introduzione
Repository GitHub e discussioni su Reddit: entrambe le piattaforme hanno giocato un ruolo chiave nel mio apprendimento automatico viaggio. Mi hanno aiutato a sviluppare la mia conoscenza e comprensione delle tecniche di apprendimento automatico e il mio acume negli affari.
Sia GitHub che Reddit mi tengono aggiornato sugli ultimi sviluppi nell'apprendimento automatico, Un must per chi lavora in questo campo!!
E se sei un programmatore, bene, GitHub è come un tempio per te. Puoi facilmente scaricare il codice e replicarlo sulla tua macchina. Ciò rende ancora più facile apprendere nuove idee e costruire un set di abilità diversificato..

Sono lieto di scegliere i migliori repository GitHub e le discussioni Reddit di questo mese. I thread di Reddit che ho presentato riguardano sia il lato tecnico di apprendimento automatico così come quello relativo alla gara. Questa capacità di combinare i due è ciò che separa gli esperti di machine learning dagli hobbisti..
Di seguito sono riportati gli articoli mensili che abbiamo trattato finora in questa serie:
Così, Mettiamoci al lavoro per marzo!
Repository GitHub

Se dovessi scegliere uno dei motivi della mia passione per visione computerizzata, sarebbero i GAN (Reti generative avversarie). Sono stati inventati da Ian Goodfellow solo pochi anni fa e sono diventati un intero corpo di ricerca.. L'arte dell'IA recente che hai visto nelle notizie? Tutto funziona con GAN.

DeepMind ha ideato il concetto BigGAN l'anno scorso, ma abbiamo aspettato un po' per un'implementazione di PyTorch. Questo repository include anche modelli precedentemente addestrati (128 × 128, 256 × 256 e 512 × 512). Puoi installarlo in una sola riga di codice:
pip install pytorch-pretrained-biggan
E se sei interessato a leggere l'intero articolo di ricerca BigGAN, visitare qui.
La capacità di lavorare con i dati delle immagini sta diventando un tratto distintivo per chiunque sia interessato a apprendimento profondo. L'avvento e il rapido sviluppo degli algoritmi di visione artificiale hanno svolto un ruolo importante in questa trasformazione.. Non sarai sorpreso di apprendere che NVIDIA è uno dei principali leader in questo settore..
Dai un'occhiata ai loro sviluppi da 2018:
E adesso, i ragazzi di NVIDIA hanno creato un'altra fantastica versione: la capacità di sintetizzare immagini fotorealistiche con un design semantico di input. Quanto è buono? Il seguente confronto fornisce una buona illustrazione:

SPADE ha superato i metodi esistenti nel popolare set di dati COCO. Il repository che abbiamo collegato sopra ospiterà l'implementazione di PyTorch e i modelli precedentemente addestrati per questa tecnica (assicurati di aggiungerlo ai segnalibri).
Questo video mostra come funziona SPADE in 40.000 immagini prese da Flickr:
Questo repository è basato sul ‘Tracciamento e segmentazione degli oggetti online veloci: un approccio unificante‘ carta. Ecco un esempio di risultato utilizzando questa tecnica:

Degno di nota! La tecnica, chiamato SiamMask, è abbastanza semplice, versatile ed estremamente veloce. Oh, Ho già detto che il tracciamento degli oggetti viene eseguito in tempo reale?? Questo ha sicuramente attirato la mia attenzione. Questo repository contiene anche modelli pre-addestrati in modo da poter iniziare.
Il lavoro sarà presentato al prestigioso convegno CVPR 2019 (Visione artificiale e riconoscimento di schemi) nel mese di giugno. Gli autori hanno dimostrato il loro approccio nel seguente video:
Hai mai lavorato a un progetto di rilevamento della posa?? L'ho fatto e lascia che ti dica che è eccellente. È una testimonianza dei progressi che abbiamo fatto come comunità nell'apprendimento profondo.. Chi l'avrebbe detto fa 10 anni in cui saremmo in grado di prevedere il prossimo movimento del corpo di una persona?
Questo repository GitHub è un PyTorch implementazione di ‘Apprendimento auto-supervisionato della posa umana 3D utilizzando la geometria multi-vista‘ carta. Gli autori hanno sperimentato una nuova tecnica chiamata EpipolarePose, un metodo di apprendimento auto-supervisionato per stimare la posa di un essere umano in 3D.

La tecnica EpipolarPose stima le pose 2D da immagini multi-vista durante la fase di allenamento. Quindi usa la geometria epipolare per generare una posa 3D. Questo, allo stesso tempo, utilizzato per addestrare lo stimatore di posa 3D. Questo processo è illustrato nell'immagine sopra.
Questo articolo è stato accettato anche alla conferenza CVPR 2019. Si preannuncia essere una formazione eccellente!!
Questo è un repository unico in molti modi. È un modello di deep learning open source per proteggere la tua privacy. L'intero concetto di DeepCamera si basa sull'apprendimento automatico delle macchine (AutoML). Perciò, non hai nemmeno bisogno di esperienza di programmazione per addestrare un nuovo modello.

DeepCamera funziona su dispositivi Android. Puoi anche integrare il codice con le telecamere di sorveglianza. C'è MOLTO che puoi fare con il codice DeepCamera, cosa include?:
- Riconoscimento facciale
- Riconoscimento facciale
- Controllo dall'applicazione mobile
- Rilevamento di oggetti
- Rilevamento del movimento
E tante altre cose. Costruire il tuo modello basato sull'intelligenza artificiale non è mai stato così facile!!
Discussioni su Reddit

Ho diviso le discussioni su Reddit di questo mese in due categorie:
- Il lato tecnico del machine learning
- Discussioni relative alla carriera di machine learning (ruoli e lavori)
Partiamo dall'aspetto tecnico.
Gli scienziati dei dati sono affascinati dal lavoro di ricerca. Vogliamo leggerli, codificateli e magari scrivetene uno da zero. Quanto sarebbe bello presentare il tuo documento di ricerca a una conferenza ML di alto livello??

Appartengo sicuramente alla categoria dei “Voglio scrivere un articolo di ricerca”. Questa discussione, iniziato da un ricercatore veterano, approfondisce le migliori pratiche che dovremmo seguire quando scriviamo un articolo di ricerca. Qui ci sono molte informazioni ed esperienze, Da leggere per tutti noi!
Ecco il Archivio GitHub con i migliori consigli, consigli e idee in un unico posto. Tratta questi suggerimenti come una serie di linee guida e non come regole scolpite nella pietra.
Come metti in produzione i tuoi modelli di machine learning addestrati?? Come li implementi?? Queste sono domande MOLTO comuni che dovrai affrontare nel tuo colloquio di data science (E lavoro, Certo). Se non sei sicuro di cosa si tratta, Ti consiglio di leggerlo ORA.
Questo thread di discussione riguarda una libreria open source che converte i tuoi modelli di machine learning in codice nativo (C, Pitone, Giava) nessuna dipendenza. Deve scorrere il thread, poiché ci sono alcune domande comuni che l'autore ha affrontato in dettaglio.
Puoi trovare il codice completo su questo repository GitHub. Di seguito è riportato l'elenco dei modelli attualmente supportati da questa libreria:
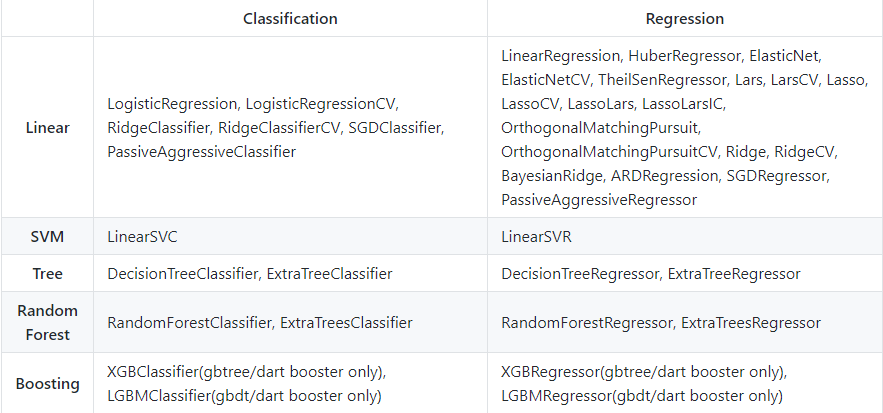
Spostiamo ora l'attenzione e vediamo alcune discussioni sulla carriera nell'apprendimento automatico. Questi sono applicabili a TUTTI i professionisti dell'apprendimento automatico, sia aspiranti che affermati.
L'emergere del machine learning automatizzato sarà uno svantaggio per il settore stesso?? Questa è una domanda che molti di noi si sono posti.. La maggior parte degli articoli che incontro prevedono tutto il pessimismo. Alcuni sostengono addirittura che i data scientist non saranno necessari in 5 anni!

Fonte: temocrazia
L'autore di questo thread fa un meraviglioso argomento contro il consenso generale. È altamente improbabile che la scienza dei dati scompaia a causa dell'automazione.
La discussione giustamente sostiene che la scienza dei dati non riguarda solo la modellazione dei dati. Questo è solo il 10% dell'intero processo. Una parte importante del ciclo di vita della scienza dei dati è l'intuizione umana dietro i modelli. Pulizia dei dati, la visualizzazione dei dati e un tocco di logica sono ciò che guida l'intero processo.
Ecco una gemma e un argomento solido che ha attirato la mia attenzione:
Sviluppiamo tutti i tipi di software di statistica nell'ultimo secolo e, tuttavia, non ha sostituito gli statistici.
Vuoi ottenere la tua prima posizione nella scienza dei dati?? Lo trovi un processo travolgente?? ci sono stato. È uno dei maggiori ostacoli da superare nei nostri rispettivi viaggi nella scienza dei dati..
Quindi volevo evidenziare questo thread in particolare. È una discussione davvero illuminante, dove professionisti e principianti della scienza dei dati discutono su come entrare in questo campo. L'autore del post offre alcune riflessioni approfondite sul processo di ricerca di lavoro nella scienza dei dati insieme a suggerimenti per l'eliminazione di ogni round di interviste..

Una frase che si è distinta davvero in questa discussione:
Ricordare, l'aumento delle richieste di colloquio e l'aumento della conoscenza non è solo una correlazione, è una causalità. Durante l'applicazione, impara qualcosa di nuovo ogni giorno.
Un DataPeaker, il nostro obiettivo è aiutarti ad ottenere la tua prima posizione nella scienza dei dati. Dai un'occhiata alle fantastiche risorse qui sotto per aiutarti a iniziare:
Conoscenza del dominio: quell'ingrediente chiave nella ricetta generale del data scientist. Spesso, gli aspiranti scienziati dei dati lo trascurano o lo interpretano male. E questo spesso si traduce in rifiuti nelle interviste.. Quindi, Come puoi sviluppare il tuo senso degli affari per integrare le tue competenze esistenti nella scienza dei dati tecnici??
Questa discussione su Reddit offre alcuni spunti utili. La capacità di tradurre le tue idee e i tuoi risultati in termini commerciali è VITALE. La maggior parte delle parti interessate che affronterai nella tua carriera non capiranno il gergo tecnico..
Ecco la mia scelta preferita dalla discussione:
Hai bisogno di conoscere meglio i tuoi partner commerciali. Scopri cosa fanno ogni giorno, quali sono i tuoi processi, come generano i dati che utilizzerai. Se capisci come vedono X e Y, sarai in grado di aiutarli meglio quando verranno da te con problemi.
In DataPeaker crediamo fortemente nella costruzione di una mentalità di pensiero strutturata. Abbiamo raccolto la nostra esperienza e conoscenza su questo argomento nel corso completo di seguito:
Questo corso contiene diversi casi di studio che ti aiuteranno anche a farti un'idea di come lavorano e pensano le aziende..
Note finali
Mi sono piaciute particolarmente le discussioni su Reddit del mese scorso. Ti esorto a saperne di più su come funziona l'ambiente di produzione in un progetto di machine learning. Ora considerato quasi obbligatorio per uno scienziato dei dati, quindi non puoi allontanarti da lui.
Dovresti anche partecipare a queste discussioni su Reddit. Lo scorrimento passivo è utile per acquisire conoscenze, ma aggiungere il tuo punto di vista aiuterà anche gli altri candidati. Questa è una sensazione intangibile, ma apprezzerai e apprezzerai più esperienza che ottieni.
Quale discussione hai trovato più rivelatrice? E quale repository GitHub si è distinto per te? Fatemi sapere nella sezione commenti qui sotto!!





