introduzione
Dati e informazioni sul web crescono in modo esponenziale. Oggi, tutti usiamo Google come nostra prima fonte di conoscenza, se trovare recensioni su un luogo per capire un nuovo termine. Tutte queste informazioni sono già disponibili sul web.
Con la quantità di dati disponibili sul web, apre nuovi orizzonti di possibilità per a Scienziato dei dati. Credo fermamente che il web scraping sia un'abilità indispensabile per qualsiasi data scientist.. Nel mondo reale, tutti i dati di cui hai bisogno sono già disponibili su Internet; l'unica cosa che ti impedisce di usarli è la possibilità di accedervi. Con l'aiuto di questo articolo, sarai anche in grado di superare quella barriera.
La maggior parte dei dati disponibili sul web non è disponibile. È presente in un formato non strutturato (formato HTML) e non è possibile scaricare. Perciò, conoscenza ed esperienza sono necessarie per utilizzare questi dati alla fine costruire un modello utile.
In questo articolo, ti guiderò attraverso il processo di web scraping in R. con questo articolo, acquisirai esperienza nell'utilizzo di qualsiasi tipo di dato disponibile su Internet.
Sommario
- Cos'è il web scraping??
- Perché abbiamo bisogno di Web Scraping Scienza dei dati?
- Modi per estrarre i dati
- Prerequisiti
- Raschiare una pagina web usando R
- Analizza i dati estratti dal web
1. Cos'è il web scraping??
Il web scraping è una tecnica per convertire i dati presenti in formato non strutturato (Tag HTML) sul web in un formato strutturato di facile accesso e utilizzo.
Quasi tutte le principali lingue forniscono modi per eseguire lo scraping web. In questo articolo, useremo R per estrarre i dati dei lungometraggi più popolari di 2016 del IMDb sito web.
Otterremo una serie di funzioni per ciascuno dei 100 lungometraggi popolari usciti in 2016. Cosa c'è di più, Esamineremo i problemi più comuni che si potrebbero incontrare durante l'estrazione di dati da Internet a causa dell'incoerenza sul sito Web.. codice e guarda come risolvere questi problemi.
Se ti senti più a tuo agio con Python, Ti consiglierò di leggere questa guida per iniziare con lo scraping web con Python.
2. Perché abbiamo bisogno del web scraping?
Sono sicuro che le prime domande che devono esservi venute in mente ormai lo sono “Perché abbiamo bisogno del web scraping”? Come ho detto prima, le possibilità con il web scraping sono immense.
Per darti una conoscenza pratica, estraiamo i dati da IMDB. Alcune altre possibili applicazioni per le quali è possibile utilizzare lo scraping web sono:
- Estrai i dati sulla valutazione dei film per creare motori di raccomandazione dei film.
- Estrai dati di testo da Wikipedia e altre fonti per creare sistemi basati sulla NLP o addestrare modelli di deep learning per attività come il riconoscimento di argomenti da un determinato testo.
- Estrai dati da immagini taggate da siti web come Google, Flickr, eccetera. per addestrare modelli di classificazione delle immagini.
- Raccolta di dati da siti di social network come Facebook e Twitter per eseguire attività di analisi del sentimento, estrazione di opinioni, eccetera.
- Estrai le recensioni e i commenti degli utenti da siti di e-commerce come Amazon, Flipkart, eccetera.
3. Modi per estrarre i dati
Esistono diversi modi per estrarre i dati dal web. Alcuni dei modi popolari sono:
- Copia e incolla gli esseri umani: Questo è un modo lento ed efficiente per estrarre dati dal web. Ciò comporta l'analisi e la copia dei dati nella memoria locale degli esseri umani stessi.
- Corrispondenza del modello di testo: Un altro approccio semplice ma potente per estrarre informazioni dal web consiste nell'usare le funzioni di corrispondenza delle espressioni regolari dei linguaggi di programmazione.. Puoi saperne di più sulle espressioni regolari qui.
- Interfaccia API: Molti siti web come Facebook, Twitter, LinkedIn, eccetera. fornire API pubbliche e / o privato che può essere chiamato utilizzando il codice standard per recuperare i dati nel formato prescritto.
- Analisi DOM: Utilizzando i browser web, i programmi possono recuperare contenuto dinamico generato da script lato client. È anche possibile analizzare le pagine Web in un albero DOM, a seconda dei programmi che possono recuperare parti di queste pagine.
Useremo l'approccio di analisi DOM nel corso di questo articolo.. E affidati ai selettori CSS della pagina web per trovare i campi pertinenti che contengono le informazioni desiderate. Ma prima di iniziare, ci sono alcuni prerequisiti necessari per estrarre con competenza i dati da qualsiasi sito web.
4. Requisiti precedenti
I prerequisiti per eseguire il web scraping in R si dividono in due gruppi:
- Per iniziare con lo scraping web, deve avere una conoscenza pratica della lingua R. Se hai appena iniziato o vuoi rispolverare le basi, Consiglio vivamente di seguire questo percorso di apprendimento in R. Nel corso di questo articolo, useremo il pacchetto 'rvest’ in R scritto da Hadley Wickham. È possibile accedere alla documentazione del pacchetto rvest qui. Assicurati di aver installato questo pacchetto. Se non hai ancora questo pacchetto, puoi seguire il codice qui sotto per installarlo.
install.packages('rivestimento')
- L'aggiunta di conoscenza di HTML e CSS sarà un ulteriore vantaggio. Una delle migliori fonti che ho trovato per imparare HTML e CSS è è. Ho osservato che la maggior parte dei data scientist non è molto forte con la conoscenza tecnica di HTML e CSS. Perciò, utilizzeremo un software open source chiamato Selector Gadget che sarà più che sufficiente per chiunque possa fare web scraping. Puoi accedere e scaricare l'estensione Selector Gadget qui. Assicurati di aver installato questa estensione seguendo le istruzioni sul sito web. ho fatto lo stesso. Sto utilizzando Google Chrome e posso accedere all'estensione nella barra delle estensioni in alto a destra.
Con questo, puoi selezionare le parti di qualsiasi sito Web e ottenere i tag pertinenti per accedere a quella parte semplicemente facendo clic su quella parte del sito Web. Tieni presente che questo è un modo per imparare HTML e CSS e farlo manualmente. Ma per padroneggiare l'arte del web scraping, Consiglio vivamente di imparare HTML e CSS per capire e apprezzare meglio ciò che sta accadendo sotto il cofano.
4. Raschiatura di una pagina Web con R
Ora, iniziamo a cercare sul sito IMDb per 100 lungometraggi più popolari usciti su 2016. Puoi accedervi qui.
#Loading the rvest package library('rivestimento') #Specifying the url for desired website to be scraped url <- 'http://www.imdb.com/search/title?conteggio=100&release_date=2016,2016&title_type=feature' #Reading the HTML code from the website webpage <- read_html(URL)
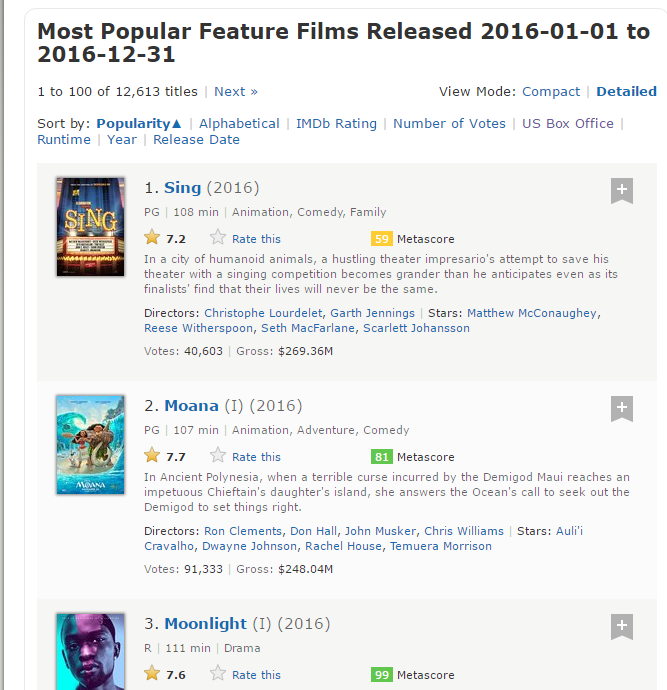
Ora, estrarremo i seguenti dati da questo sito web.
- Classifica: La gamma del film di 1 un 100 nell'elenco di 100 film più popolari usciti il 2016.
- Titolo: Il titolo del lungometraggio.
- Descrizione: La descrizione del lungometraggio.
- Runtime: La lunghezza del lungometraggio.
- Genere: Il genere del lungometraggio,
- Classificazione: La valutazione IMDb del lungometraggio.
- Metapunteggio: Il metascore sul sito web di IMDb per il lungometraggio.
- Voti: Voti espressi a favore del lungometraggio.
- Entrate_lorde_in_migliaia: Guadagni lordi in milioni di lungometraggi.
- Direttore: Il regista principale del lungometraggio. Notare che, nel caso di più amministratori, Prenderò solo il primo.
- Attore: L'attore principale del film. Notare che, nel caso di più attori, Prenderò solo il primo.
Ecco uno screenshot contenente come sono organizzati tutti questi campi.
passo 1: Ora, inizieremo raschiando il campo Range. Per quello, utilizzeremo il gadget selettore per ottenere i selettori CSS specifici che racchiudono le valutazioni. Puoi fare clic sull'estensione nel tuo browser e selezionare il campo di ordinamento con il cursore.
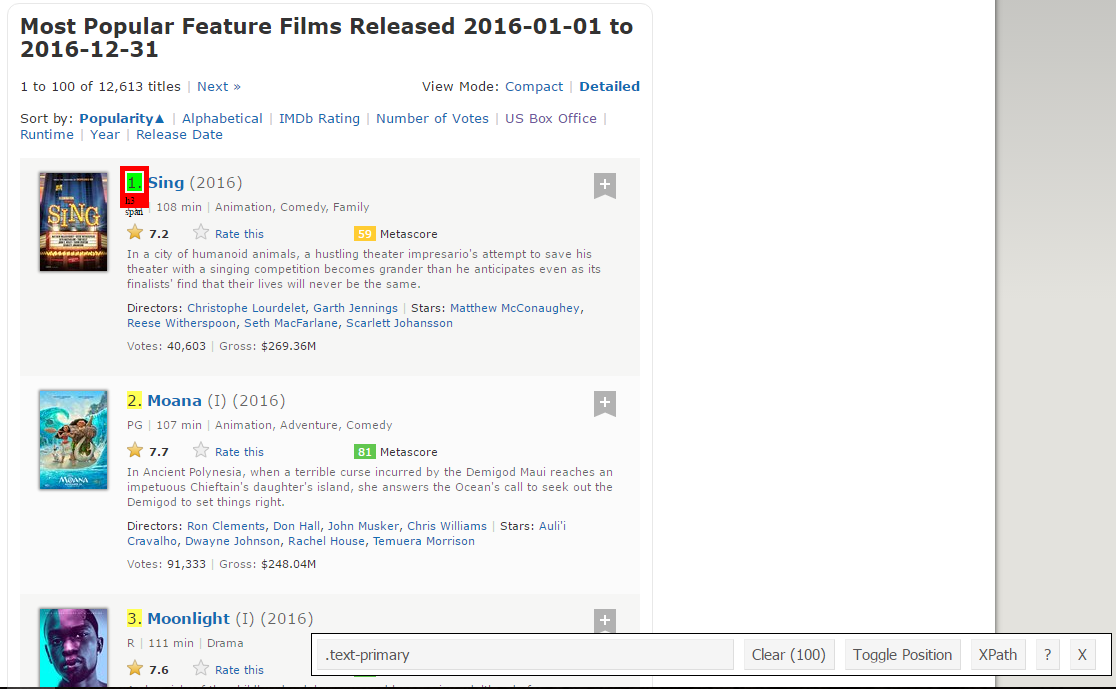
Assicurati che tutte le valutazioni siano selezionate. Puoi selezionare alcune altre sezioni di classificazione nel caso in cui non riesci a ottenerle tutte e puoi anche deselezionarle facendo clic sulla sezione selezionata per assicurarti di avere solo le sezioni evidenziate che desideri raschiare entro quel momento.. .
passo 2: Una volta che sei sicuro di aver effettuato le selezioni corrette, È necessario copiare il selettore CSS corrispondente che è possibile visualizzare in basso al centro.
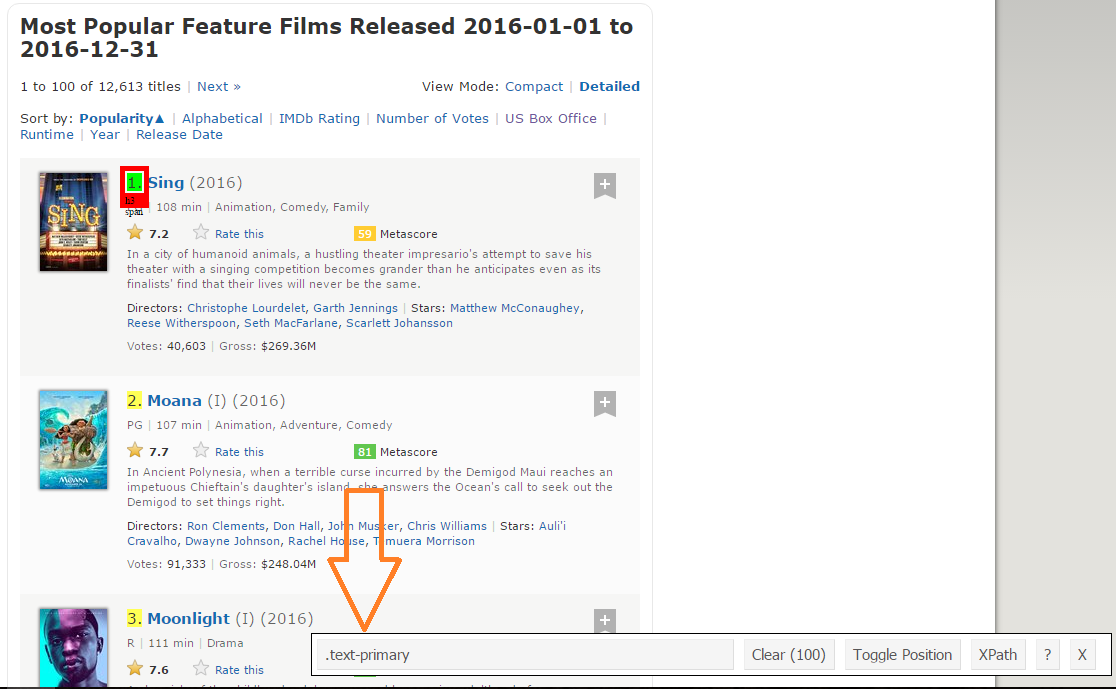
passo 3: Una volta che conosci il selettore CSS che contiene le classificazioni, è possibile utilizzare questo semplice codice R per ottenere tutte le valutazioni:
#Using CSS selectors to scrape the rankings section rank_data_html <- html_nodes(Sito web,'.text-primary') #Converting the ranking data to text rank_data <- html_text(rank_data_html) #Let's have a look at the rankings head(rank_data) [1] "1." "2." "3." "4." "5." "6."
passo 4: Una volta che hai i dati, assicurarsi che siano visualizzati nel formato desiderato. Sto pre-elaborando i miei dati per convertirli in formato numerico.
#Pre-elaborazione dei dati: Converting rankings to numerical rank_data<-as.numeric(rank_data) #Let's have another look at the rankings head(rank_data) [1] 1 2 3 4 5 6
passo 5: Ora puoi cancellare la sezione del selettore e selezionare tutti i titoli. È possibile verificare visivamente che tutti i titoli siano selezionati. Fai le aggiunte e le eliminazioni necessarie con l'aiuto del tuo cursore. Ho fatto la stessa cosa qui.
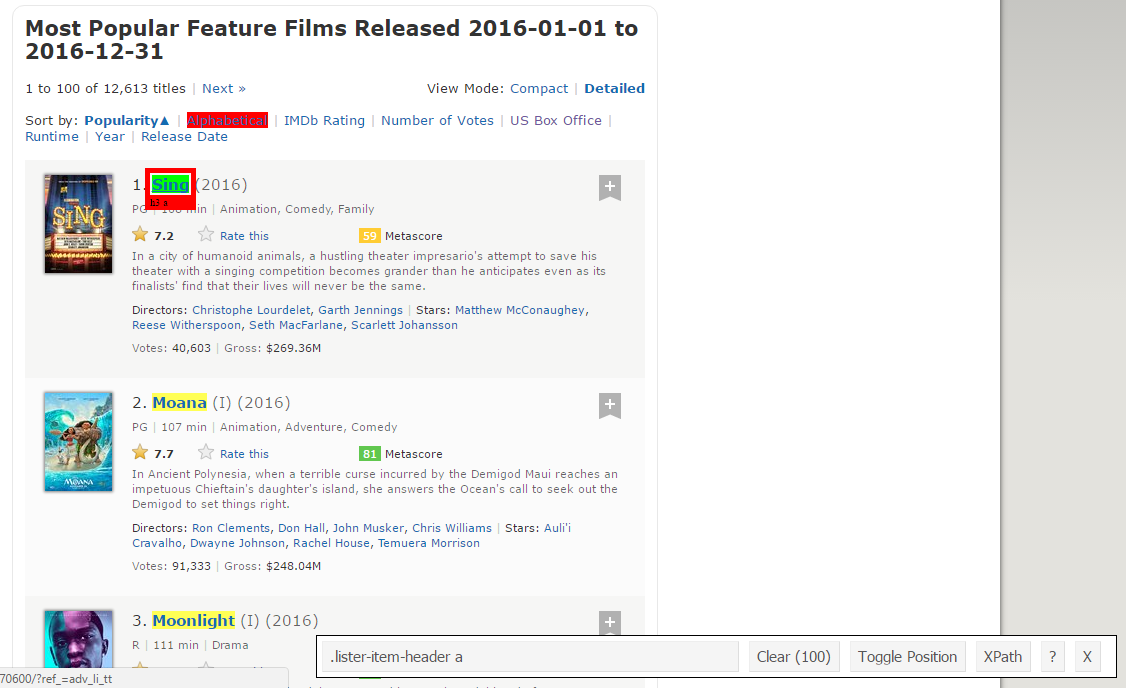
passo 6: Ancora, Ho il selettore CSS corrispondente per i titoli: .lister-item-header a. Usaré este selector para raspar todos los títulos usando el siguiente código.
#Using CSS selectors to scrape the title section title_data_html <- html_nodes(Sito web,'.lister-item-header a') #Converting the title data to text title_data <- html_text(title_data_html) #Let's have a look at the title head(title_data) [1] "Cantare" "Gianluca" "Chiaro di luna" "Hacksaw Ridge" [5] "Passeggeri" "Troll"
passo 7: Nel seguente codice, he hecho lo mismo para el raspado: descripción, tempo di esecuzione, Genere, qualificazione, metapuntuacion, voti, ingresos brutos en mil, datos de director y actor.
#Using CSS selectors to scrape the description section description_data_html <- html_nodes(Sito web,'.ratings-bar+ .text-muted') #Converting the description data to text description_data <- html_text(description_data_html) #Let's have a look at the description data head(description_data) [1] "nIn una città di animali umanoidi, il tentativo di un frenetico impresario teatrale di salvare il suo teatro con un concorso di canto diventa più grandioso di quanto si aspetta, anche se i finalisti scoprono che le loro vite non saranno più le stesse." [2] "nNell'antica Polinesia, quando una terribile maledizione incorsa dal semidio Maui raggiunge l'isola della figlia di un capotribù impetuoso, risponde alla chiamata dell'Oceano per cercare il Semidio per sistemare le cose." [3] "nUna cronaca dell'infanzia, l'adolescenza e la nascente età adulta di un giovane, Afroamericano, uomo gay cresciuto in un quartiere duro di Miami." [4] "Il medico dell'esercito americano della seconda guerra mondiale Desmond T. dormire, che prestò servizio durante la battaglia di Okinawa, rifiuta di uccidere le persone, e diventa il primo uomo nella storia americana a ricevere la Medal of Honor senza sparare un colpo." [5] "Un veicolo spaziale nA che viaggia su un lontano pianeta colonia e trasporta migliaia di persone ha un malfunzionamento nelle sue camere di sonno. Di conseguenza, due passeggeri vengono svegliati 90 anni prima." [6] "nDopo che i Bergen invadono troll Village, Papavero, il Troll più felice mai nato, e il ramo curmudgeonly partì per un viaggio per salvare i suoi amici. #Pre-elaborazione dei dati: removing 'n' description_data<-gsub("n","",description_data) #Let's have another look at the description data head(description_data) [1] "In una città di animali umanoidi, il tentativo di un frenetico impresario teatrale di salvare il suo teatro con un concorso di canto diventa più grandioso di quanto si aspetta, anche se i finalisti scoprono che le loro vite non saranno più le stesse." [2] "Nell'antica Polinesia, quando una terribile maledizione incorsa dal semidio Maui raggiunge l'isola della figlia di un capotribù impetuoso, risponde alla chiamata dell'Oceano per cercare il Semidio per sistemare le cose." [3] "Una cronaca dell'infanzia, l'adolescenza e la nascente età adulta di un giovane, Afroamericano, uomo gay cresciuto in un quartiere duro di Miami." [4] "Medico dell'esercito americano della seconda guerra mondiale Desmond T. dormire, che prestò servizio durante la battaglia di Okinawa, rifiuta di uccidere le persone, e diventa il primo uomo nella storia americana a ricevere la Medal of Honor senza sparare un colpo." [5] "Un veicolo spaziale che viaggia su un lontano pianeta colonia e trasporta migliaia di persone ha un malfunzionamento nelle sue camere di sonno. Di conseguenza, due passeggeri vengono svegliati 90 anni prima." [6] "Dopo che i Bergen invadono troll village, Papavero, il Troll più felice mai nato, e la curmudgeonly Branch partì per un viaggio per salvare i suoi amici." #Using CSS selectors to scrape the Movie runtime section runtime_data_html <- html_nodes(Sito web,'.text-muted .runtime') #Converting the runtime data to text runtime_data <- html_text(runtime_data_html) #Let's have a look at the runtime head(runtime_data) [1] "108 min" "107 min" "111 min" "139 min" "116 min" "92 min" #Pre-elaborazione dei dati: removing mins and converting it to numerical runtime_data<-gsub(" min","",runtime_data) runtime_data<-as.numeric(runtime_data) #Let's have another look at the runtime data head(runtime_data) [1] 1 2 3 4 5 6 #Using CSS selectors to scrape the Movie genre section genre_data_html <- html_nodes(Sito web,'.genere') #Converting the genre data to text genre_data <- html_text(genre_data_html) #Let's have a look at the runtime head(genre_data) [1] "nAnimazione, Commedia, Famiglia " [2] "nAnimazione, Avventura, Commedia " [3] "nDrama " [4] "nBiografia, Dramma, Storia " [5] "nAvventura, Dramma, Romanzo " [6] "nAnimazione, Avventura, Commedia " #Pre-elaborazione dei dati: removing n genre_data<-gsub("n","",genre_data) #Pre-elaborazione dei dati: removing excess spaces genre_data<-gsub(" ","",genre_data) #taking only the first genre of each movie genre_data<-gsub(",.*","",genre_data) #Convering each genre from text to factor genre_data<-come.fattore(genre_data) #Let's have another look at the genre data head(genre_data) [1] Animazione Animazione Drammatico Biografia Avventura Animazione 10 Livelli: Azione Avventura Animazione Biografia Commedia Crimine Drammatico ... Thriller #Using CSS selectors to scrape the IMDB rating section rating_data_html <- html_nodes(Sito web,'.ratings-imdb-rating forte') #Converting the ratings data to text rating_data <- html_text(rating_data_html) #Let's have a look at the ratings head(rating_data) [1] "7.2" "7.7" "7.6" "8.2" "7.0" "6.5" #Pre-elaborazione dei dati: converting ratings to numerical rating_data<-as.numeric(rating_data) #Let's have another look at the ratings data head(rating_data) [1] 7.2 7.7 7.6 8.2 7.0 6.5 #Using CSS selectors to scrape the votes section votes_data_html <- html_nodes(Sito web,'.sort-num_votes-visible span:ennesimo bambino(2)') #Converting the votes data to text votes_data <- html_text(votes_data_html) #Let's have a look at the votes data head(votes_data) [1] "40,603" "91,333" "112,609" "177,229" "148,467" "32,497" #Pre-elaborazione dei dati: removing commas votes_data<-gsub(",","",votes_data) #Pre-elaborazione dei dati: converting votes to numerical votes_data<-as.numeric(votes_data) #Let's have another look at the votes data head(votes_data) [1] 40603 91333 112609 177229 148467 32497 #Using CSS selectors to scrape the directors section directors_data_html <- html_nodes(Sito web,'.text-muted+ p a:ennesimo bambino(1)') #Converting the directors data to text directors_data <- html_text(directors_data_html) #Let's have a look at the directors data head(directors_data) [1] "Christophe Lourdelet" "Ron Clements" "Barry Jenkins" [4] "Mel Gibson" "Morten Tyldum" "Walt Dohrn" #Pre-elaborazione dei dati: converting directors data into factors directors_data<-come.fattore(directors_data) #Using CSS selectors to scrape the actors section actors_data_html <- html_nodes(Sito web,'.lister-item-content .ghost+ a') #Converting the gross actors data to text actors_data <- html_text(actors_data_html) #Let's have a look at the actors data head(actors_data) [1] "Matthew McConaughey" "Auli'i Cravalho" "Mahershala Ali" [4] "Andrew Garfield" "Jennifer Lawrence" "Anna Kendrick" #Pre-elaborazione dei dati: converting actors data into factors actors_data<-come.fattore(actors_data)
Pero quiero que siga de cerca lo que sucede cuando hago lo mismo con los datos de Metascore.
#Using CSS selectors to scrape the metascore section metascore_data_html <- html_nodes(Sito web,'.metascore') #Converting the runtime data to text metascore_data <- html_text(metascore_data_html) #Let's have a look at the metascore data head(metascore_data) [1] "59 " "81 " "99 " "71 " "41 " [6] "56 " #Pre-elaborazione dei dati: removing extra space in metascore metascore_data<-gsub(" ","",metascore_data) #Lets check the length of metascore data length(metascore_data) [1] 96
passo 8: La lunghezza dei dati del metascore è 96 mentre stiamo raschiando i dati di 100 pellicole. Il motivo per cui questo è successo è che c'è 4 film che non hanno i campi Metascore corrispondenti.
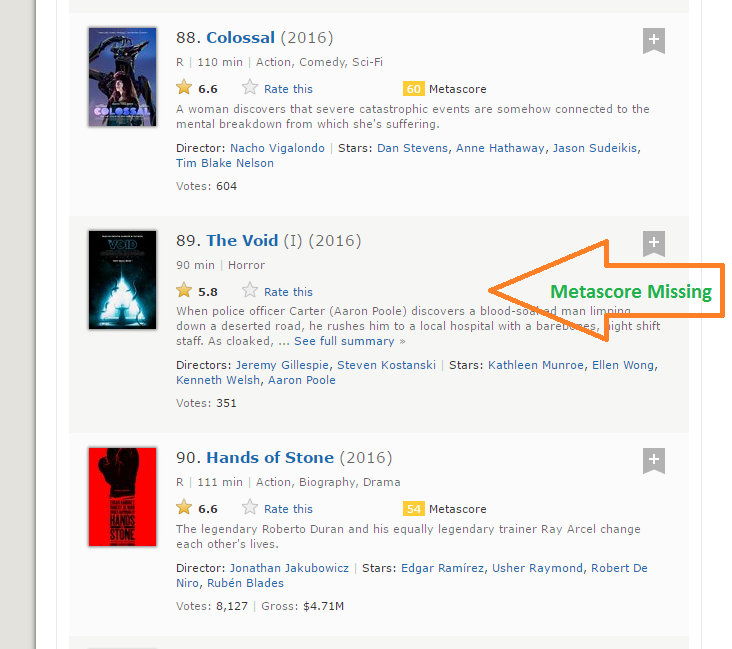
passo 9: È una situazione pratica che può sorgere quando si raschia qualsiasi sito Web. Sfortunatamente, se aggiungiamo semplicemente NA all'ultimo 4 Biglietti, NA verrà assegnato come Metascore per i film 96 un 100, mentre in realtà, dati mancanti per alcuni altri film. Dopo un'ispezione visiva, Ho scoperto che mancava il metascore per i film 39, 73, 80 e 89. Escribí la siguiente función para solucionar este problema.
per (i in c(39,73,80,89)){
un<-metascore_data[1:(i-1)]
B<-metascore_data[io:lunghezza(metascore_data)]
metascore_data<-aggiungere(un,elenco("N / A"))
metascore_data<-aggiungere(metascore_data,B)
}
#Pre-elaborazione dei dati: converting metascore to numerical
metascore_data<-as.numeric(metascore_data)
#Let's have another look at length of the metascore data
length(metascore_data)
[1] 100
#Let's look at summary statistics
summary(metascore_data)
Min. 1st Qu. Mediana Media 3° Qu. Max. NA
23.00 47.00 60.00 60.22 74.00 99.00 4
passo 10: Lo mismo sucede con la variable Bruto que representa los ingresos brutos de esa película en millones. He usado la misma solución para trabajar a mi manera:
#Using CSS selectors to scrape the gross revenue section gross_data_html <- html_nodes(Sito web,'.ghost~ .text-muted+ span') #Converting the gross revenue data to text gross_data <- html_text(gross_data_html) #Let's have a look at the votes data head(gross_data) [1] "$269.36m" "$248.04m" "$27.50m" "$67.12m" "$99.47m" "$153.67m" #Pre-elaborazione dei dati: removing '$' and 'M' signs gross_data<-gsub("m","",gross_data) gross_data<-Sottostringa(gross_data,2,6) #Let's check the length of gross data length(gross_data) [1] 86 #Filling missing entries with NA for (i in c(17,39,49,52,57,64,66,73,76,77,80,87,88,89)){ un<-gross_data[1:(i-1)] B<-gross_data[io:lunghezza(gross_data)] gross_data<-aggiungere(un,elenco("N / A")) gross_data<-aggiungere(gross_data,B) } #Pre-elaborazione dei dati: converting gross to numerical gross_data<-as.numeric(gross_data) #Let's have another look at the length of gross data length(gross_data) [1] 100 riepilogo(gross_data) Min. 1st Qu. Mediana Media 3° Qu. Max. NA 0.08 15.52 54.69 96.91 119.50 530.70 14
passo 11: Ahora hemos eliminado con éxito las 11 funciones de las | 100 film più popolari usciti il 2016. Combinémoslas para crear un marco de datos e inspeccionar su estructura.
#Combining all the lists to form a data frame movies_df<-data.frame(Rango = rank_data, Titolo = title_data, Descrizione = description_data, Runtime = runtime_data, Genere = genre_data, Valutazione = rating_data, Metascore = metascore_data, Voti = votes_data, Gross_Earning_in_Mil = gross_data, Regista = directors_data, Attore = actors_data) #Structure of the data frame str(movies_df) 'data.frame': 100 Ob. di 11 variabili: $ Classifica : nessuno 1 2 3 4 5 6 7 8 9 10 ... $ Titolo : Fattore w/ 99 Livelli "10 Cloverfield Lane",..: 66 53 54 32 58 93 8 43 97 7 ... $ Descrizione : Fattore w/ 100 Livelli "19-Billy Lynn, un anno, viene riportato a casa per un tour della vittoria dopo una straziante battaglia in Iraq. Attraverso flashback il film mostra cosa"| __truncated__,..: 57 59 3 100 21 33 90 14 13 97 ... $ Tempo di esecuzione : nessuno 108 107 111 139 116 92 115 128 111 116 ... $ Genere : Fattore w/ 10 Livelli "Azione","Avventura",..: 3 3 7 4 2 3 1 5 5 7 ... $ Valutazione : nessuno 7.2 7.7 7.6 8.2 7 6.5 6.1 8.4 6.3 8 ... $ Metapunteggio : nessuno 59 81 99 71 41 56 36 93 39 81 ... $ Voti : nessuno 40603 91333 112609 177229 148467 ... $ Gross_Earning_in_Mil: nessuno 269.3 248 27.5 67.1 99.5 ... $ Direttore : Fattore w/ 98 Livelli "Andrew Stanton",..: 17 80 9 64 67 95 56 19 49 28 ... $ Attore : Fattore w/ 86 Livelli "Aaron Eckhart",..: 59 7 56 5 42 6 64 71 86 3 ...
Ora hai raschiato con successo il sito web di IMDb per il 100 lungometraggi più popolari usciti su 2016.
6. Analizza i dati estratti dal Web
Una volta che hai i dati, può eseguire varie attività come l'analisi dei dati, fare inferenze da loro, addestrare modelli di apprendimento automatico su questi dati, eccetera. Ho continuato a creare una visualizzazione interessante dai dati appena estratti. Segui le visualizzazioni e rispondi alle domande riportate di seguito. Pubblica le tue risposte nella sezione commenti qui sotto.
biblioteca('ggplot2')
qplot(dati = film_df,Tempo di esecuzione,riempimento = genere,bidoni = 30)
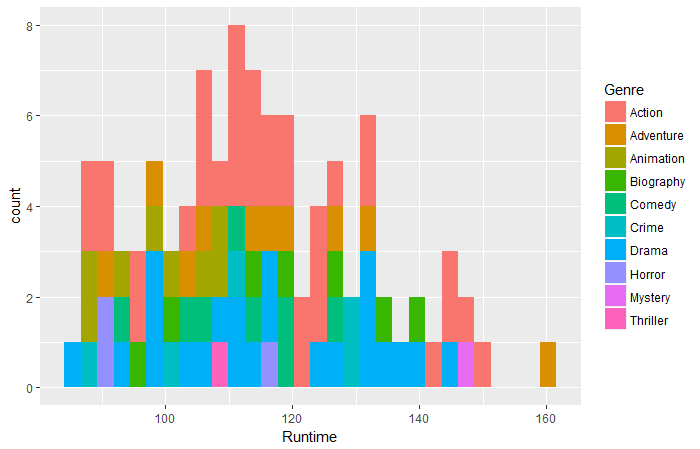
Domanda 1: Secondo i dati di cui sopra, quale film di quale genere ha avuto la durata più lunga?
ggplot(movies_df,aes(x=Durata,y=Valutazione))+ geom_point(aes(dimensione=Voti,col=Sesso))
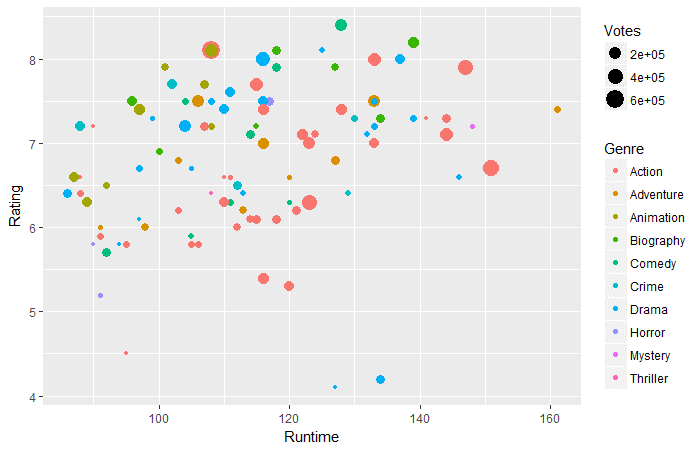
Domanda 2: Secondo i dati di cui sopra, in fase di esecuzione 130-160 minuti, quale genere ha i voti più alti?
ggplot(movies_df,aes(x=Durata,y=Guadagno_lordo_in_milioni))+ geom_point(aes(taglia=Valutazione,col=Sesso))
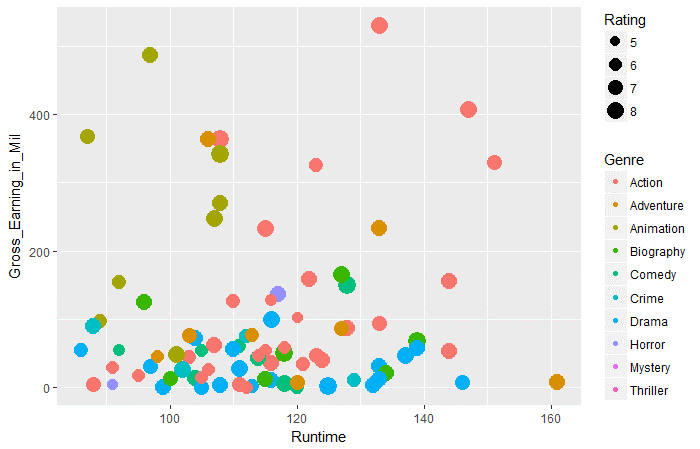
Domanda 3: Secondo i dati di cui sopra, in tutti i generi, quale genere ha i guadagni lordi medi più alti in fase di esecuzione di 100 un 120.
Note finali
Penso che questo articolo ti avrebbe dato una comprensione completa del web scraping in R. Ora, hai anche un'idea chiara dei problemi che potresti incontrare e di come risolverli. Poiché la maggior parte dei dati sul Web è presente in un formato non strutturato, il web scraping è un'abilità molto utile per qualsiasi data scientist.
Cosa c'è di più, puoi pubblicare le risposte alle tre domande precedenti nella sezione commenti qui sotto. Ti è piaciuto leggere questo articolo? Condividi le tue opinioni con me. Se hai dei dubbi / domanda, sentiti libero di inviarlo di seguito.





