Fonte: https://www.serokell.io
Nella foto sopra, Puoi vedere che le e-mail sono classificate come spam o meno. Quindi, è un esempio di classificazione (Classificazione binaria).
1. Regressione logistica
2. Bayes ingenuo
3. K-vicini più vicini
5. Albero decisionale
Esamineremo tutti gli algoritmi con un po' di codice applicato al set di dati dell'iride utilizzato per le attività di classificazione. Il set di dati ha 150 Istanze (righe), 4 caratteristiche (colonne) e non contiene valori Null. Ci sono 3 Classi nel set di dati Iris:
– Iris Setosa
– Iris Versicolor
– Iris Virginica
Si tratta di un algoritmo di classificazione molto semplice ma importante nell'apprendimento automatico che utilizza una o più variabili indipendenti per stabilire un risultato. La regressione logistica tenta di trovare la migliore corrispondenza tra la variabile dipendente e un set di variabili indipendenti. La linea che si adatta meglio a questo algoritmo assomiglia alla forma di S, come mostra l'immagine.
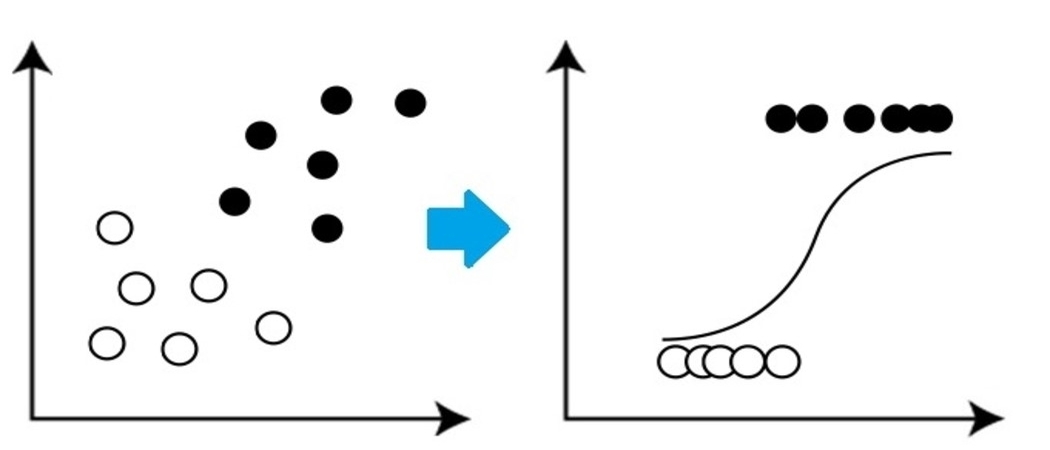
Fonte: https://www.equiskill.com
Professionisti:
- È un algoritmo molto semplice ed efficiente.
- Bassa varianza.
- Fornisce probabilità Punteggio delle osservazioni.
Contro:
- Maltrattamento Un grande Numero di caratteristiche categoriche.
- Si presuppone che i dati siano privi di valori mancanti e che i predittori siano indipendenti l'uno dall'altro.
Esempio:
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
X, y = load_iris()
LR_classifier = RegressioneLogica(stato_casuale=0)
LR_classifier.fit(X, e)
LR_classifier.predict(X[:3, :])
Produzione:
Vettore([0, 0, 0]) Ha predetto 0 Classe per tutti 3 Test forniti per predire la funzione.
2. Bayes ingenuo
Naive Bayes si basa su Teorema di Bayes che fornisce un'ipotesi di indipendenza tra i predittori. Questo classificatore presuppone che la presenza di una particolare funzionalità in una classe non sia correlata alla presenza di un'altra classe
caratteristica / variabile.
I classificatori Naive Bayes sono di tre tipi: Bayes ingenuo multinomiale, Bernoulli Naive Bayes, Bayes naavsiano gaussiano.
Professionisti:
- Questo algoritmo funziona molto velocemente.
- Inoltre, può essere utilizzato per risolvere problemi di previsione di vario tipo, dato che è abbastanza utile con loro.
- Questo classificatore offre prestazioni migliori rispetto ad altri modelli con meno dati di training se viene mantenuta l'ipotesi dell'indipendenza dalle funzionalità.
Contro:
- assume
che tutte le funzioni siano indipendenti. Anche se può suonare benissimo in
teoria, Ma nella vita reale, Nessuno è in grado di trovare un insieme di funzioni indipendenti.
Esempio:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
X, y = load_iris(return_X_y=Vero)
X_treno, X_test, y_train, y_test = train_test_split(X, e, test_size=0.25, random_state=142)
Naive_Bayes = GaussianNB()
Naive_Bayes.fit(X_treno, y_train)
prediction_results = Naive_Bayes.predict(X_test)
Stampa(prediction_results)
Produzione:
Vettore([0, 1, 1, 2, 1, 1, 0, 0, 2, 1, 1, 1, 2, 0, 1, 0, 2, 1, 1, 2, 2, 1,0, 1, 2, 1, 2, 2, 0, 1, 2,
1, 2, 1, 2, 2, 1, 2])
Queste sono le classi previste per i dati X_test dal nostro modello di Bayes ingenuo.
3. Algoritmo K del vicino più prossimo
Devi aver sentito parlare di un detto popolare:
“Dio li risuscita ed essi si riuniscono.”
KNN funziona secondo lo stesso principio. Classifica i nuovi punti dati in base alla classe del maggior numero di punti dati tra il router adiacente K, dove K è il numero di vicini da considerare. KNN cattura l'idea di somiglianza (A volte chiamata distanza,
Prossimità o vicinanza) con alcune formule matematiche di base della distanza come la distanza euclidea, Distanza Manhattan, eccetera.

Fonte: https://www.javatpoint.com
Selezione del valore corretto per K
Per scegliere il K corretto per i dati di cui si vuole eseguire il training, eseguire l'algoritmo KNN più volte con valori K diversi e scegliere il valore K che riduce il numero di errori nei dati non visualizzati.
Professionisti:
- KNN è semplice e facile da implementare.
- Non c'è bisogno di creare un modello, Modificare vari parametri o fare ipotesi aggiuntive come alcuni degli altri algoritmi di classificazione.
- Può essere utilizzato per lo smistamento, Regressione e ricerca. Quindi, È flessibile.
- L'algoritmo diventa significativamente più lento all'aumentare del numero di esempi e / o predittori / variabili indipendenti.
from sklearn.neighbors import KNeighborsClassifier
X_train, X_test, y_train, y_test = train_test_split(X, e, test_size=0.25, random_state=142)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_treno, y_train)
prediction_results = knn.predict(X_test[:5,:)
Stampa(prediction_results)
Produzione:
Vettore([0, 1, 1, 2, 1]) Abbiamo previsto i nostri risultati per 5 Righe di esempio. Da qui l'abbiamo 5 risultati in matrice.
4. SVM
SVM è l'acronimo di Support Vector Machine. Si tratta di un algoritmo di apprendimento automatico supervisionato che viene spesso utilizzato per le sfide di classificazione e regressione. Nonostante questo, utilizzato principalmente nei problemi di classificazione. Il concetto di base della Support Vector Machine e il suo funzionamento possono essere meglio compresi con questo semplice esempio. Quindi, Immagina di avere due etichette: verde e blu, E i nostri dati hanno due caratteristiche: X e e. Vogliamo un classificatore che, dato un paio di (X, e) Coordinate, Partenze se è verde oh blu. Tracciare i dati di training etichettati in un disegno e quindi provare a trovare un disegno (Aumenta l'iperpiano delle dimensioni) che segrega i punti dati di entrambi i colori in modo molto chiaro.

Fonte: https://www.javatpoint.com
Ma questo è il caso dei dati lineari. Ma, Cosa succede se i dati non sono lineari?, Quindi usa il trucco del kernel? Quindi, Per gestire questo problema, Aumentare la dimensione, Questo porta i dati nello spazio e ora i dati diventano linearmente separabili in due gruppi.
Professionisti:
- SVM funziona relativamente bene quando c'è un chiaro margine di separazione tra le classi.
- SVM è più efficace in grandi spazi.
Contro:
- SVM non è adatto per set di dati di grandi dimensioni.
- SVM non funziona molto bene quando il set di dati ha più rumore, In altre parole, Quando le classi target si sovrappongono. Quindi, deve essere gestito.
Esempio:
from sklearn import svm
svm_clf = svm.SVC()
X_treno, X_test, y_train, y_test = train_test_split(X, e, test_size=0.25, random_state=142)
svm_clf.fit(X_treno, y_train)
prediction_results = svm_clf.predict(X_test[:7,:])
Stampa(prediction_results)
Produzione:
Vettore([0, 1, 1, 2, 1, 1, 0])
5.Albero decisionale
L'albero decisionale è uno degli algoritmi di apprendimento automatico più utilizzati. Utilizzato per problemi di classificazione e regressione. Gli alberi decisionali imitano il pensiero a livello umano, Quindi è molto facile capire i dati e fare buone intuizioni e interpretazioni. In realtà, Ti fanno vedere la logica dei dati per interpretarli. Gli alberi decisionali non sono come gli algoritmi black-box come SVM, reti neurali, eccetera.
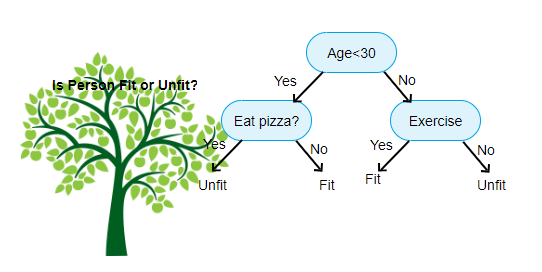
Fonte: https://www.aitimejournal.com
Come esempio, se classifichiamo una persona come idonea o non idonea, L'albero delle decisioni è simile a questo nell'immagine.
Quindi, In sintesi, Un albero decisionale è un albero in cui ogni nodo rappresenta un
caratteristica / attributo, Ogni ramo rappresenta una decisione, un righello e ogni foglio rappresenta un risultato. Questo risultato può essere di valore categorico o continuo. Categorico in caso di classificazione e continuo in caso di applicazioni di regressione.
Professionisti:
- Rispetto ad altri algoritmi, Gli alberi decisionali richiedono meno sforzo per la preparazione dei dati durante la pre-elaborazione.
- Inoltre, non richiedono la normalizzazione o il ridimensionamento dei dati.
- Il modello sviluppato nell'albero decisionale è molto intuitivo e facile da spiegare sia ai team tecnici che agli stakeholder.
Contro:
- Se viene apportata anche una piccola modifica ai dati, Ciò può portare a un grande cambiamento nella struttura dell'albero decisionale che causa instabilità.
- Qualche volta, Il calcolo può essere molto più complesso rispetto ad altri algoritmi.
- Gli alberi decisionali richiedono in genere più tempo per eseguire il training del modello.
Esempio:
from sklearn import tree
dtc = tree.DecisionTreeClassifier()
X_treno, X_test, y_train, y_test = train_test_split(X, e, test_size=0.25, random_state=142)
dtc.fit(X_treno, y_train)
prediction_results = dtc.predict(X_test[:7,:])
Stampa(prediction_results)
Produzione:
Vettore([0, 1, 1, 2, 1, 1, 0])
Note finali
Queste sono le 5 Algoritmi di classificazione più popolari, Ci sono molti altri algoritmi avanzati per l'avvio. Esplorali anche tu. Connettiamoci LinkedIn
Grazie per aver letto se sei arrivato qui 🙂
Il supporto mostrato in questo post non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





