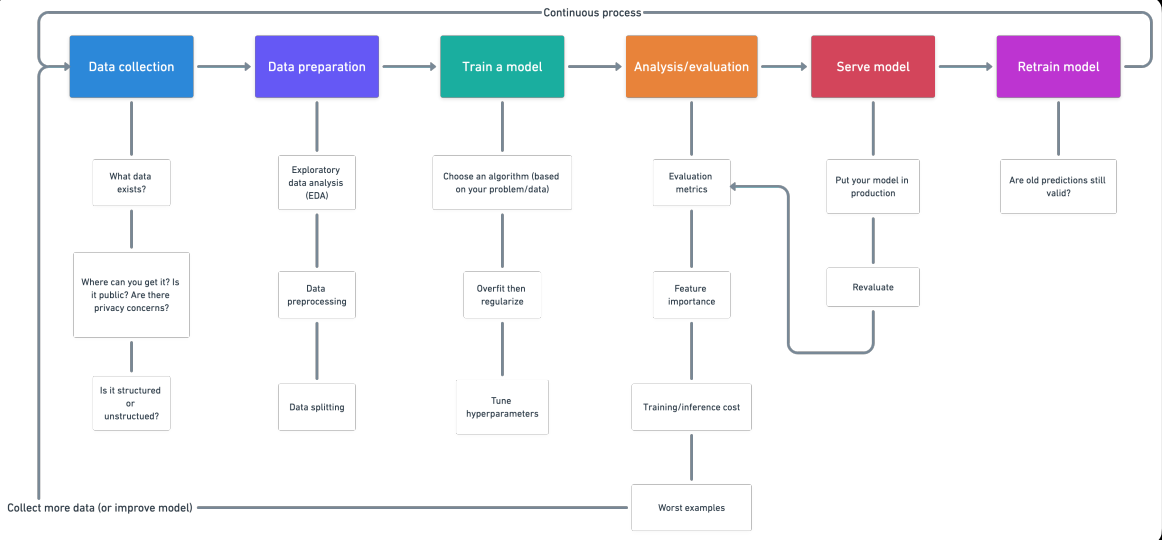
1. Collecte de données
- Quel genre de problème essayons-nous de résoudre?
- Quelles sources de données existent déjà?
- Quels sont les problèmes de confidentialité?
- Les données sont-elles publiques?
- Où devons-nous stocker les fichiers?
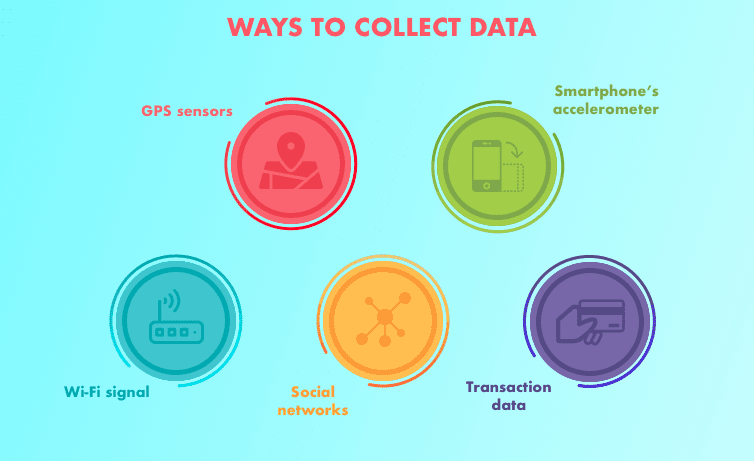
- Données structurées: apparaissent sous forme de tableau (style de ligne et de colonne, comme ce que vous trouveriez dans une feuille de calcul Excel). Contient différents types de données, par exemple, séries temporelles numériques, catégorique.
- · Nominal / catégorique – Une chose ou une autre (mutuellement exclusifs). Par exemple, pour les balances de voiture, la couleur est une catégorie. Une voiture peut être bleue mais pas blanche. Une commande n'a pas d'importance.
- Numérique: Toute valeur continue où la différence entre elles compte. Par exemple, lors de la vente de maisons, $ 107,850 est plus que $ 56,400.
- Ordinal: Des données qui ont de l'ordre mais la distance entre les valeurs est inconnue. Par exemple, une question comme, Comment évalueriez-vous votre santé par rapport à 1 Al 5? 1 être pauvre, 5 sain. Pouvez-vous répondre 1, 2, 3, 4, 5, mais la distance entre chaque valeur ne signifie pas nécessairement qu'une réponse de 5 est cinq fois plus bonne qu'une réponse de 1. Des séries chronologiques: données au fil du temps. Par exemple, les valeurs de vente historiques des bulldozers de 2012 une 2018.
- Des séries chronologiques: Données au fil du temps. Par exemple, les valeurs de vente historiques des bulldozers de 2012 une 2018.
- Données non structurées: Données sans structure rigide (images, vidéo, voix, Naturel
texte de langue)
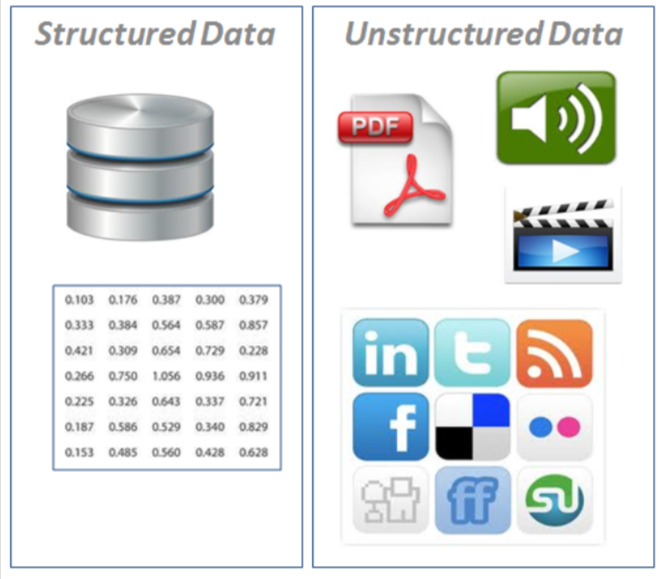
2. Préparation des données
- L'analyse exploratoire des données (AED), en savoir plus sur les données avec lesquelles vous travaillez
- Quelles sont les variables caractéristiques (entrée) et la variable cible (Sortir)? Par exemple, prédire les maladies cardiaques, les variables caractéristiques peuvent être l'âge, le poid, la fréquence cardiaque moyenne et le niveau d'activité physique d'une personne. Et la variable objective sera de savoir s'ils ont ou non une maladie.
- Quel genre de? Séries temporelles structurées, non structuré, numérique. Valeurs manquantes? Si vous les supprimez ou les complétez, la fonction d'imputation.
- Où sont les valeurs aberrantes? Combien y en a-t-il? Pourquoi sont-ils là? Y a-t-il des questions que vous pouvez poser à un expert du domaine sur les données? Par exemple, Un médecin spécialiste des maladies cardiaques pourrait-il faire la lumière sur son ensemble de données sur les maladies cardiaques?
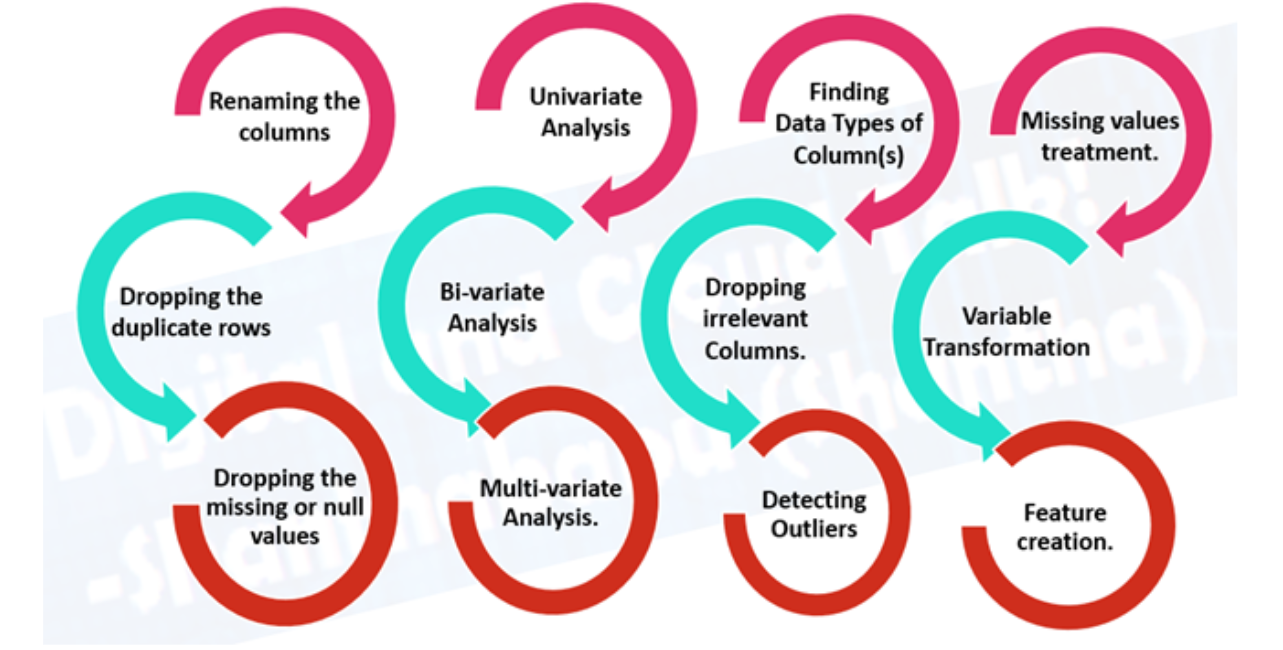
- Prétraitement des données, préparer vos données pour la modélisation.
- Fonction d'imputation: remplir les valeurs manquantes (un modèle d'apprentissage automatique ne peut pas apprendre
dans des données qui ne sont pas là)
- Imputation unique: Remplir de médias, une médiane de la colonne.
- Imputations multiples: Modélisez d'autres valeurs manquantes et avec ce que votre modèle trouve.
- KNN (k voisins les plus proches): Remplissez les données avec une valeur d'un autre exemple similaire.
- Beaucoup plus, comme l'imputation aléatoire, la dernière observation reportée (pour les séries temporelles), la fenêtre mobile et la plus fréquente.
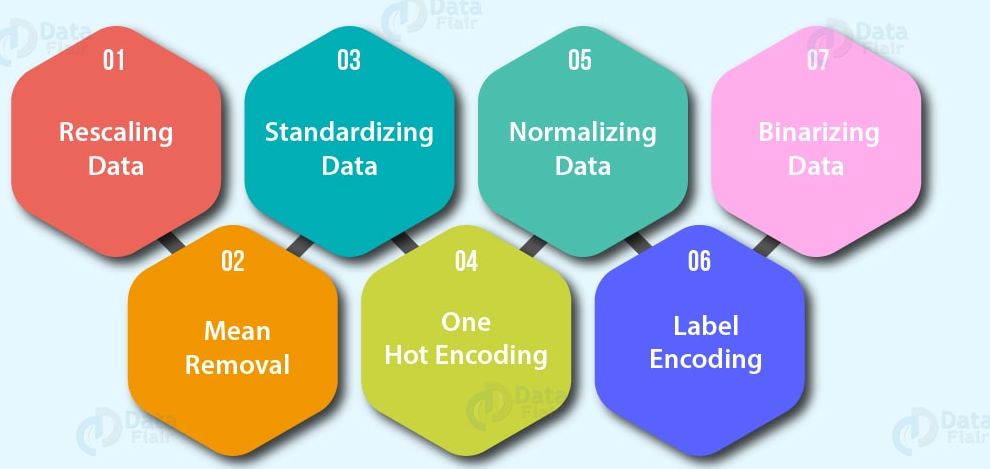
- Codage des fonctions (convertir des valeurs en nombres). Un modèle d'apprentissage automatique
exige que toutes les valeurs soient numériques)
- Un codage à chaud: Convertissez toutes les valeurs uniques en listes de zéros et de uns où la valeur cible est 1 et le reste sont des zéros. Par exemple, quand une voiture devient verte, rouge, bleu, vert, l'avenir de la couleur des voitures serait représenté comme [1, 0, et 0] et un rouge sérieux [0, 1, et 0].
- Encodeur d'étiquette: Convertir des étiquettes en valeurs numériques distinctes. Par exemple, si vos variables cibles sont des animaux différents, comme un chien, chat, oiseau, ceux-ci pourraient devenir 0, 1 Oui 2, respectivement.
- Intégrer le codage: Apprendre une représentation entre tous les différents points de données. Par exemple, un modèle de langage est une représentation de la façon dont différents mots sont liés les uns aux autres. L'intégration est également de plus en plus disponible pour les données structurées (tabulaire).
- Normalisation des fonctions (escaladé) ou standardisation: Lorsque les variables numériques sont à des échelles différentes (par exemple, le nombre_de_salle de bain est compris entre 1 Oui 5 et le size_of_land entre 500 Oui 20000 pieds carrés), certains algorithmes d'apprentissage automatique ne fonctionnent pas très bien. La mise à l'échelle et la normalisation aident à résoudre ce problème.
- Ingénierie fonctionnelle: transformer les données en une représentation (potentiellement) plus significatif en ajoutant des connaissances du domaine
- Décomposer
- Discrétisation: convertir de grands groupes en petits groupes
- Fonctions de croisement et d'interaction: combinaison de deux ou plusieurs fonctions
- Les caractéristiques de l'indicateur: utiliser d'autres parties des données pour indiquer quelque chose de potentiellement important
- Sélection de fonctionnalité: sélection
les fonctionnalités les plus précieuses de votre jeu de données à modéliser. Réduction potentielle du temps d'entraînement et du surapprentissage (moins de données générales et moins de données redondantes à former) et améliorer la précision.
- Réduction de la dimensionnalité: Une méthode courante de réduction de dimensionnalité, L'ACP ou Analyse en Composantes Principales prend beaucoup de dimensions (fonctionnalités) et utiliser l'algèbre linéaire pour les réduire à moins de dimensions. Par exemple, supposons que vous ayez 10 fonctions numériques, Je pourrais exécuter PCA pour le réduire à 3.
- Importance de la fonction (post modélisation): Ajuster un modèle à un ensemble de données, puis inspecter quelles caractéristiques étaient les plus importantes pour les résultats, supprimer le moins important.
- Méthodes d'emballage comment les algorithmes génétiques et la suppression de caractéristiques récursives impliquent la création de grands sous-ensembles d'options de caractéristiques, puis la suppression de celles qui n'ont pas d'importance.
- Gérer les déséquilibres: Vos données ont-elles 10,000 exemples d'une classe mais seulement 100 exemples d'un autre?
- Collecter plus de données (Oui peux)
- Utiliser le package déséquilibré scikit-learn-contrib- apprendre
- Utiliser SMOTE: technique de suréchantillonnage des minorités synthétiques. Créez des échantillons synthétiques de votre classe junior pour essayer d'uniformiser les règles du jeu.
- Un élément utile à regarder est “Apprendre à partir de données déséquilibrées”.
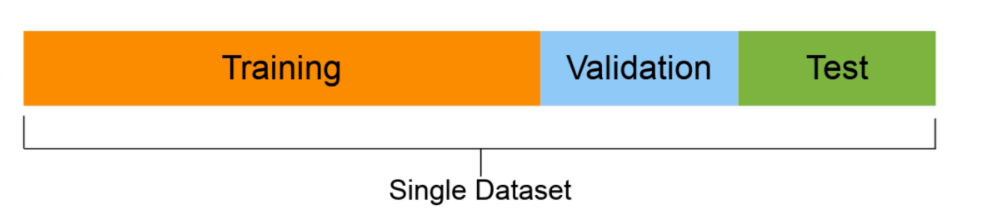
- Ensemble d'entraînement (généralement 70-80% des données): le modèle apprend à ce sujet.
- Ensemble de validation (normalement de 10 Al 15% des données): les hyperparamètres du modèle s'y conforment
- Ensemble d'essai (normalement entre 10% et le 15% des données): les performances finales des modèles sont évaluées sur cette base. Si tu as bien fait, Espérons que les résultats de l'ensemble de tests donnent une bonne indication de la façon dont le modèle devrait fonctionner dans le monde réel. Ne pas utiliser cet ensemble de données pour ajuster le modèle.
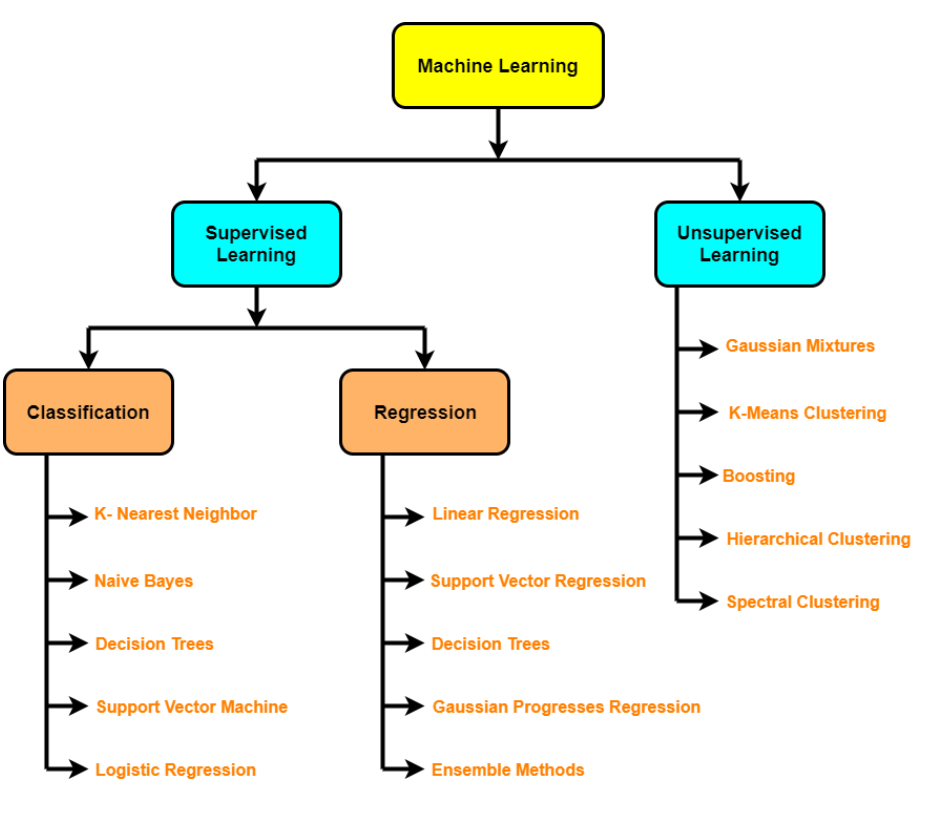
3. Former le modèle sur les données (3 Pas: choisir un algorithme, adapter le modèle, réduire l'ajustement avec régularisation)
- Algorithmes supervisés: régression linéaire, Régression logistique, KNN, SVM, arbre de décision et forêts aléatoires, AdaBoost / Machine de renforcement de gradient (impulsion)
- Algorithmes non supervisés: regroupement, réduction de dimensionnalité (APC, encodeurs automatiques, t-SNE), Détection d'une anomalie
- Apprentissage par lots
- Apprendre en ligne
- Transférer l'apprentissage
- Apprentissage actif
- Assemblée
- Inadaptation – se produit lorsque votre modèle ne fonctionne pas aussi bien que vous le souhaiteriez sur vos données. Essayez de vous entraîner pour un modèle plus long ou plus avancé.
- Sur-ajustement– se produit lorsque la perte de validation commence à augmenter ou lorsque le modèle fonctionne mieux dans l'ensemble d'apprentissage que dans l'ensemble de test.
- Régularisation: un ensemble de technologies pour empêcher / réduire le surapprentissage (par exemple, L1, L2, Abandon, Arrêt anticipé, Augmentation des données, Normalisation par lots)
- Réglage des hyperparamètres – Exécutez un tas d'expériences avec différents paramètres et voyez lequel fonctionne le mieux
4. Une analyse / Évaluation
- Classification: précision, précision, Récupération, F1, matrice de confusion, moyenne moyenne précision (détection d'objets)
- Régression – MSE, BEAUCOUP, R^ 2
- Métrique basée sur les tâches: par exemple, pour la voiture autonome, vous voudrez peut-être connaître le nombre de déconnexions
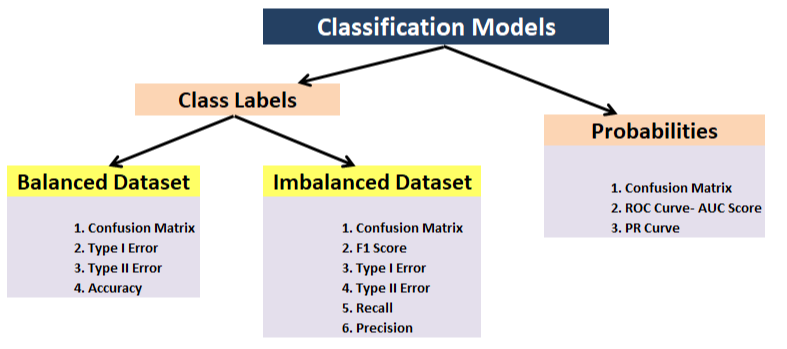
- Importance de la fonctionnalité
- Entraînement / temps d'inférence / Coût
- Et si l'outil: comment mon modèle se compare à d'autres modèles?
- Exemples moins sûrs: Où est le mauvais modèle?
- Compensation de biais / variance
5. Modèle de service (mise en place d'un modèle)
- Mettez le modèle dans production et voir comment ça se passe.
- Instruments que vous pouvez utiliser: Serveur TensorFlow, PyTorch Service, Plateforme d'IA de Google, Sagemaker
- MLOps: où l'ingénierie logicielle rencontre l'apprentissage automatique, essentiellement toute la technologie requise autour d'un modèle d'apprentissage automatique pour le faire fonctionner en production

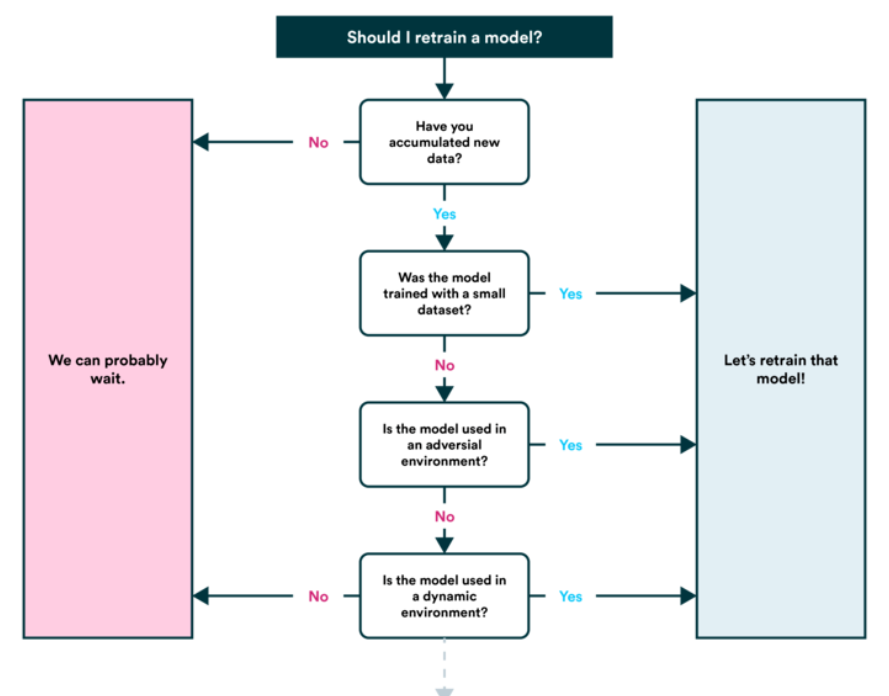
6. Modèle de recyclage
- Voir comment le modèle fonctionne après la publication (ou avant parution) en fonction de divers paramètres d'évaluation et revoir les étapes précédentes au besoin (rappelles toi, l'apprentissage automatique est très expérimental, c'est donc ici que vous voudrez garder une trace de vos données et de vos expériences.
- Vous constaterez également que les prédictions de votre modèle commencent à « vieillir »’ (généralement pas dans un style chic) le « dériver, comme lorsque les sources de données changent ou sont mises à jour (nouveau matériel, etc.). C'est à ce moment-là que vous voudrez l'entraîner à nouveau.
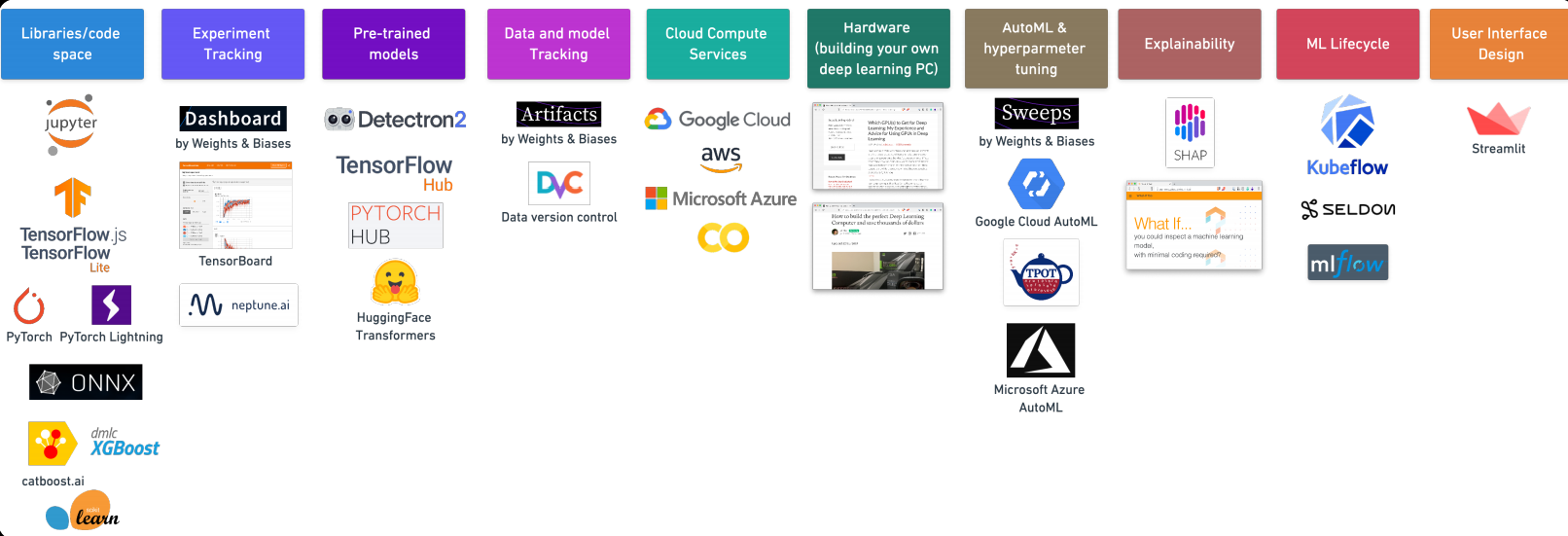
7. Outils d'apprentissage automatique
Merci d'avoir lu ceci. Si vous aimez cet article, Partage-le avec tes amis. En cas de suggestion / doute, commentaires ci-dessous.
Identification de l'e-mail: [email protégé]
Suivez-moi sur LinkedIn: LinkedIn
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





